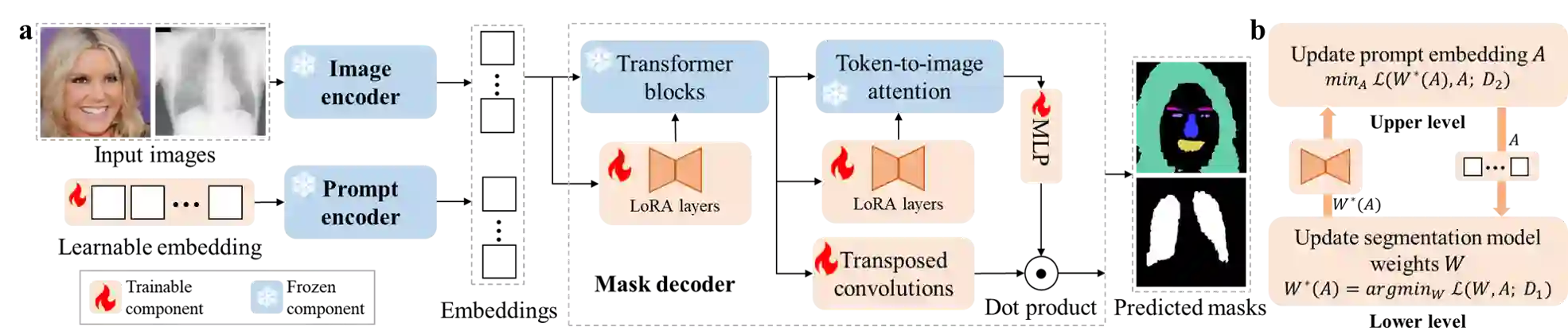
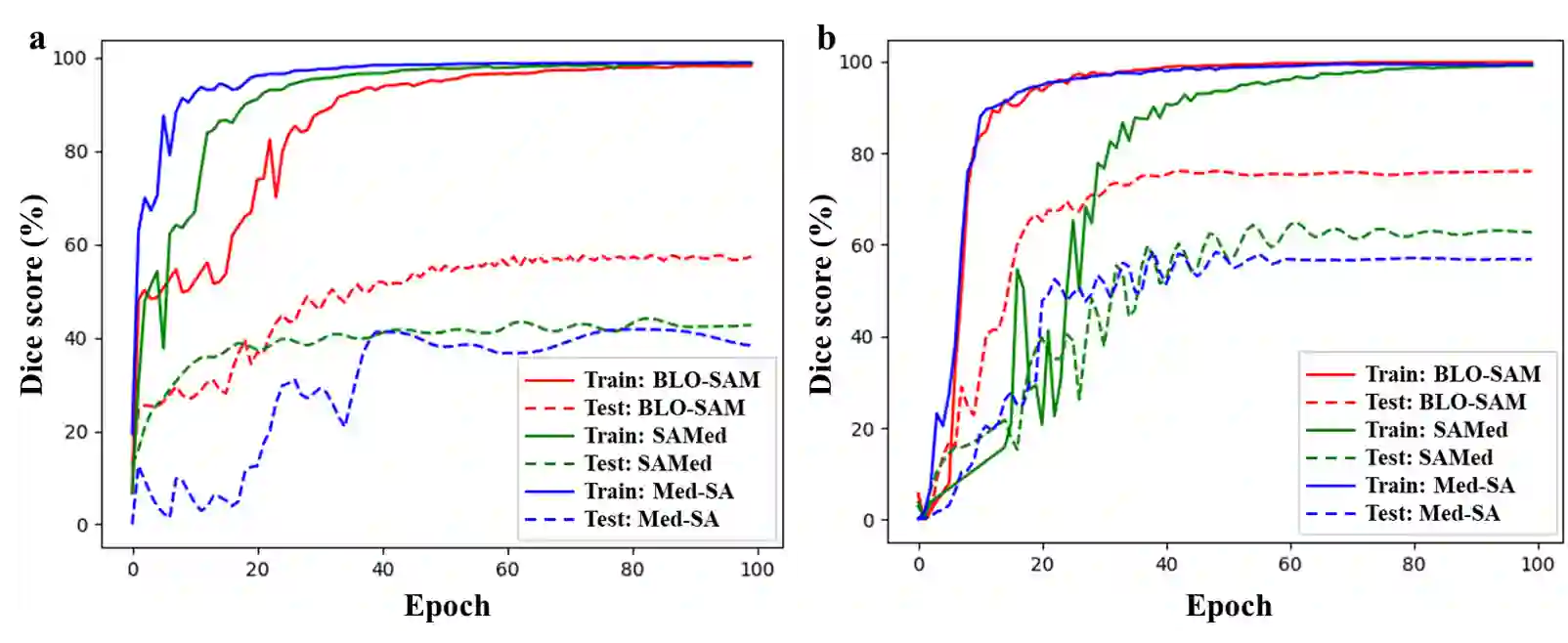
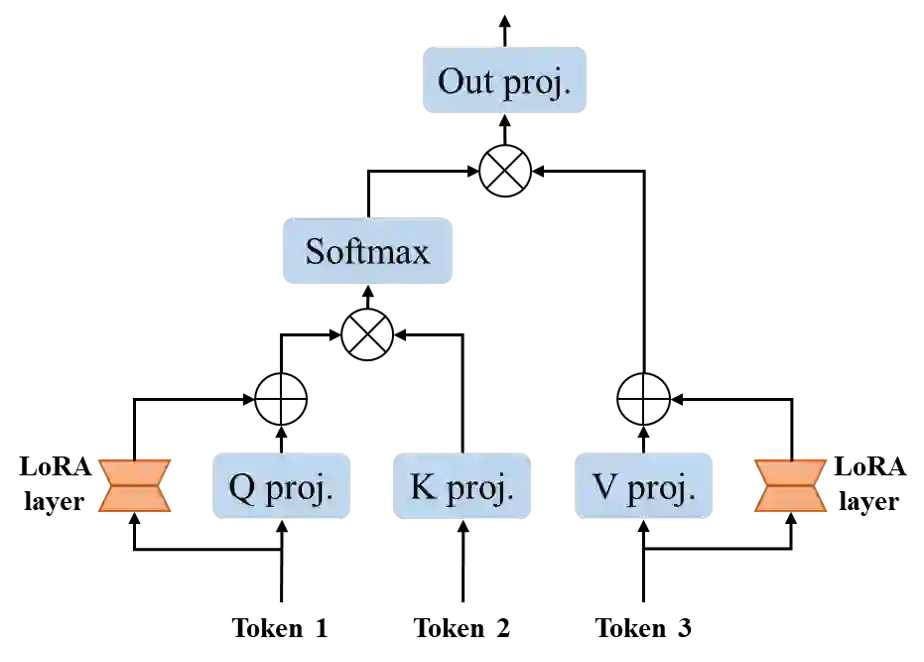
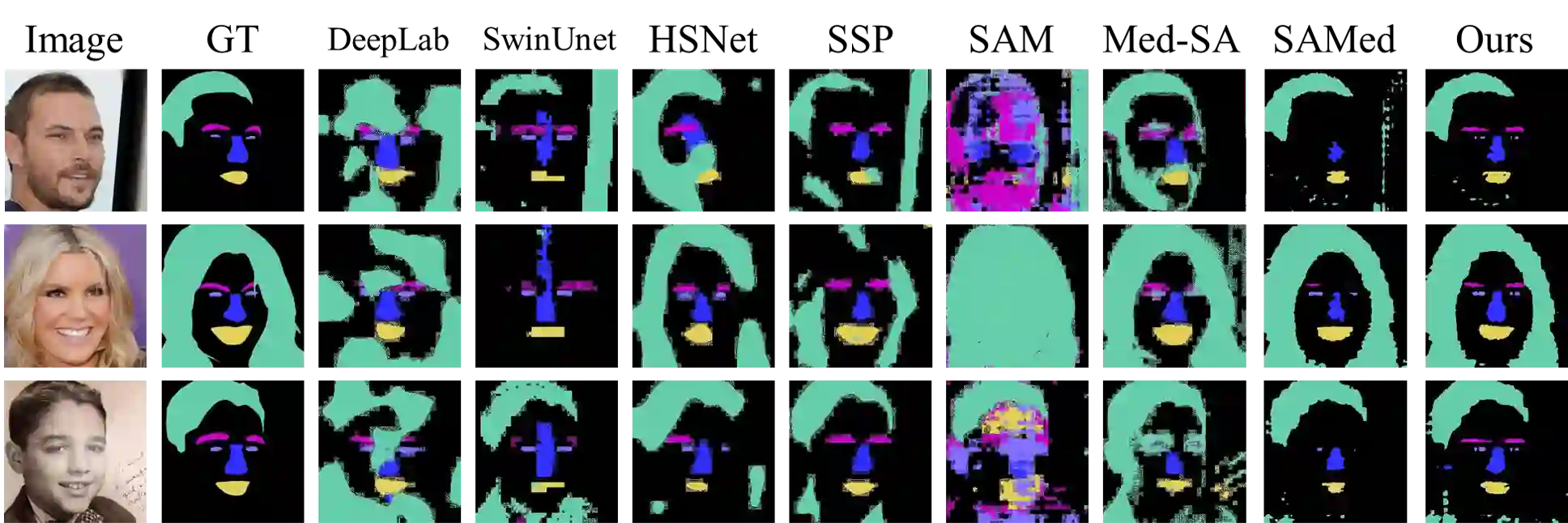
The Segment Anything Model (SAM), a foundation model pretrained on millions of images and segmentation masks, has significantly advanced semantic segmentation, a fundamental task in computer vision. Despite its strengths, SAM encounters two major challenges. Firstly, it struggles with segmenting specific objects autonomously, as it relies on users to manually input prompts like points or bounding boxes to identify targeted objects. Secondly, SAM faces challenges in excelling at specific downstream tasks, like medical imaging, due to a disparity