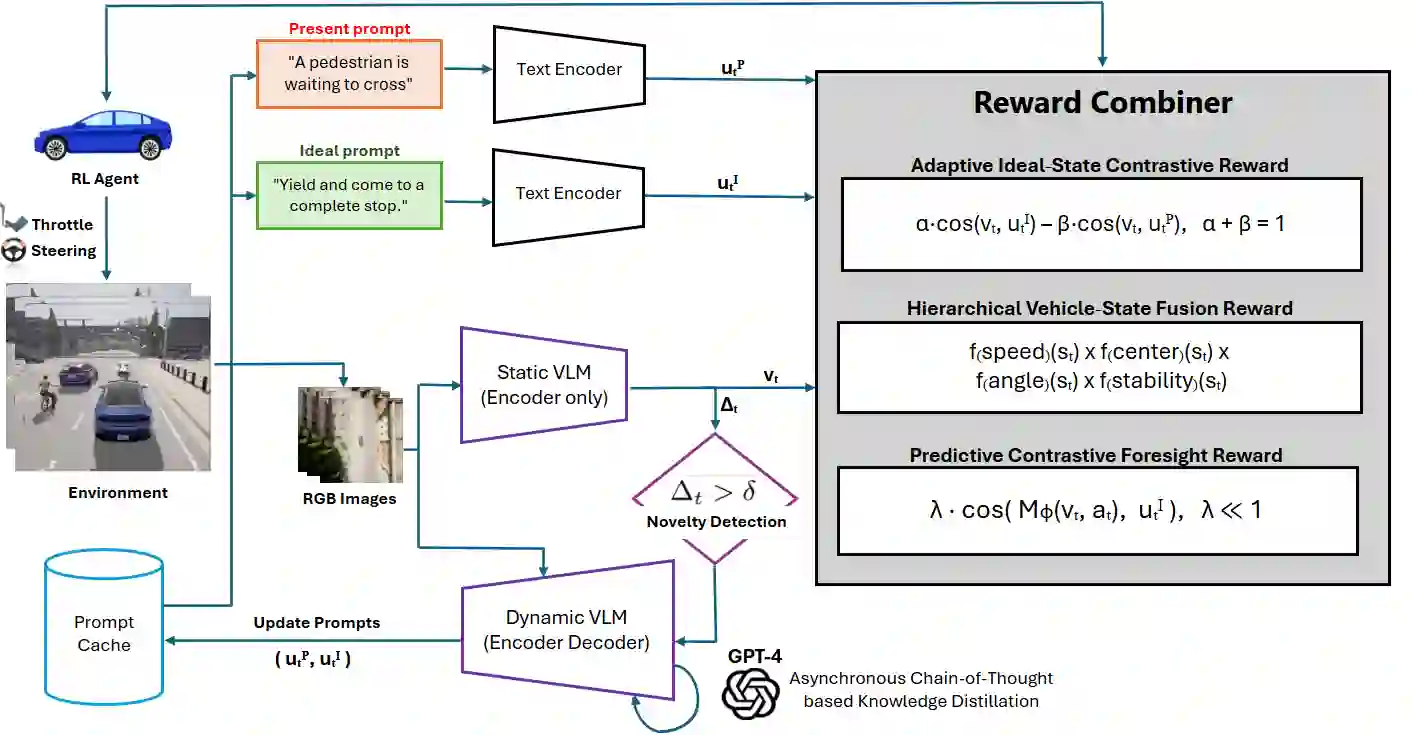
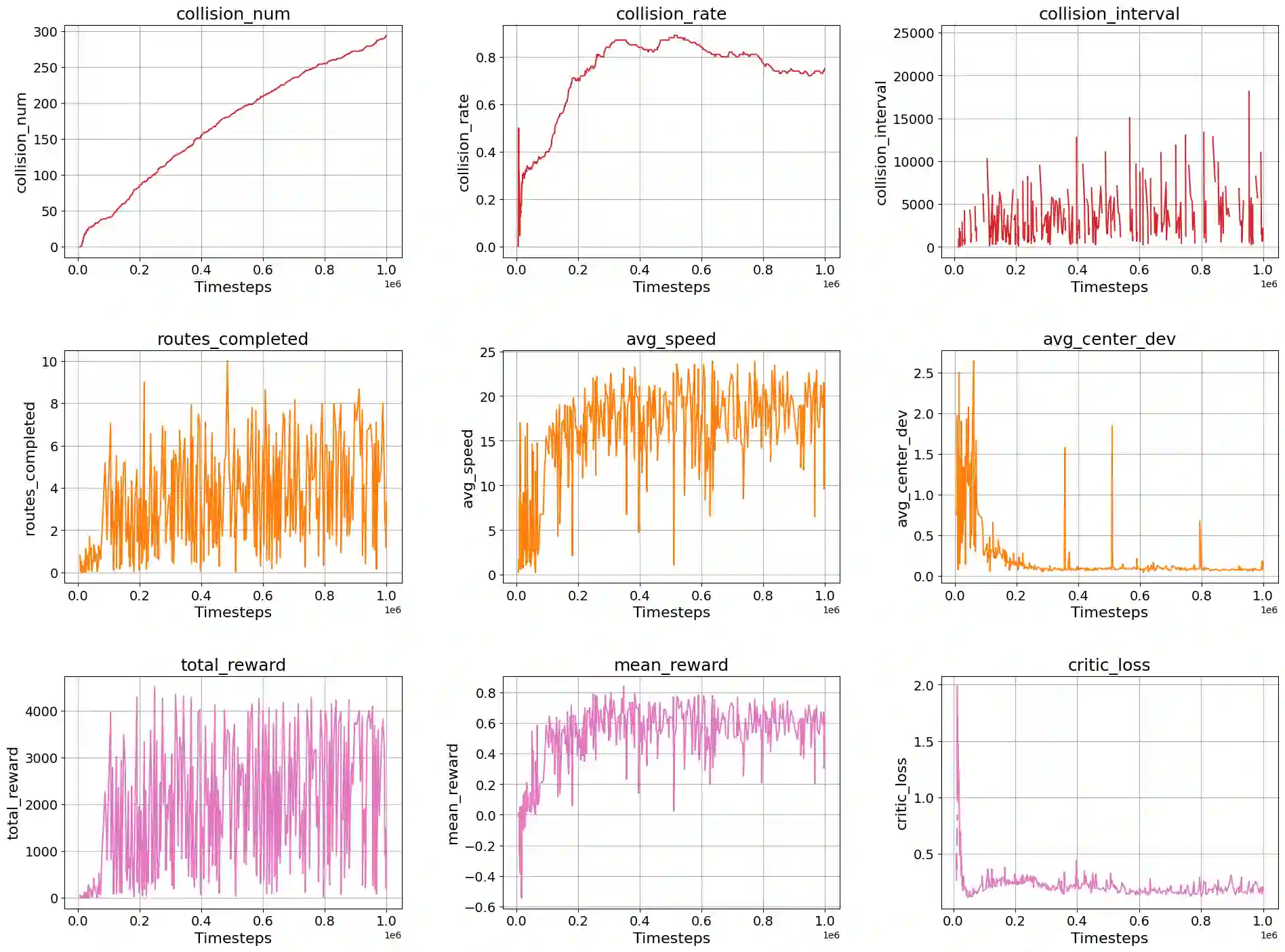
End-to-end autonomous driving systems map sensor data directly to control commands, but remain opaque, lack interpretability, and offer no formal safety guarantees. While recent vision-language-guided reinforcement learning (RL) methods introduce semantic feedback, they often rely on static prompts and fixed objectives, limiting adaptability to dynamic driving scenes. We present DriveMind, a unified semantic reward framework that integrates: (i) a contrastive Vision-Language Model (VLM) encoder for stepwise semantic anchoring; (ii) a novelty-triggered VLM encoder-decoder, fine-tuned via chain-of-thought (CoT) distillation, for dynamic prompt generation upon semantic drift; (iii) a hierarchical safety module enforcing kinematic constraints (e.g., speed, lane centering, stability); and (iv) a