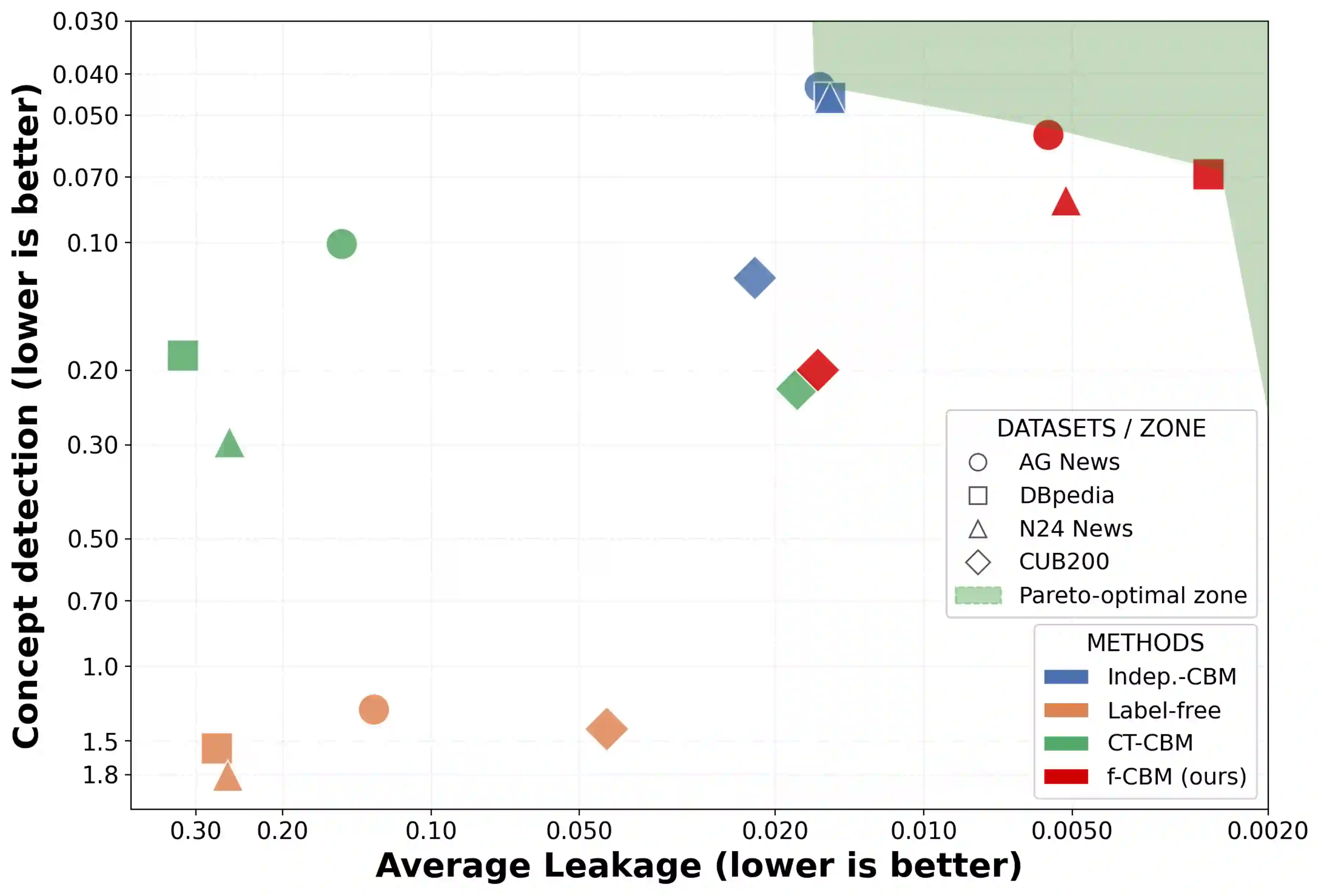
