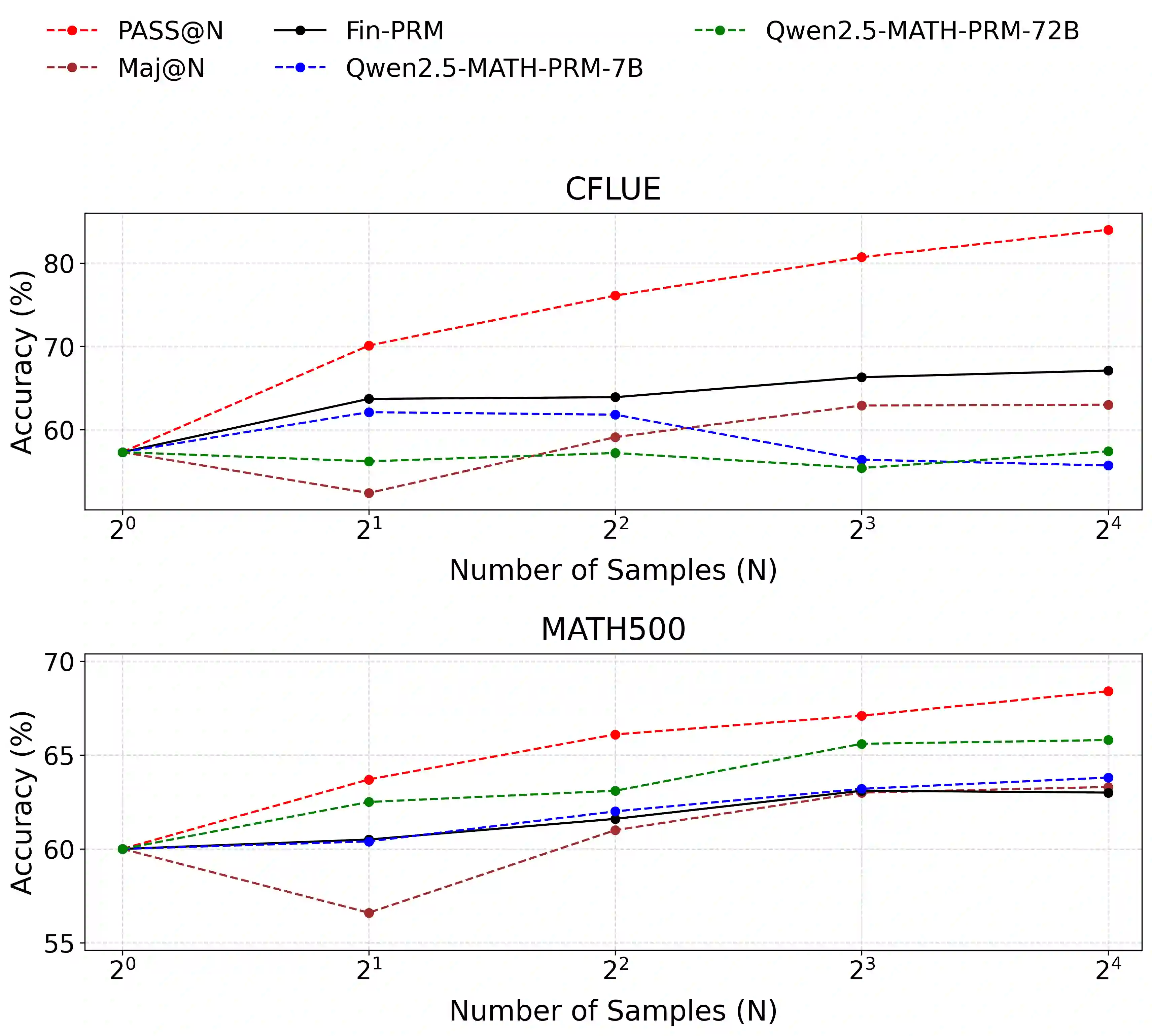
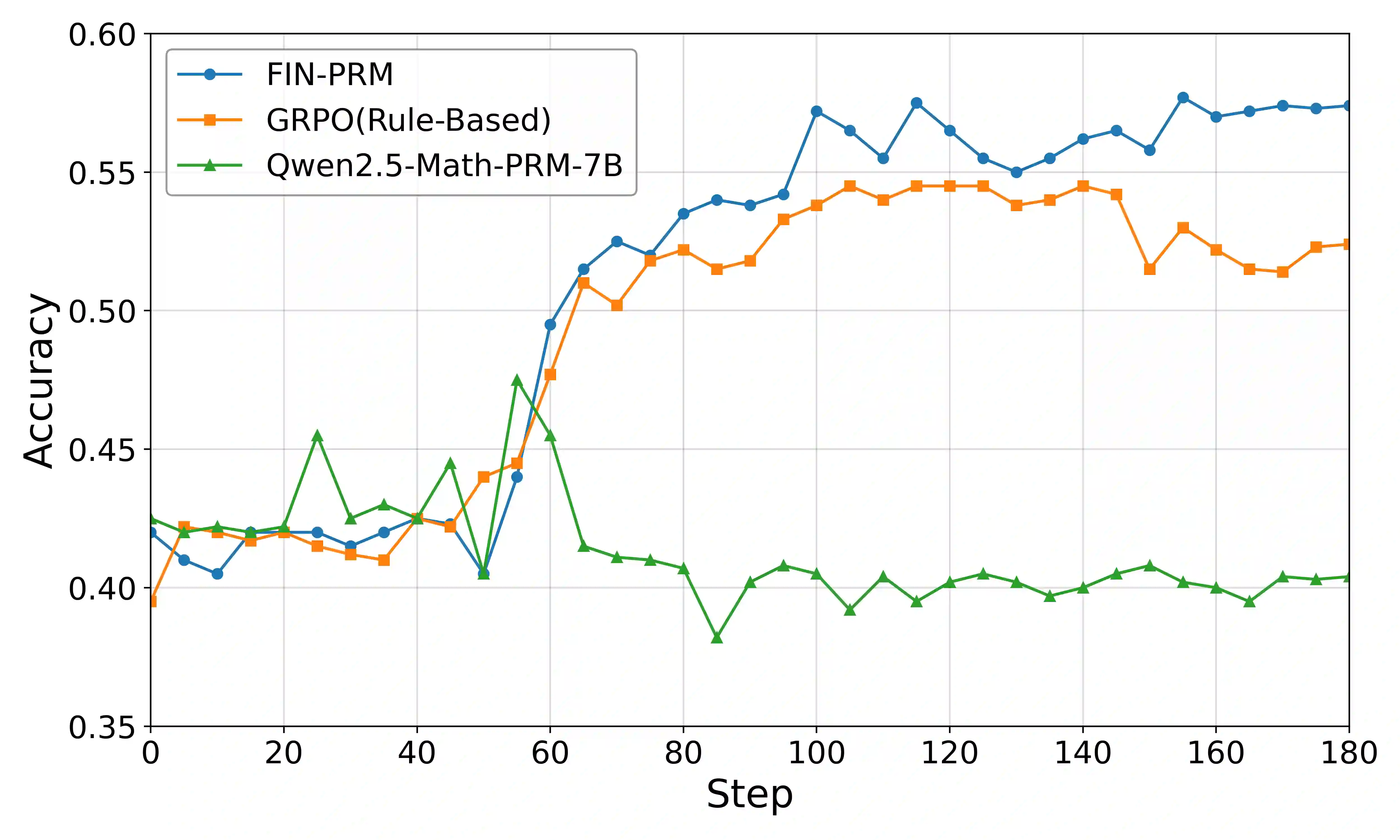
Process Reward Models (PRMs) supervise intermediate reasoning steps in large language models (LLMs), but existing PRMs are mainly trained on general-domain data and struggle with the structured, symbolic, and fact-sensitive nature of financial reasoning. Financial tasks require not only correct final answers but also verifiable intermediate steps grounded in domain knowledge. In this paper, we propose Fin-PRM, a domain-specialized, trajectory-aware PRM for financial reasoning that jointly models step-level correctness and trajectory-level coherence, producing binary supervision signals for both local and global reasoning quality. To support reliable supervision, we construct a high-quality financial reasoning dataset of 3K trajectories, where step- and trajectory-level labels are automatically derived from multi-source reward signals, including Monte Carlo rollouts, LLM-based evaluation, and explicit financial knowledge verification. Fin-PRM defines a unified ranking