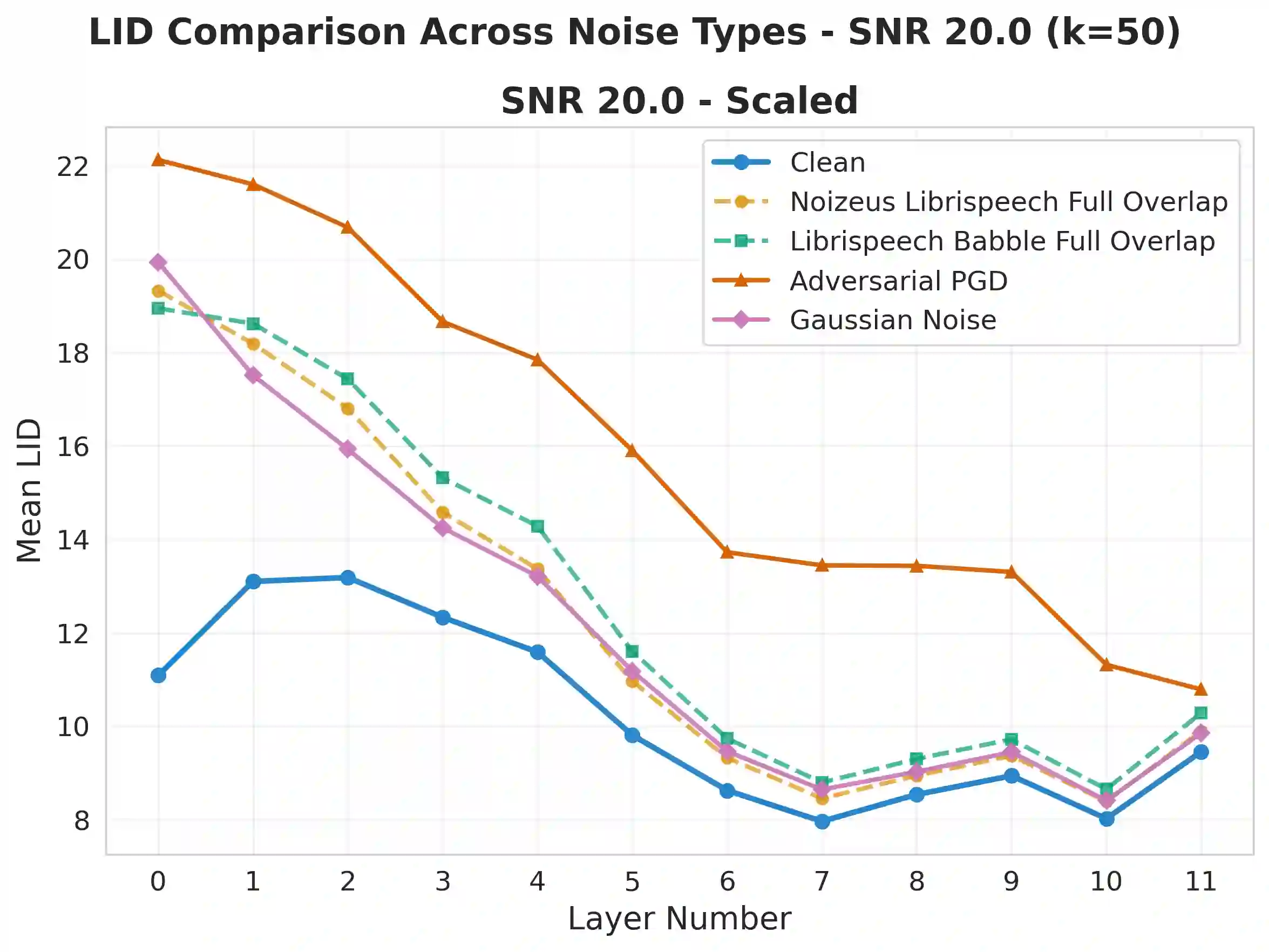
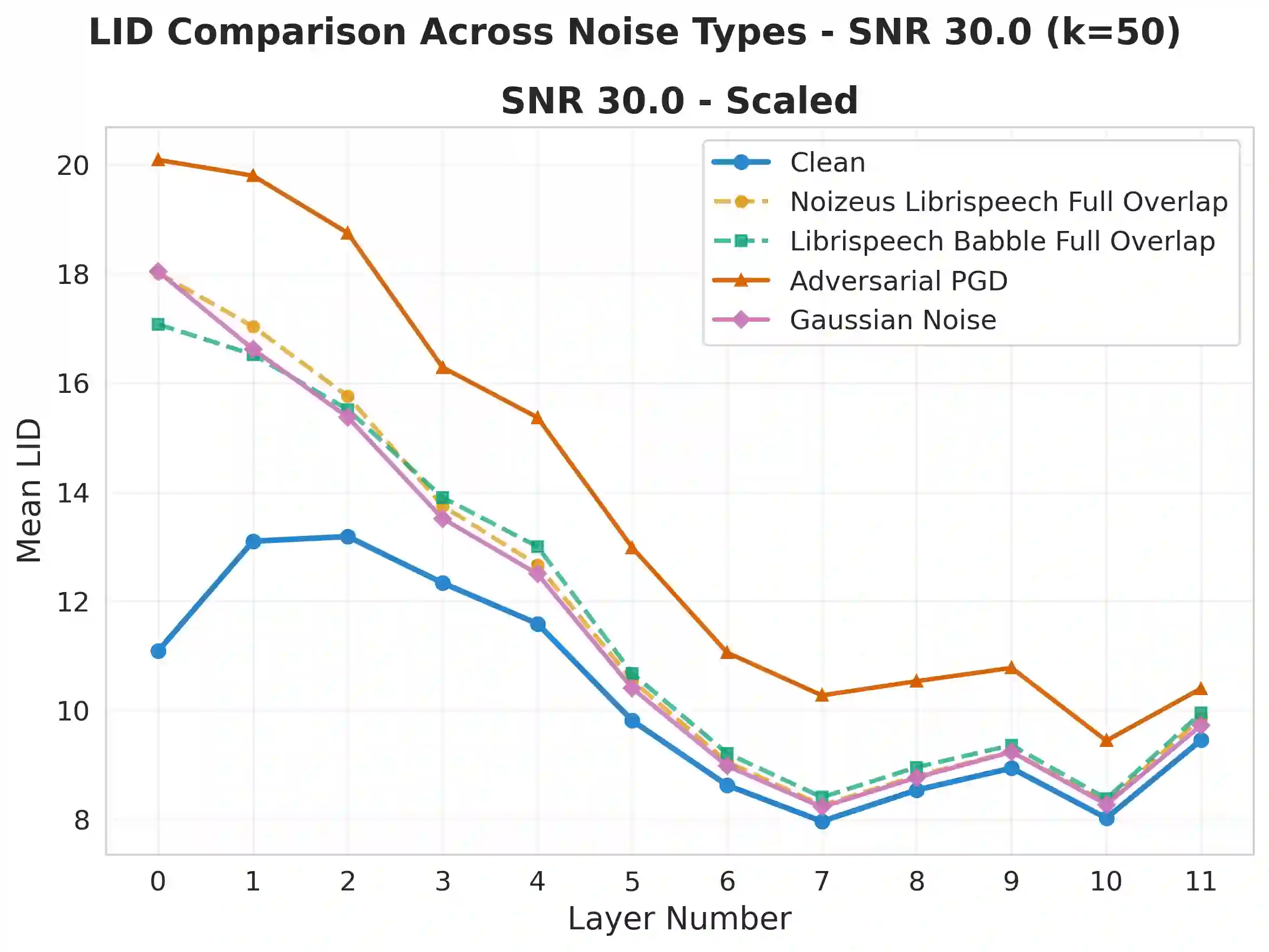
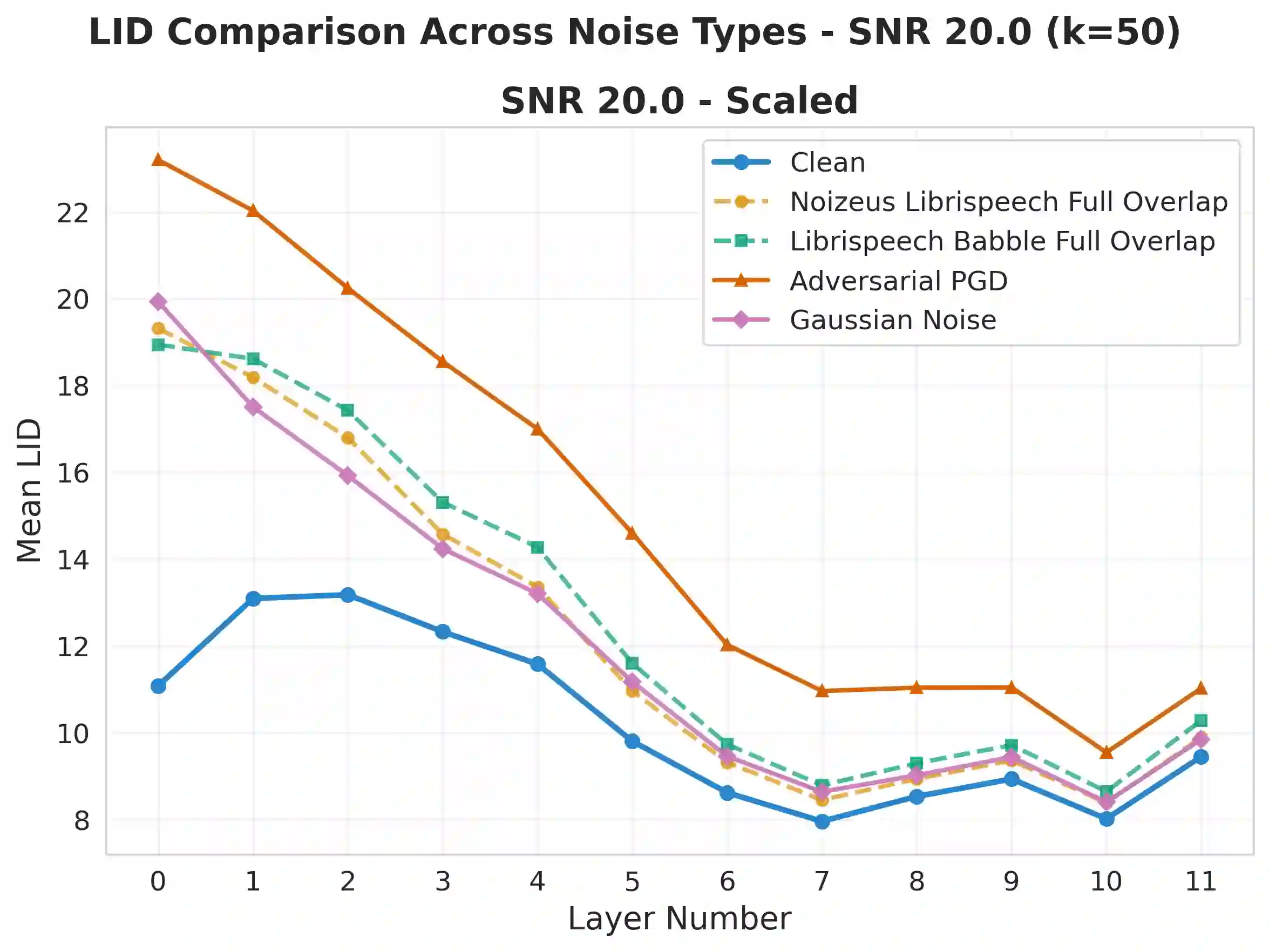
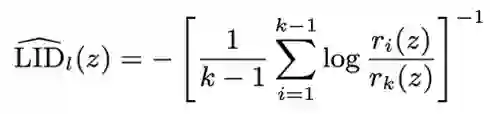Self-supervised speech models (S3Ms) achieve strong downstream performance, yet their learned representations remain poorly understood under natural and adversarial perturbations. Prior studies rely on representation similarity or global dimensionality, offering limited visibility into local geometric changes. We ask: how do perturbations