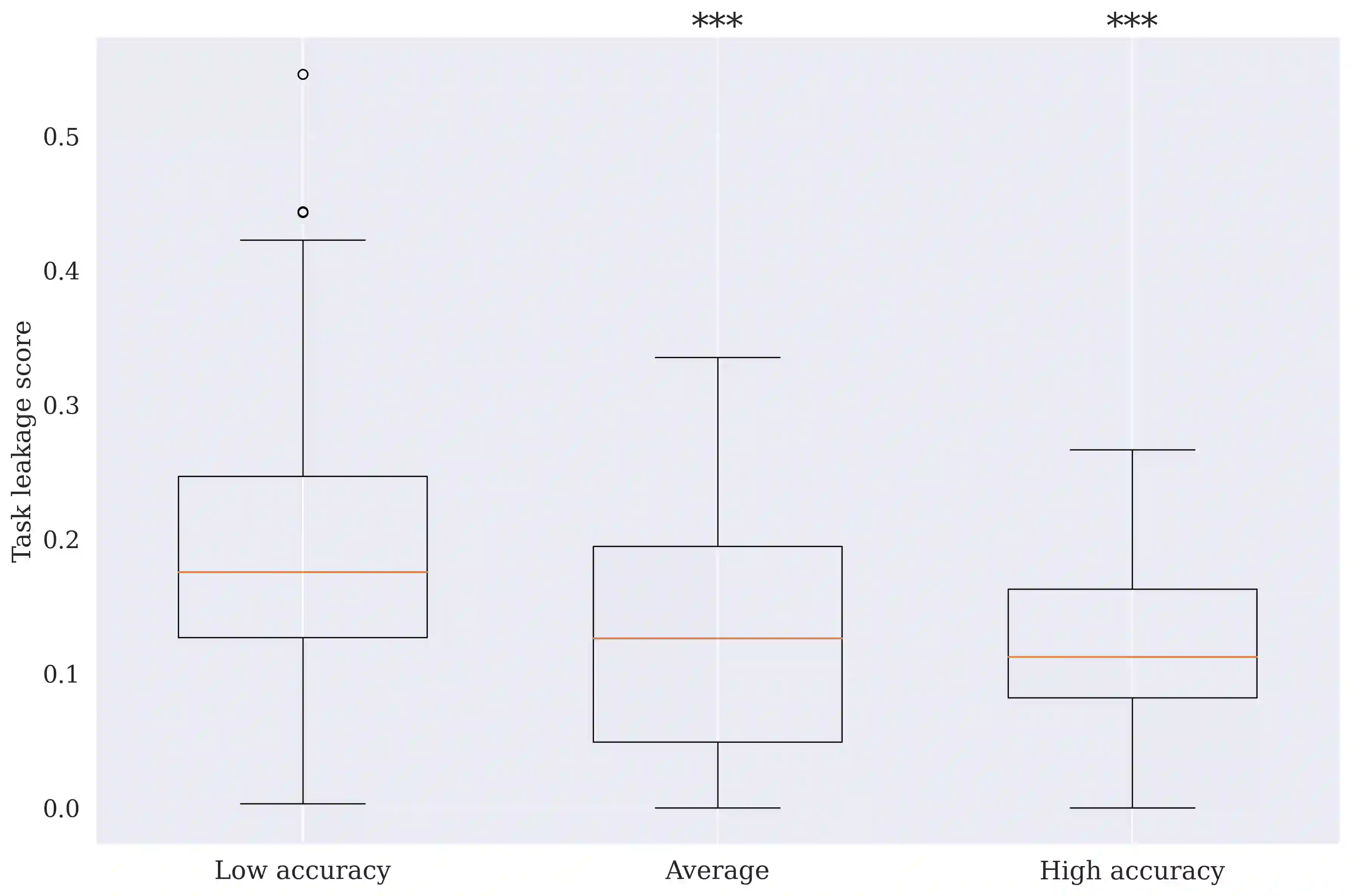
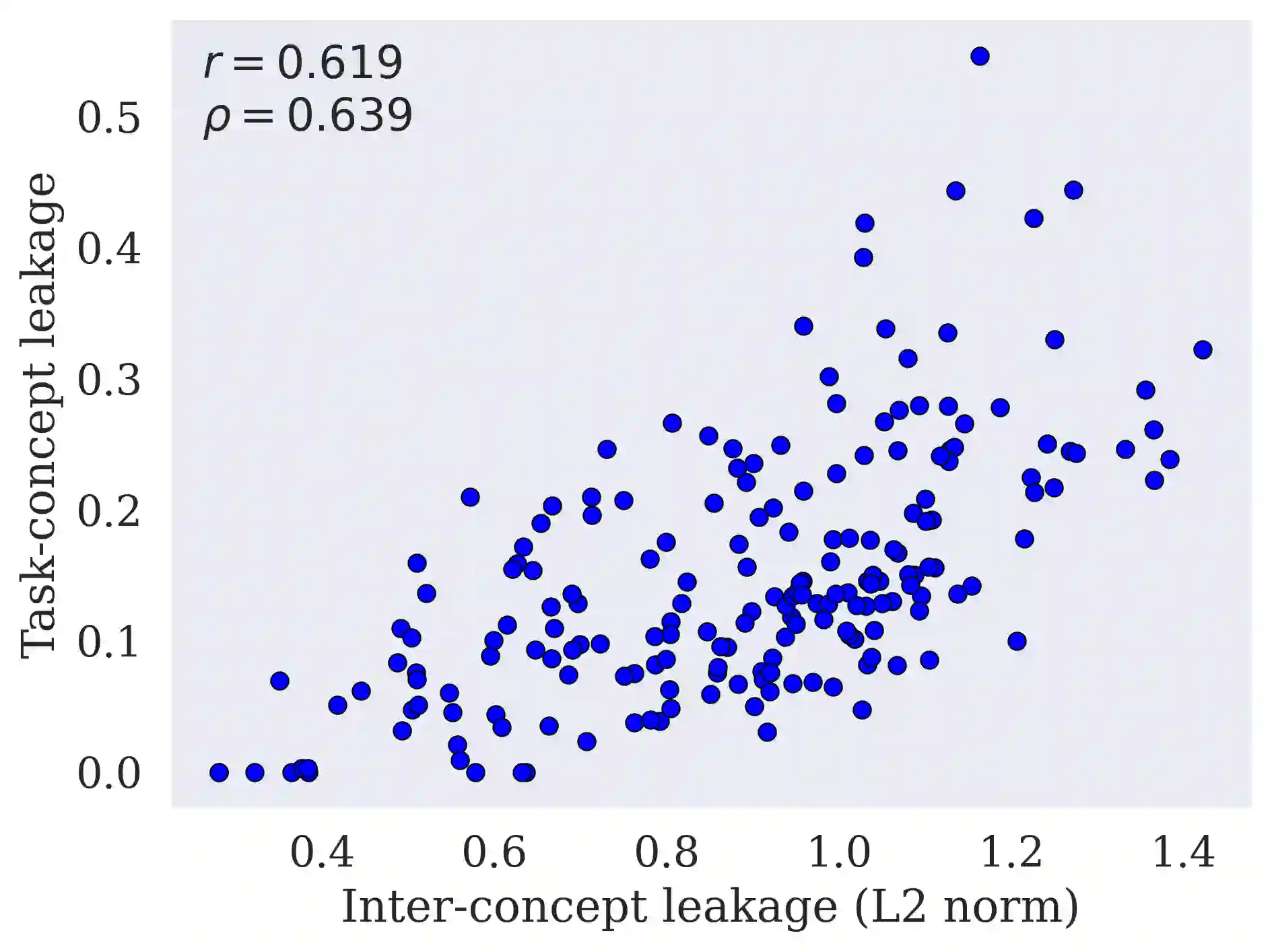
