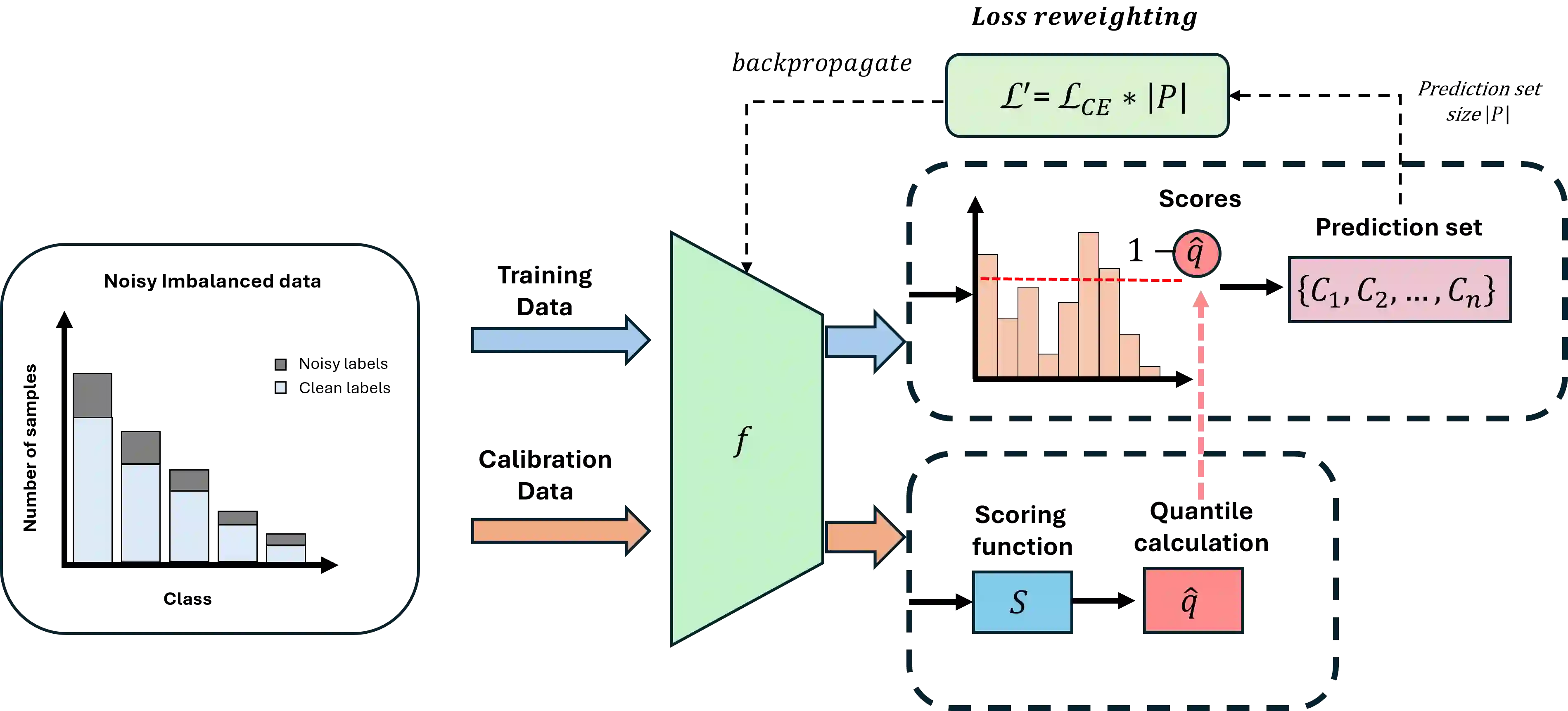
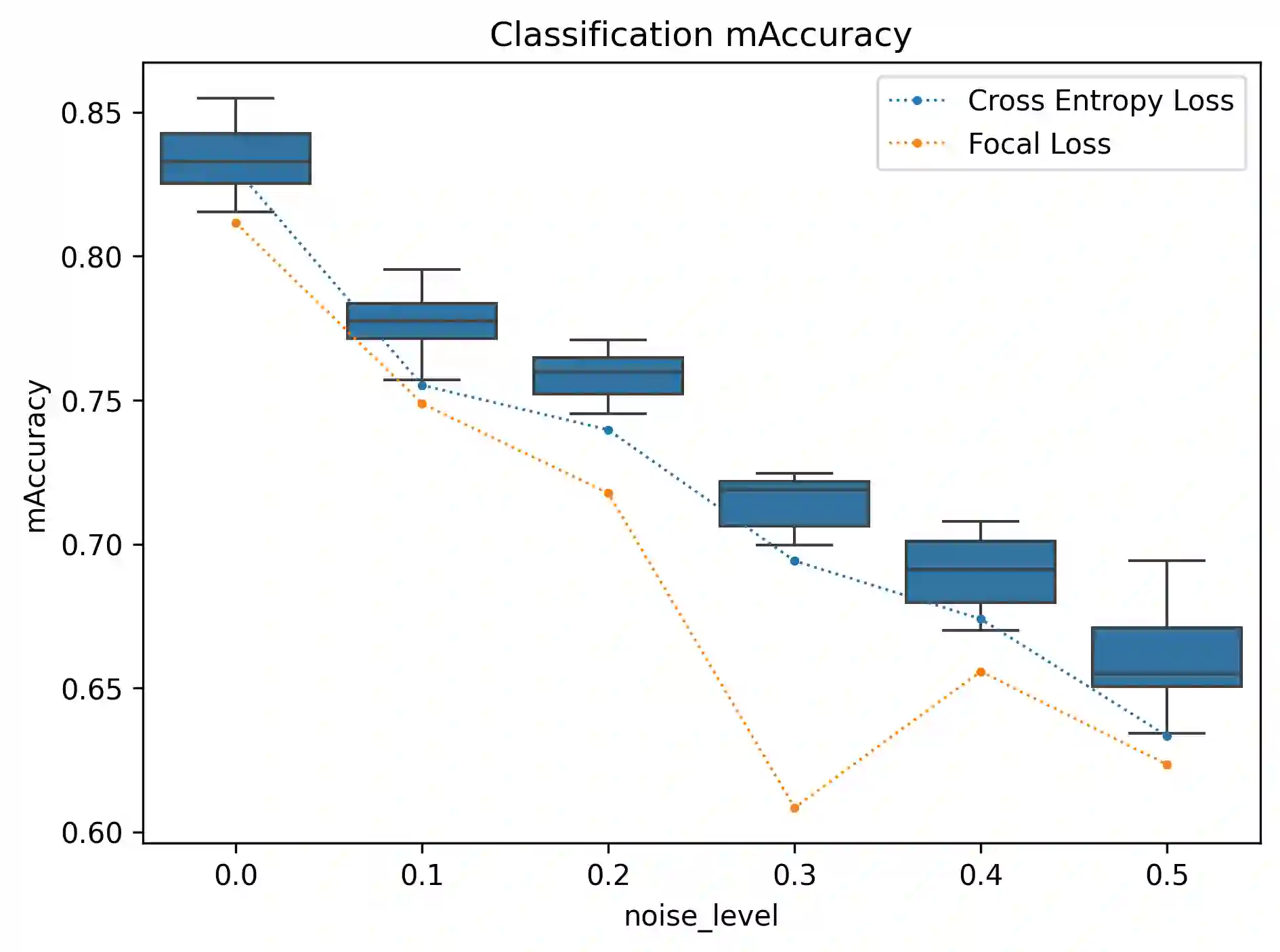
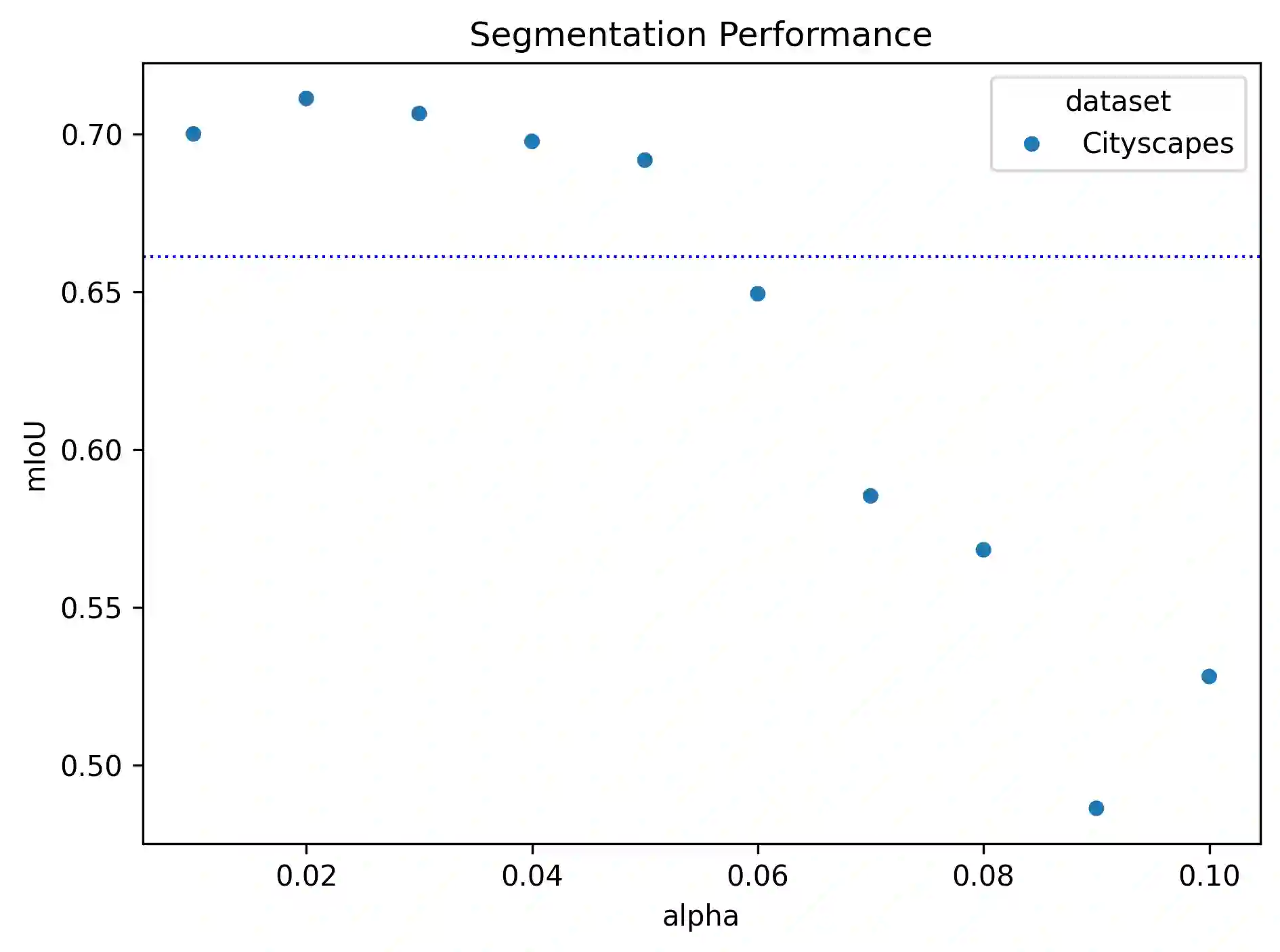
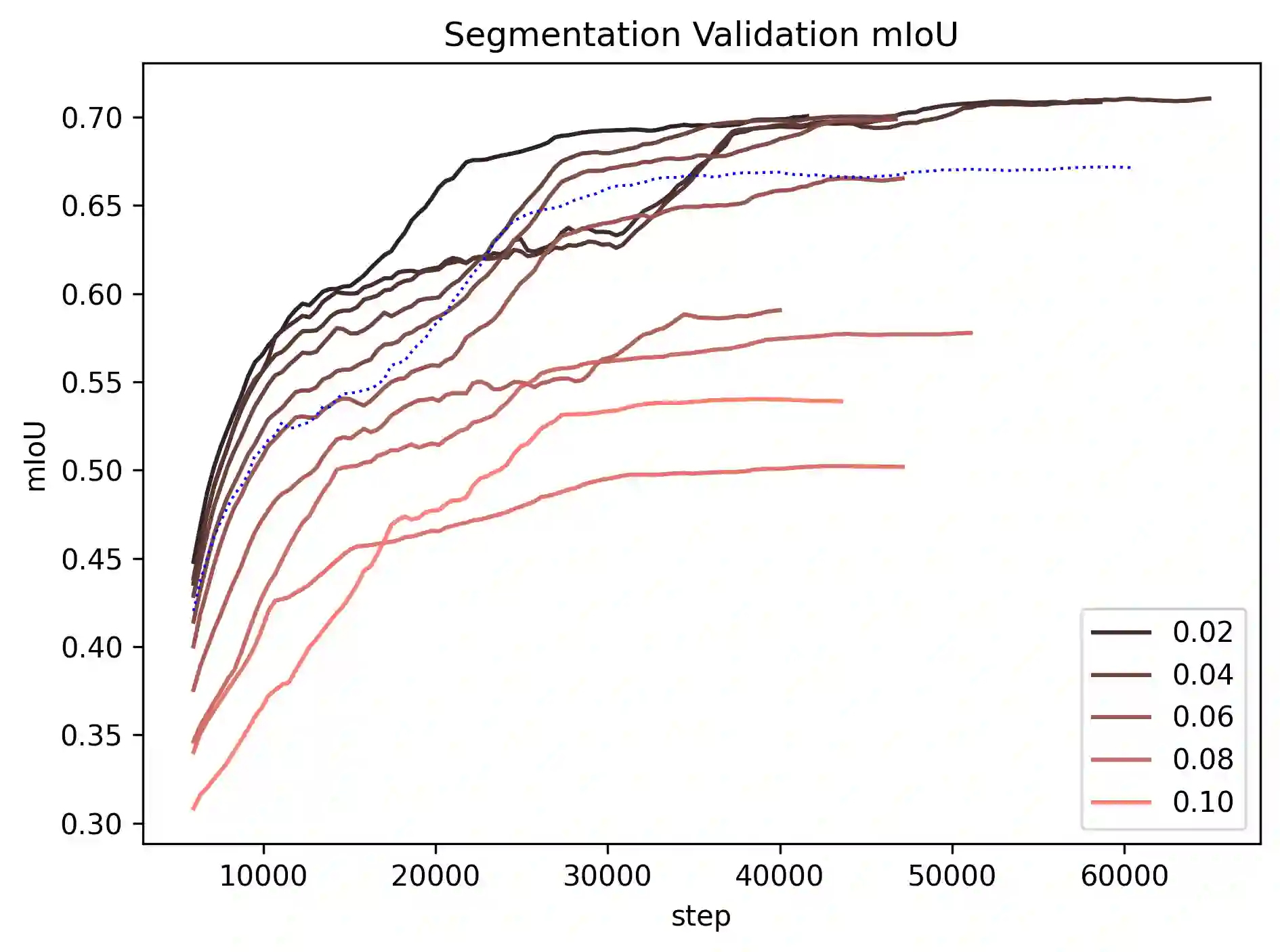
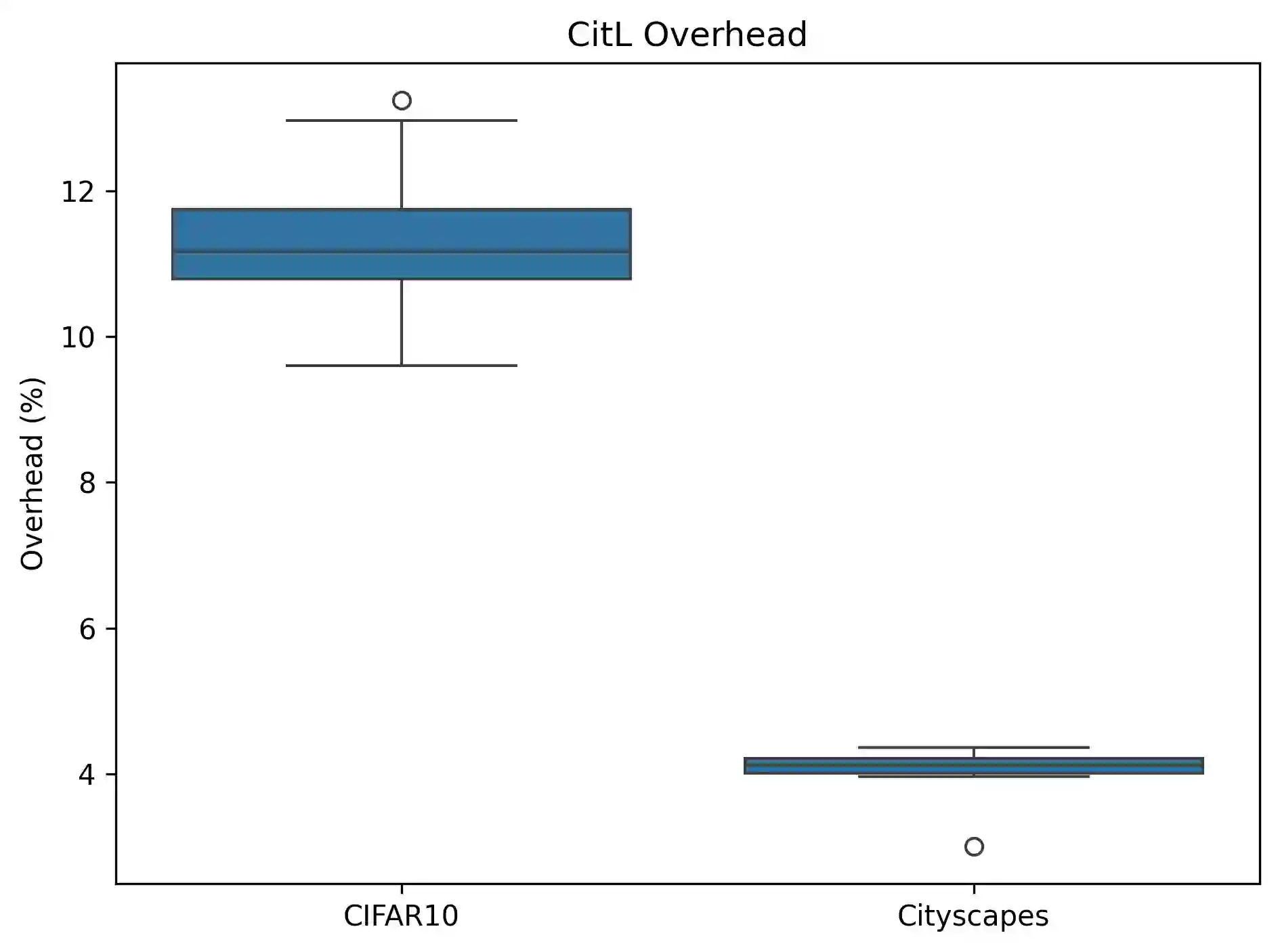
Class imbalance and label noise are pervasive in large-scale datasets, yet much of machine learning