score that integrates step- and trajectory-level rewards, enabling consistent use across multiple settings. We evaluate Fin-PRM in three scenarios: (1) offline trajectory selection for supervised fine-tuning, (2) reward-guided Best-of-$N$ inference for test-time scaling, and (3) process-aware reward shaping for reinforcement learning. Experiments on financial reasoning benchmarks, including CFLUE and FinQA, show that Fin-PRM consistently outperforms general-purpose PRMs and strong baselines. Our project resources will be available at https://github.com/aliyun/qwen-dianjin.
翻译:过程奖励模型(PRM)对大语言模型的中间推理步骤进行监督,但现有PRM主要基于通用域数据训练,难以应对金融推理中结构化、符号化及对事实敏感的特性。金融任务不仅需要正确的最终答案,还要求基于领域知识的可验证中间步骤。本文提出Fin-PRM——一种面向金融推理的领域专业化轨迹感知过程奖励模型,同时建模步骤级正确性与轨迹级连贯性,为局部与全局推理质量生成二值监督信号。为支持可靠监督,我们构建了包含3000条轨迹的高质量金融推理数据集,其中步骤级与轨迹级标签通过多源奖励信号自动生成,包括蒙特卡洛展开、基于大模型的评估及显式金融知识验证。Fin-PRM定义了融合步骤级与轨迹级奖励的统一排序分数,可在多种场景下一致使用。我们在三个场景中评估Fin-PRM:(1)用于监督微调的离线轨迹选择;(2)用于测试时扩展的奖励引导型Best-of-N推理;(3)用于强化学习的过程感知奖励塑形。在CFLUE和FinQA等金融推理基准上的实验表明,Fin-PRM始终优于通用PRM及强基线方法。项目资源将发布于https://github.com/aliyun/qwen-dianjin。