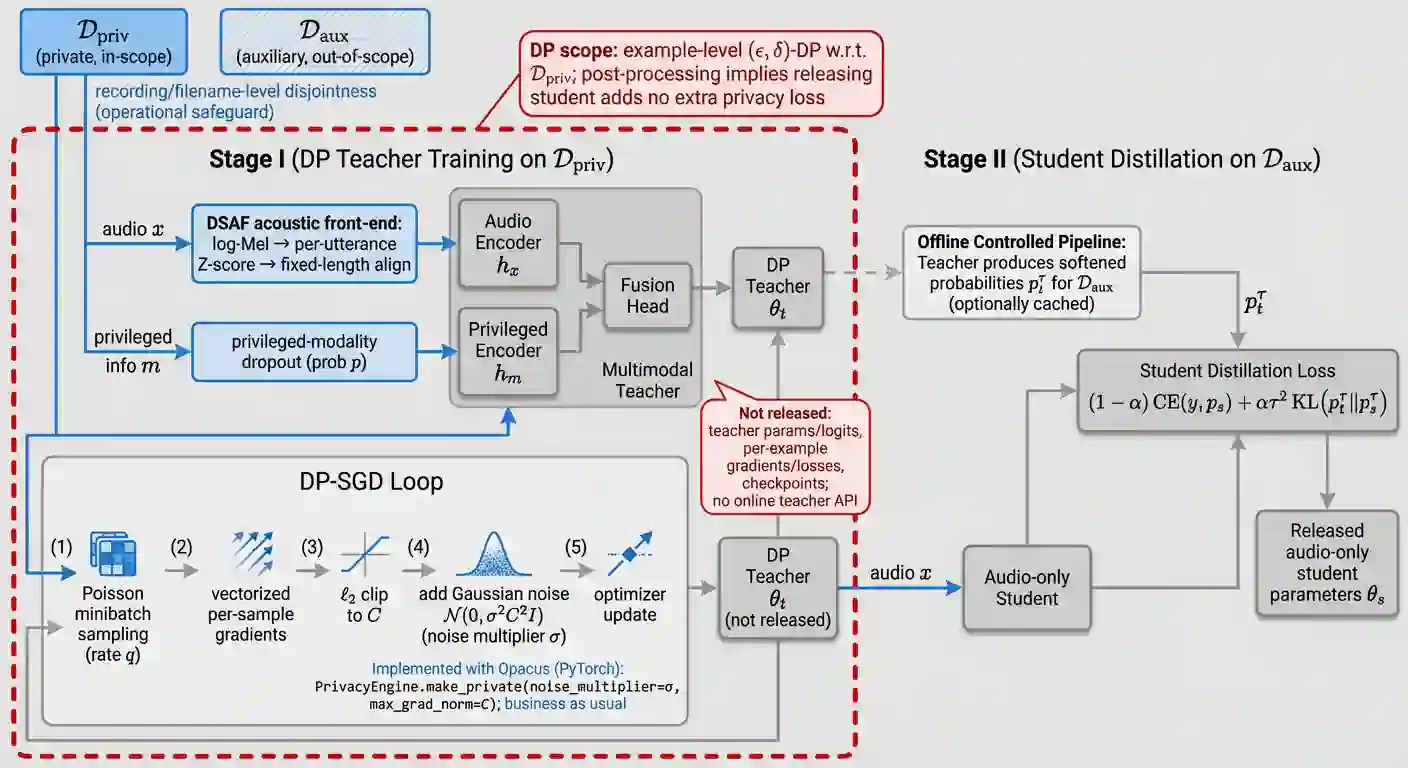
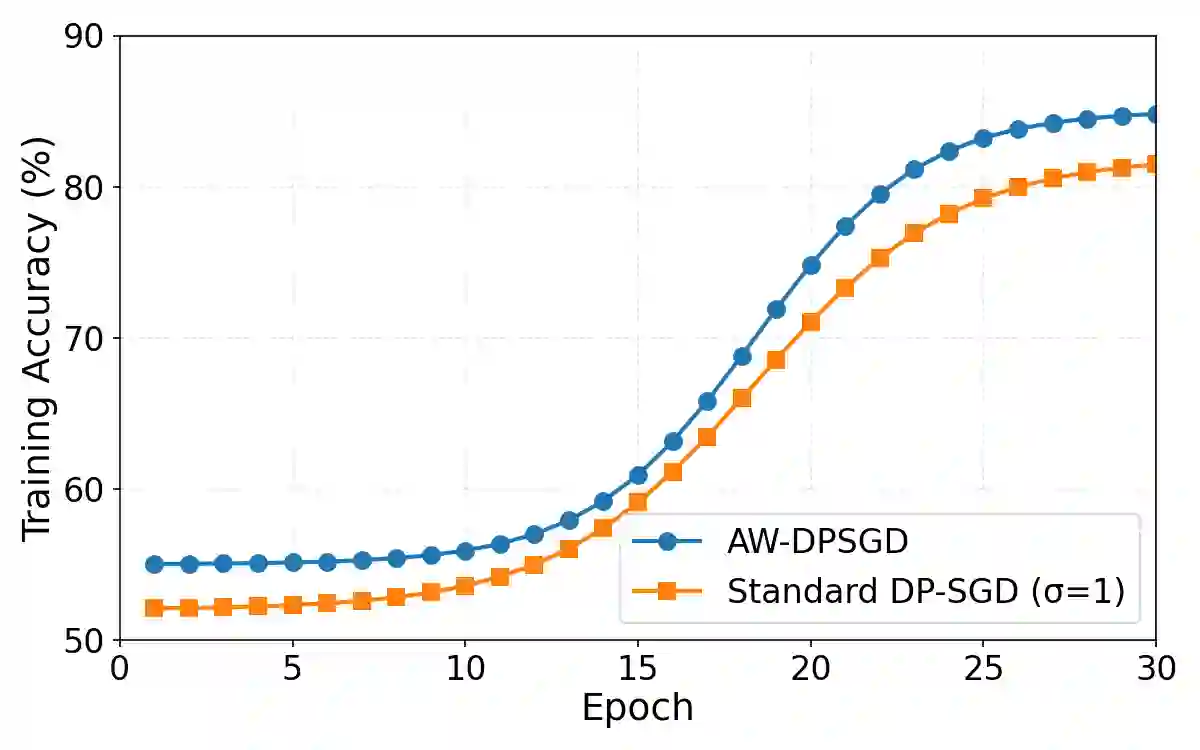
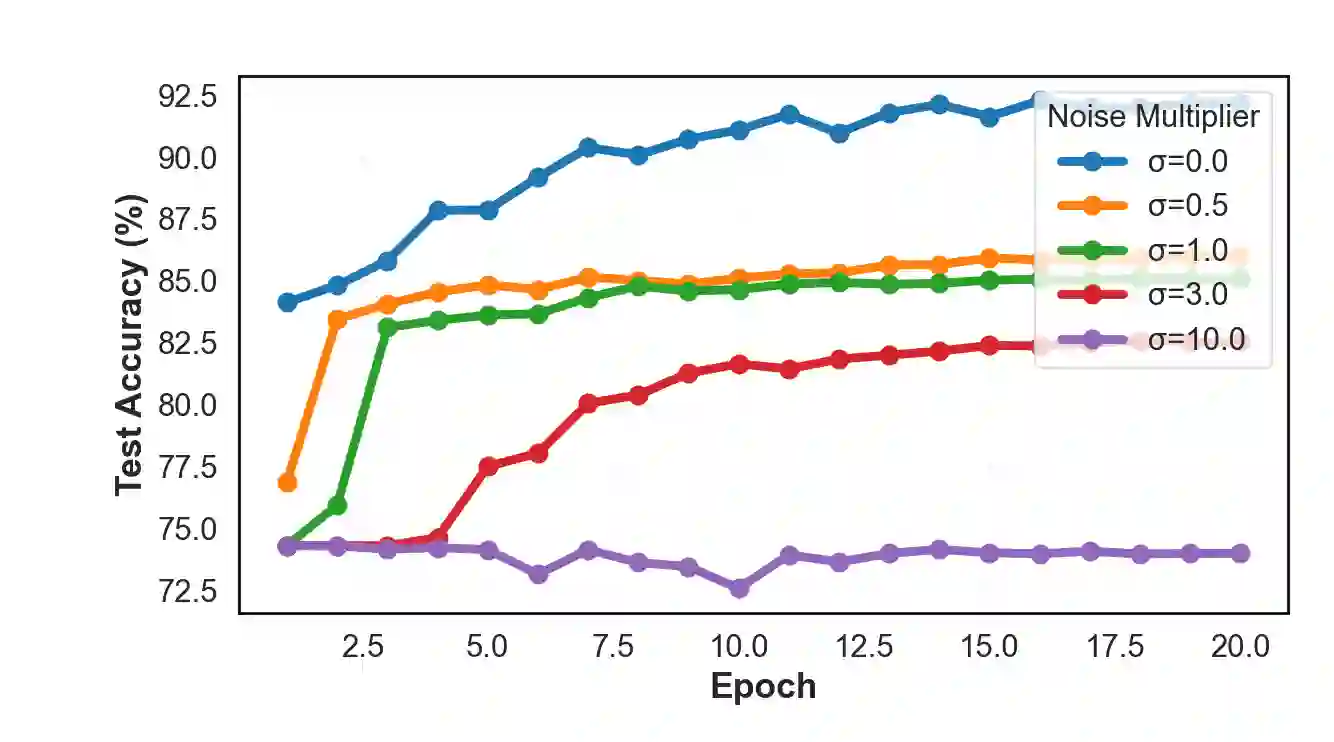
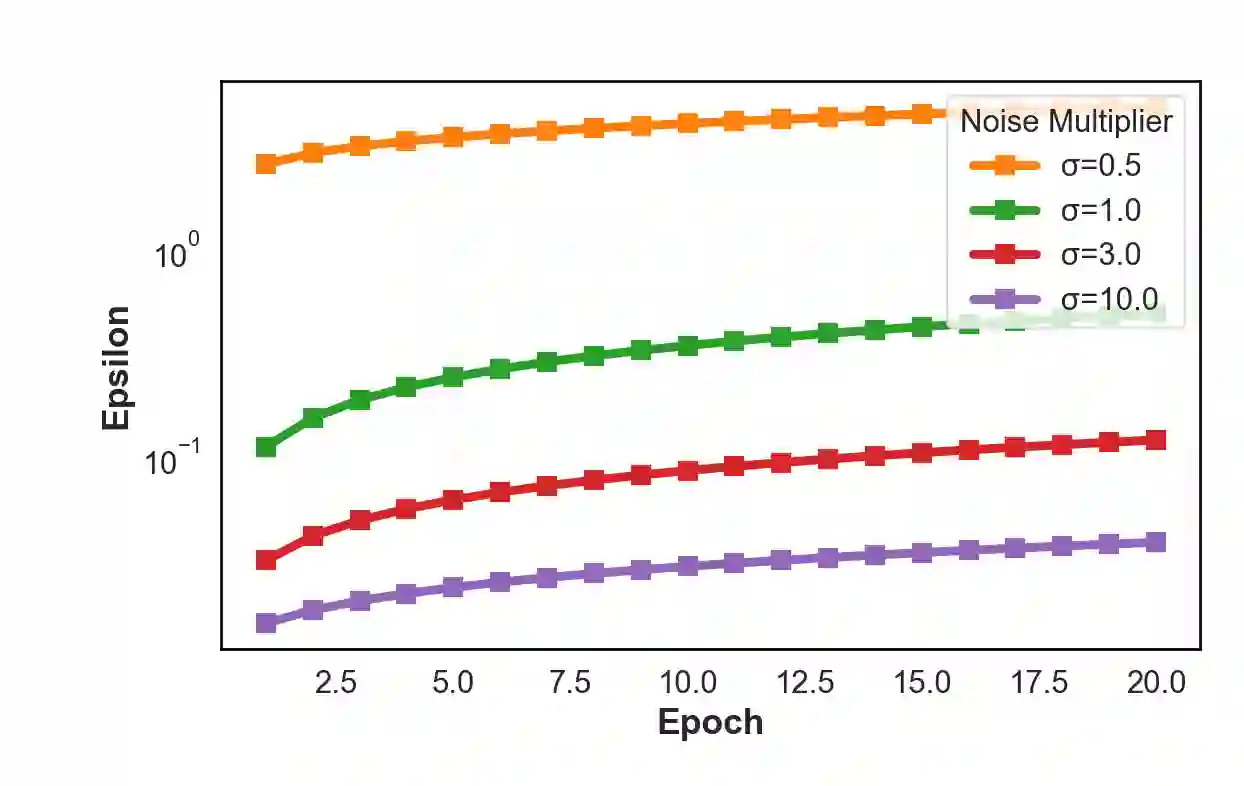
We study example-level private supervised speech classification under a practical release constraint: training may access privileged side information, but the released model must be audio-only. This setting is important because speech systems can often exploit richer side information during development, whereas deployment and release require a lightweight unimodal model with auditable privacy guarantees. Using DP-SGD on the private dataset $D_{\text{priv}}$, we identify a strong-privacy failure mode ($ε\le 1$) on imbalanced