between the distribution of its pretraining data, which predominantly consists of general-domain images, and the data used in downstream tasks. Current solutions to these problems, which involve finetuning SAM, often lead to overfitting, a notable issue in scenarios with very limited data, like in medical imaging. To overcome these limitations, we introduce BLO-SAM, which finetunes SAM based on bi-level optimization (BLO). Our approach allows for automatic image segmentation without the need for manual prompts, by optimizing a learnable prompt embedding. Furthermore, it significantly reduces the risk of overfitting by training the model's weight parameters and the prompt embedding on two separate subsets of the training dataset, each at a different level of optimization. We apply BLO-SAM to diverse semantic segmentation tasks in general and medical domains. The results demonstrate BLO-SAM's superior performance over various state-of-the-art image semantic segmentation methods.
翻译:分段任意模型(SAM)作为在数百万图像和分割掩码上预训练的基础模型,显著推动了计算机视觉基础任务语义分割的发展。尽管表现优异,SAM仍面临两大挑战:首先,它难以自主分割特定目标,需要用户手动输入点或边界框等提示来识别目标对象;其次,由于预训练数据(以通用领域图像为主)与下游任务数据存在分布差异,SAM在医学影像等特定下游任务中难以取得卓越表现。当前针对这些问题的解决方案涉及对SAM进行微调,但往往导致过拟合——这在数据量极少的场景(如医学影像)中尤为突出。为突破这些局限,我们提出BLO-SAM,该方法基于双层优化(BLO)对SAM进行微调。通过优化可学习的提示嵌入,我们的方法无需人工提示即可实现自动图像分割。更关键的是,该方法将模型权重参数与提示嵌入分别在训练数据集的两个不同子集上进行优化,从而显著降低过拟合风险。我们将BLO-SAM应用于通用领域和医学领域的多种语义分割任务,结果表明BLO-SAM在各项任务中均优于当前最先进的图像语义分割方法。