compact predictive world model to reward alignment with anticipated ideal states. DriveMind achieves 19.4 +/- 2.3 km/h average speed, 0.98 +/- 0.03 route completion, and near-zero collisions in CARLA Town 2, outperforming baselines by over 4% in success rate. Its semantic reward generalizes zero-shot to real dash-cam data with minimal distributional shift, demonstrating robust cross-domain alignment and potential for real-world deployment.
翻译:端到端自动驾驶系统将传感器数据直接映射为控制指令,但其过程不透明、缺乏可解释性,且无法提供形式化的安全保障。尽管近期基于视觉语言引导的强化学习方法引入了语义反馈,但它们通常依赖静态提示和固定目标,限制了在动态驾驶场景中的适应性。我们提出了DriveMind,一个统一的语义奖励框架,其整合了:(i)用于逐步语义锚定的对比式视觉语言模型编码器;(ii)通过思维链蒸馏微调的新颖性触发式VLM编码器-解码器,用于在发生语义漂移时动态生成提示;(iii)强制执行运动学约束(如速度、车道居中、稳定性)的分层安全模块;以及(iv)用于奖励与预期理想状态对齐的紧凑预测世界模型。DriveMind在CARLA Town 2中实现了19.4 +/- 2.3 km/h的平均速度、0.98 +/- 0.03的路线完成率以及近乎零碰撞,其成功率比基线方法高出4%以上。该框架的语义奖励能够零样本泛化至真实行车记录仪数据,且分布偏移极小,展现了强大的跨领域对齐能力及实际部署潜力。