tasks, where training may collapse to a near single-class predictor, a phenomenon that overall accuracy can obscure. We therefore emphasize Macro-F1, balanced accuracy, and a simple collapse diagnostic. This failure is especially problematic in our release setting because a collapsed private teacher cannot provide useful supervision for the downstream audio-only student. To address this setting under strong privacy, we propose a two-stage protocol: (i) train a (possibly multimodal) DP teacher on $D_{\text{priv}}$, and (ii) distill an audio-only student on a fixed, recording-disjoint auxiliary dataset $D_{\text{aux}}$ using one-shot offline teacher probability outputs, releasing only the student. The DP guarantee applies only to $D_{\text{priv}}$; we make no DP claim for $D_{\text{aux}}$, and privacy of the released student with respect to $D_{\text{priv}}$ follows by post-processing. We frame this setting as involving four coupled bottlenecks: speech-induced optimization instability under DP-SGD, minority-class erosion under clipping and noise, teacher over-reliance on privileged modalities unavailable at deployment, and train--deploy modality mismatch. We address them with a DP-stabilizing acoustic front-end (DSAF), minibatch-adaptive bounded loss reweighting (AW-DP), privileged-modality dropout, and offline teacher-to-student distillation.
翻译:我们研究了在实用发布约束下的示例级私有监督式语音分类问题:训练过程可能使用特权辅助信息,但发布的模型必须仅基于音频。这一设置至关重要,因为语音系统在开发阶段常能利用更丰富的辅助信息,而部署和发布则需要具备可审计隐私保证的轻量级单模态模型。使用差分隐私随机梯度下降(DP-SGD)在私有数据集$D_{\text{priv}}$上训练时,我们发现在不平衡任务中会出现强隐私失效模式($ε\le 1$),导致训练可能崩溃为近似单类别预测器——这种现象会被整体准确率所掩盖。因此我们强调宏F1分数(Macro-F1)、平衡准确率及简单的崩溃诊断指标。这种失效在我们的发布场景中尤为严重,因为崩溃的私有教师模型无法为下游仅音频学生模型提供有效监督。为解决强隐私约束下的这一难题,我们提出两阶段协议:(i) 在$D_{\text{priv}}$上训练(可能为多模态的)差分隐私教师模型;(ii) 使用一次性离线教师概率输出,在固定的、与录音内容无交集的辅助数据集$D_{\text{aux}}$上蒸馏出仅音频学生模型,仅发布学生模型。差分隐私保证仅适用于$D_{\text{priv}}$;我们不对$D_{\text{aux}}$做差分隐私声明,发布的学生模型对$D_{\text{priv}}$的隐私性通过后处理继承。我们将此场景归纳为四个耦合瓶颈:DP-SGD训练中语音引发的优化不稳定性、裁剪和噪声下的少数类侵蚀、教师模型过度依赖部署时不可用的特权模态,以及训练-部署模态不匹配。我们分别通过差分隐私稳定声学前端(DSAF)、小批量自适应有界损失重加权(AW-DP)、特权模态丢弃和离线教师-学生蒸馏加以解决。