deform local geometry, and do these shifts track downstream automatic speech recognition (ASR) degradation? To address this, we present GRIDS, a framework using Local Intrinsic Dimensionality (LID) across layer-wise representations in WavLM and wav2vec 2.0. We find that LID increases for all low signal-to noise ratio (SNR) perturbations and diverges at high SNR: benign noise converges toward the clean profile, while adversarial inputs retain early-layer LID elevation. We show LID elevation co-occurs with increased WER, and that layer-wise LID features enable anomaly detection (AUROC 0.78-1.00), opening the door to transcript-free monitoring in S3Ms.
翻译:自监督语音模型(S3Ms)在下游任务中取得了优异性能,但其在自然扰动与对抗性扰动下的学习表示仍缺乏深入理解。现有研究依赖表示相似性或全局维度分析,难以揭示局部几何结构变化。我们提出:扰动如何导致局部几何结构形变?这些形变能否反映下游自动语音识别(ASR)性能的退化?为此,我们提出GRIDS框架,通过分析WavLM和wav2vec 2.0各层表示中的局部固有维度(LID)来探究该问题。实验发现:在低信噪比(SNR)扰动下,所有LID值均增大;而在高SNR条件下出现分化——良性噪声的LID趋近于干净样本分布,而对抗性输入则保持早期层LID的显著升高。我们证实LID升高与WER增加存在共现关系,且基于分层LID特征的异常检测可实现0.78-1.00的AUROC值,为S3Ms的免转录本监控开辟了新途径。