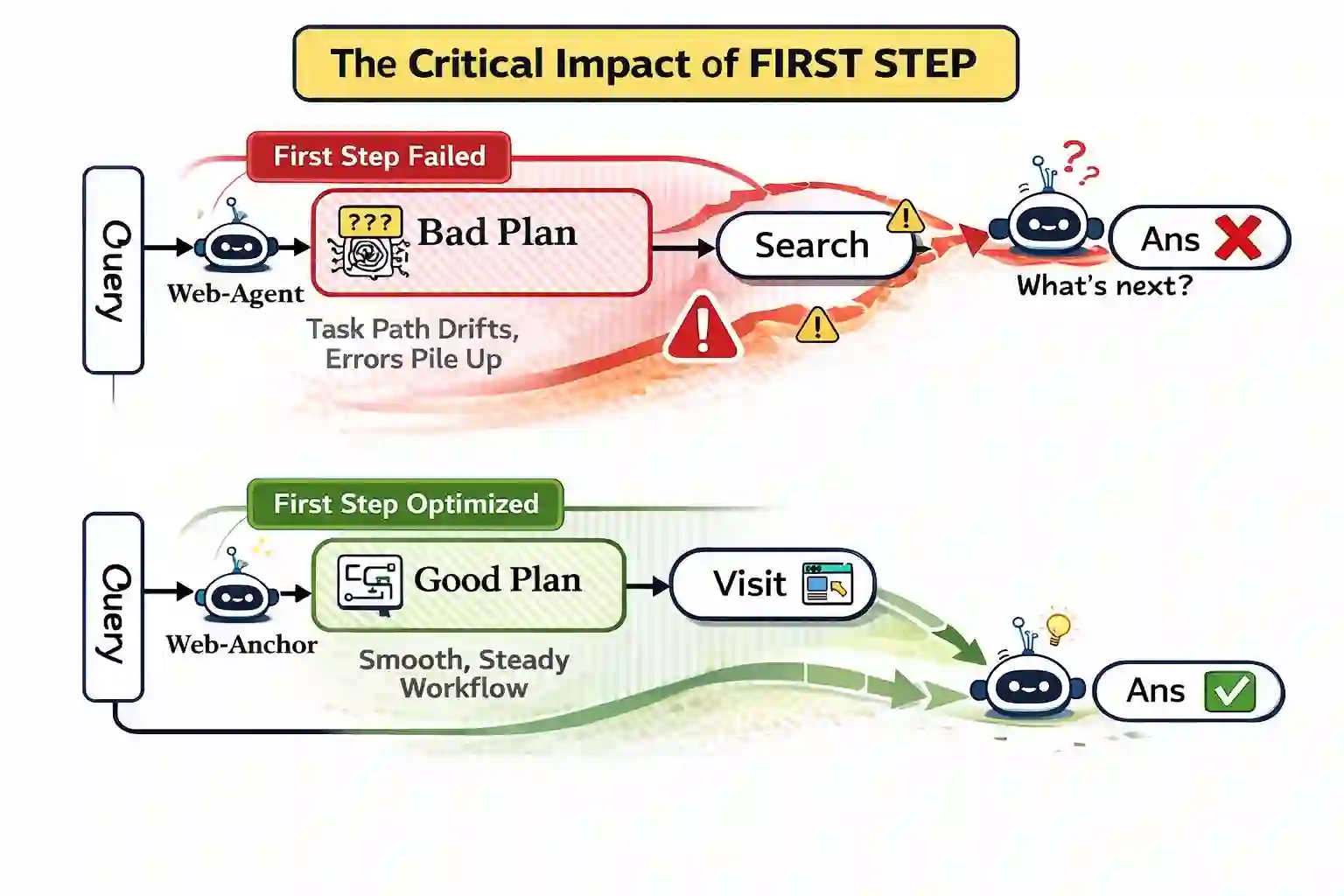
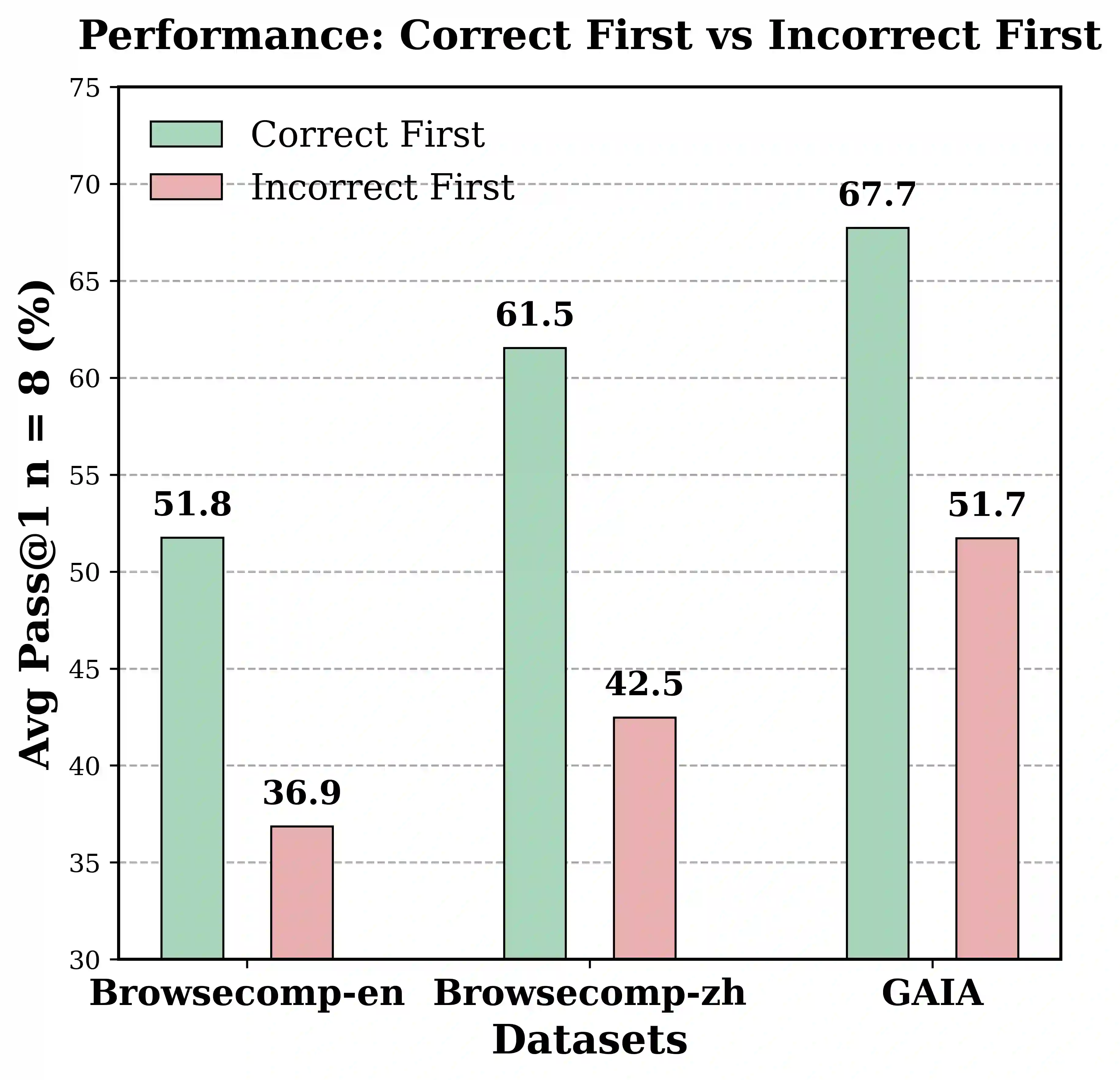
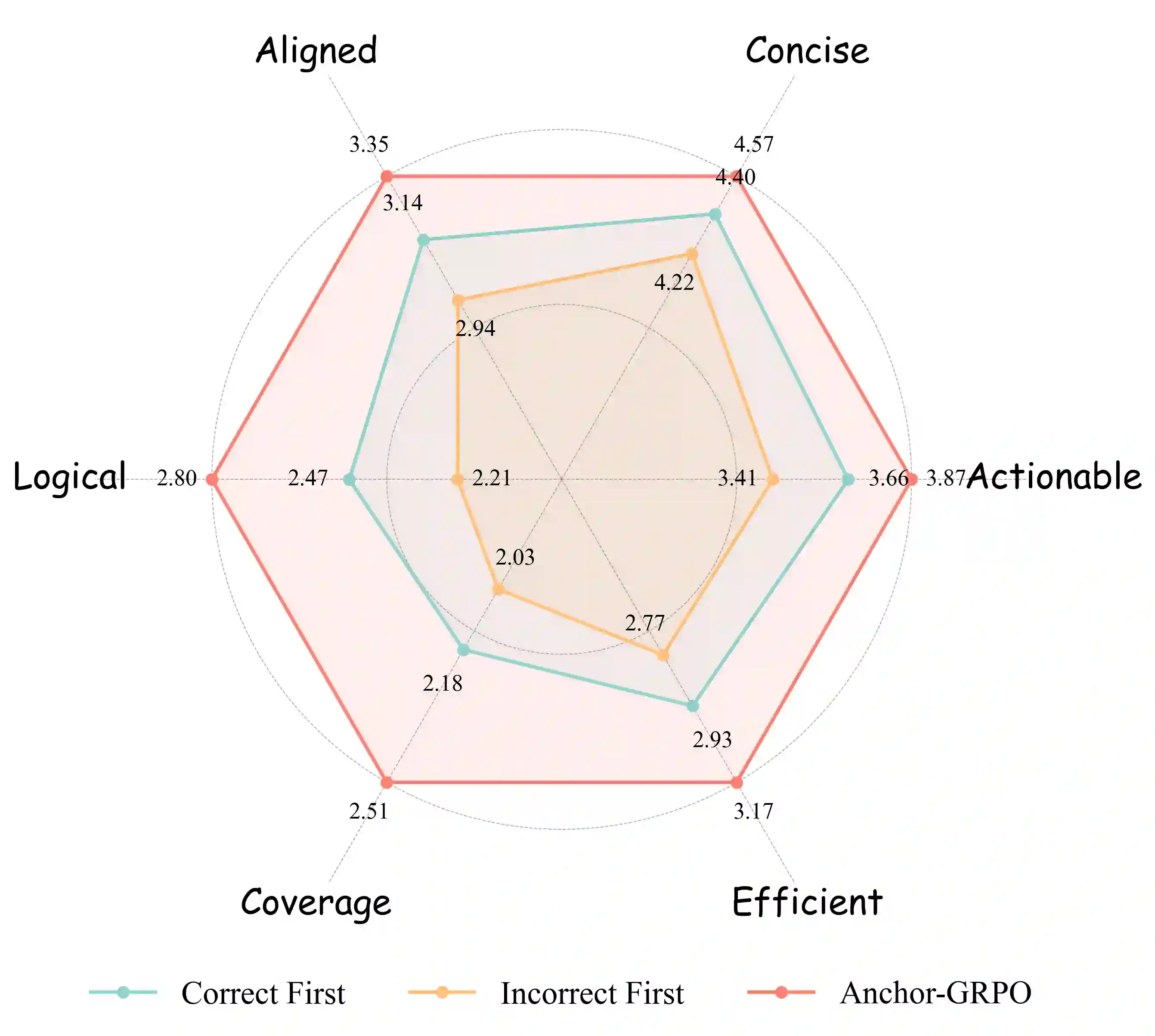
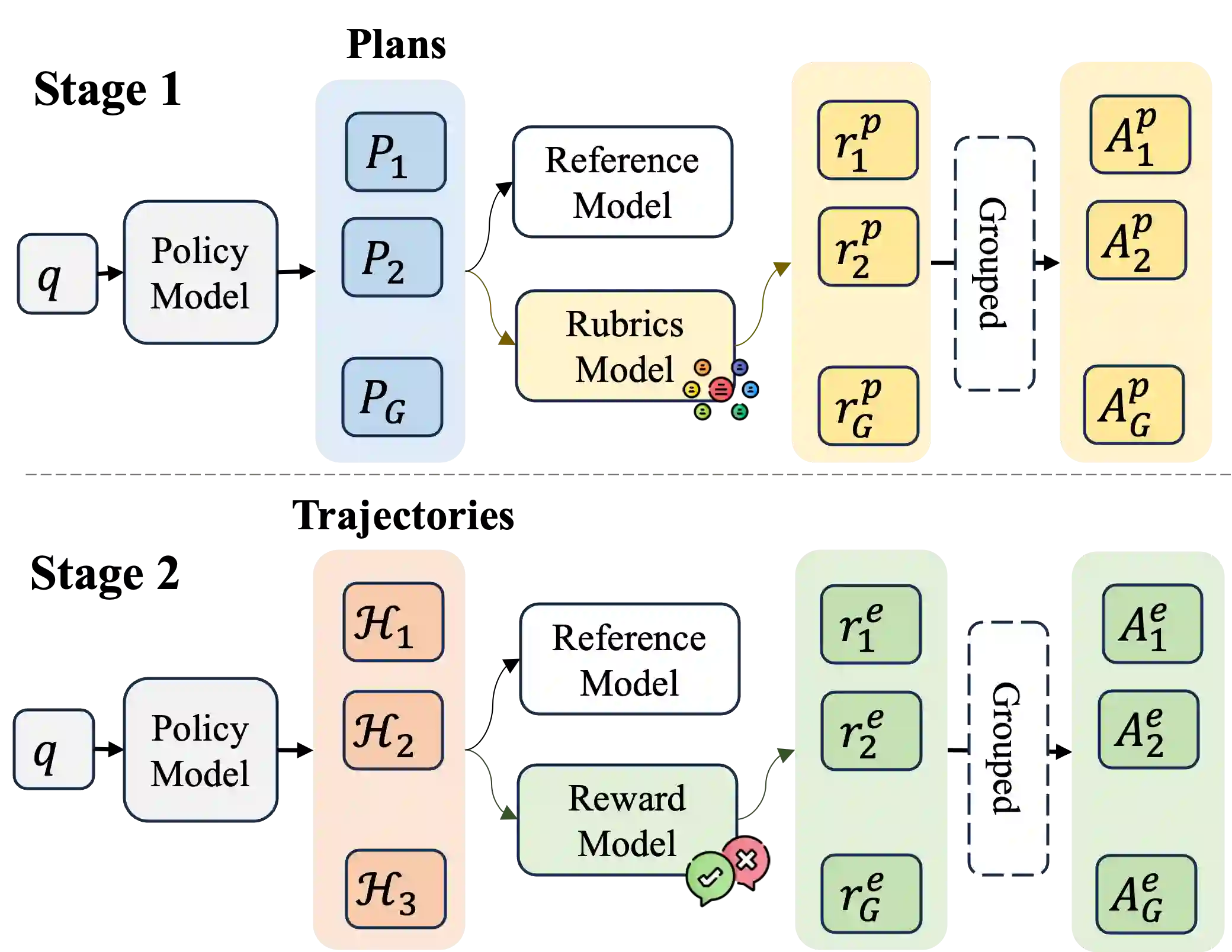
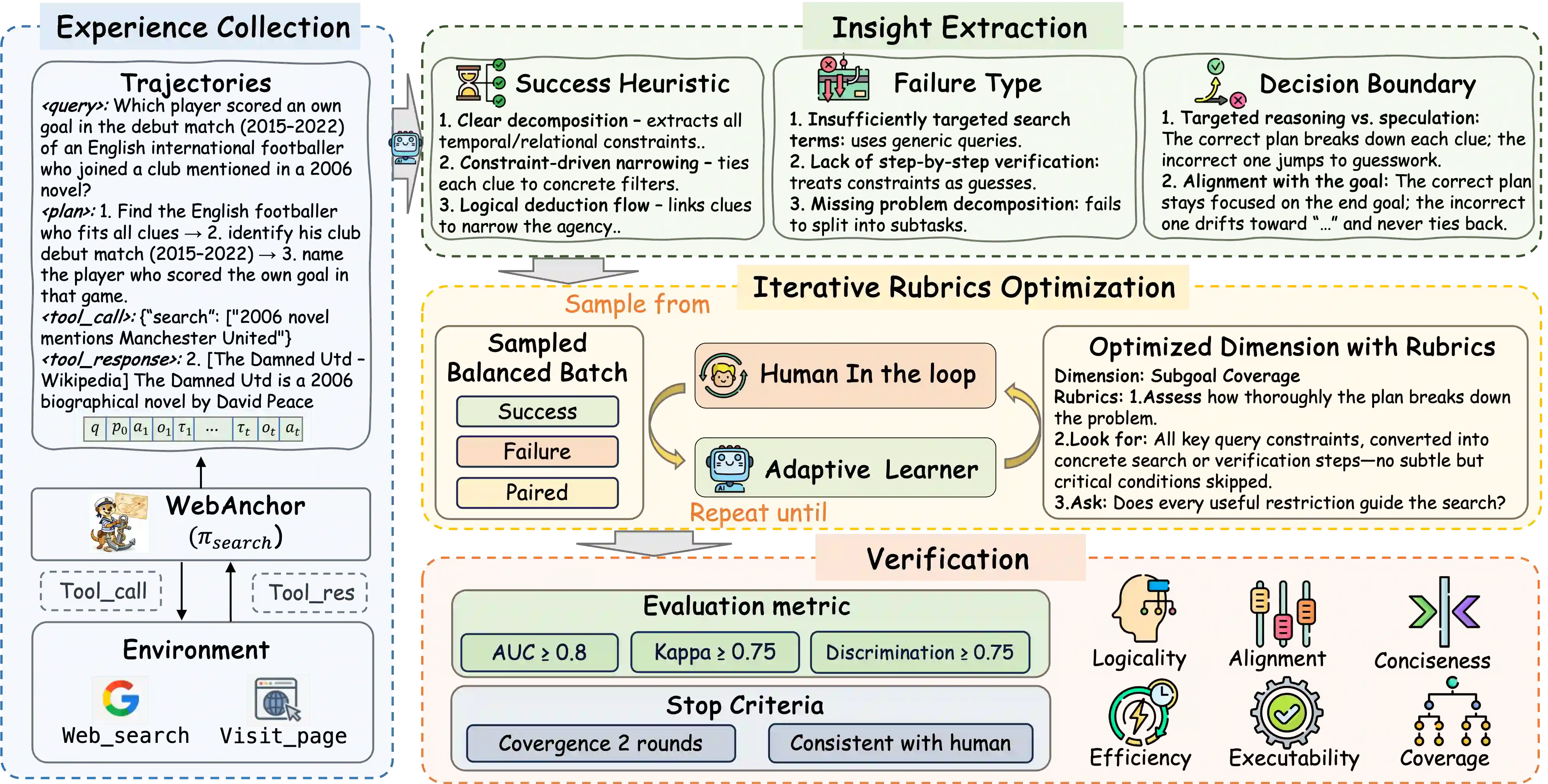
Large Language Model(LLM)-based agents have shown strong capabilities in web information seeking, with reinforcement learning (RL) becoming a key optimization paradigm. However, planning remains a bottleneck, as