research assumes well-labeled, balanced data, which rarely reflects real world conditions. Existing approaches typically address either label noise or class imbalance in isolation, leading to suboptimal results when both issues coexist. In this work, we propose Conformal-in-the-Loop (CitL), a novel training framework that addresses both challenges with a conformal prediction-based approach. CitL evaluates sample uncertainty to adjust weights and prune unreliable examples, enhancing model resilience and accuracy with minimal computational cost. Our extensive experiments include a detailed analysis showing how CitL effectively emphasizes impactful data in noisy, imbalanced datasets. Our results show that CitL consistently boosts model performance, achieving up to a 6.1% increase in classification accuracy and a 5.0 mIoU improvement in segmentation. Our code is publicly available: CitL.
翻译:类别不平衡和标签噪声在大规模数据集中普遍存在,然而大多数机器学习研究假设数据标注良好且类别平衡,这很少反映真实世界条件。现有方法通常孤立地处理标签噪声或类别不平衡问题,当两者共存时会导致次优结果。本文提出Conformal-in-the-Loop(CitL),一种基于保形预测的新型训练框架,可同时应对这两类挑战。CitL通过评估样本不确定性来调整权重并剔除不可靠样本,以最小计算成本增强模型鲁棒性与准确性。我们通过大量实验进行了详细分析,表明CitL能有效强化噪声不平衡数据集中具有影响力的样本。实验结果表明,CitL持续提升模型性能,在分类任务中最高提升6.1%准确率,在分割任务中实现5.0 mIoU的改进。代码已开源:CitL。