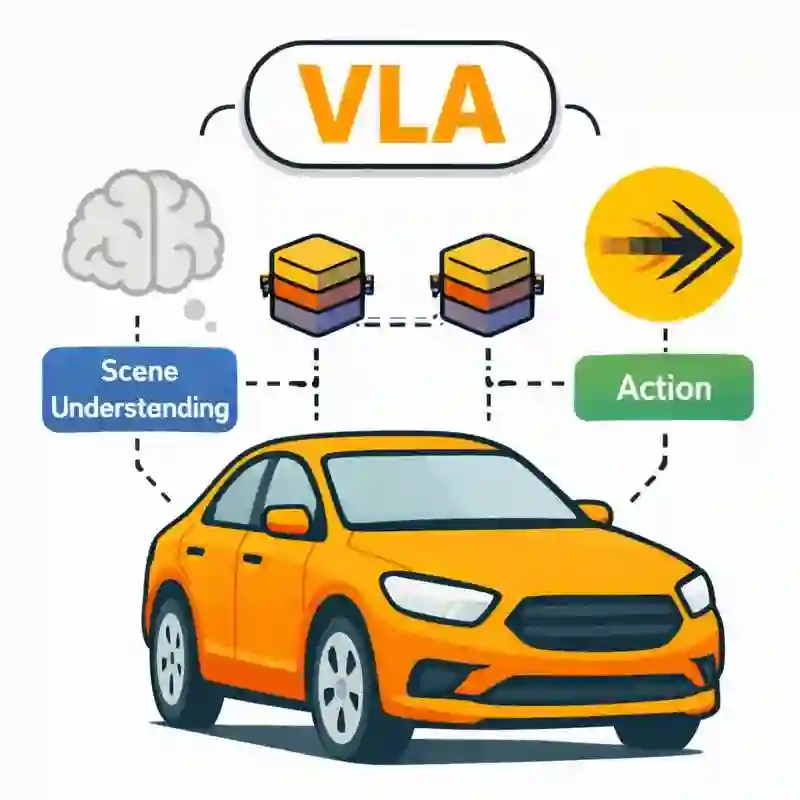
Integrating vision-language models (VLMs) into end-to-end (E2E) autonomous driving (AD) systems has shown promise in improving scene understanding. However, existing integration strategies suffer from several limitations: they either struggle to resolve distribution misalignment between reasoning and action spaces, underexploit the general reasoning capabilities of pretrained VLMs, or incur substantial inference latency during action policy generation, which degrades driving performance. To address these challenges, we propose \OURS in this work, an end-to-end AD framework that unifies reasoning and action generation within a single vision-language-action (VLA) model. Our approach leverages a mixture-of-transformer (MoT) architecture with joint attention sharing, which preserves the general reasoning capabilities of pre-trained VLMs while enabling efficient fast-slow inference through asynchronous execution at different task frequencies. Extensive experiments on multiple benchmarks, under both open- and closed-loop settings, demonstrate that \OURS achieves competitive performance compared to state-of-the-art methods. We further investigate the functional boundary of pre-trained VLMs in AD, examining when AD-tailored fine-tuning is necessary. Our results show that pre-trained VLMs can achieve competitive multi-task scene understanding performance through semantic prompting alone, while fine-tuning remains essential for action-level tasks such as decision-making and trajectory planning. We refer to \href{https://automot-website.github.io/}{Project Page} for the demonstration videos and qualitative results.
翻译:将视觉-语言模型(VLMs)集成到端到端(E2E)自动驾驶(AD)系统中,已显示出在提升场景理解能力方面的潜力。然而,现有的集成策略存在若干局限性:它们要么难以解决推理空间与动作空间之间的分布失配问题,要么未能充分利用预训练VLMs的通用推理能力,要么在动作策略生成过程中产生显著的推理延迟,从而降低驾驶性能。为应对这些挑战,本文提出 \OURS,一个将推理与动作生成统一在单一视觉-语言-动作(VLA)模型内的端到端AD框架。我们的方法采用具有联合注意力共享的混合Transformer(MoT)架构,该架构既保留了预训练VLMs的通用推理能力,又通过在不同任务频率下的异步执行,实现了高效的快慢推理。在多个基准测试上进行的广泛实验(包括开环与闭环设置)表明,\OURS 相比最先进方法取得了具有竞争力的性能。我们进一步探究了预训练VLMs在AD中的功能边界,检验了何时需要进行AD定制化微调。我们的结果表明,预训练VLMs仅通过语义提示即可实现具有竞争力的多任务场景理解性能,而对于决策与轨迹规划等动作级任务,微调仍然至关重要。演示视频与定性结果请参见 \href{https://automot-website.github.io/}{项目主页}。