existing methods struggle with long-horizon strategies. Our analysis reveals a critical phenomenon, plan anchor, where the first reasoning step disproportionately impacts downstream behavior in long-horizon web reasoning tasks. Current RL algorithms, fail to account for this by uniformly distributing rewards across the trajectory. To address this, we propose Anchor-GRPO, a two-stage RL framework that decouples planning and execution. In Stage 1, the agent optimizes its first-step planning using fine-grained rubrics derived from self-play experiences and human calibration. In Stage 2, execution is aligned with the initial plan through sparse rewards, ensuring stable and efficient tool usage. We evaluate Anchor-GRPO on four benchmarks: BrowseComp, BrowseComp-Zh, GAIA, and XBench-DeepSearch. Across models from 3B to 30B, Anchor-GRPO outperforms baseline GRPO and First-step GRPO, improving task success and tool efficiency. Notably, WebAnchor-30B achieves 46.0% pass@1 on BrowseComp and 76.4% on GAIA. Anchor-GRPO also demonstrates strong scalability, getting higher accuracy as model size and context length increase.
翻译:基于大语言模型(LLM)的智能体在网络信息检索任务中展现出强大能力,其中强化学习(RL)已成为关键的优化范式。然而,规划仍然是瓶颈,现有方法难以处理长视野策略。我们的分析揭示了一个关键现象——规划锚点,即在长视野网络推理任务中,首个推理步骤对下游行为产生不成比例的影响。当前的RL算法未能考虑这一现象,而是将奖励均匀分布在轨迹上。为解决此问题,我们提出Anchor-GRPO,一种将规划与执行解耦的两阶段RL框架。在第一阶段,智能体利用从自我对弈经验和人工校准中提取的细粒度评估准则,优化其首步规划。在第二阶段,通过稀疏奖励使执行与初始规划对齐,从而确保稳定高效的工具使用。我们在四个基准测试上评估Anchor-GRPO:BrowseComp、BrowseComp-Zh、GAIA和XBench-DeepSearch。在3B至30B规模的模型上,Anchor-GRPO均优于基线GRPO和First-step GRPO,提升了任务成功率和工具使用效率。值得注意的是,WebAnchor-30B在BrowseComp上达到46.0%的pass@1分数,在GAIA上达到76.4%。Anchor-GRPO还展现出强大的可扩展性,随着模型规模和上下文长度的增加获得更高准确率。