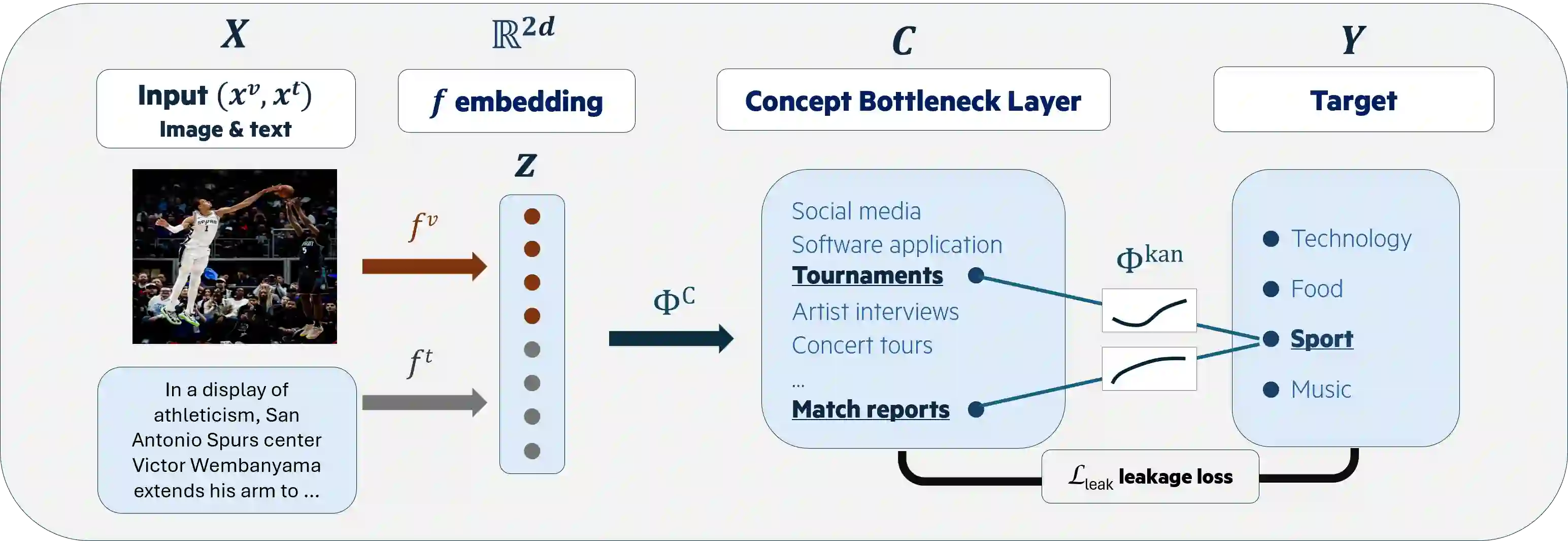
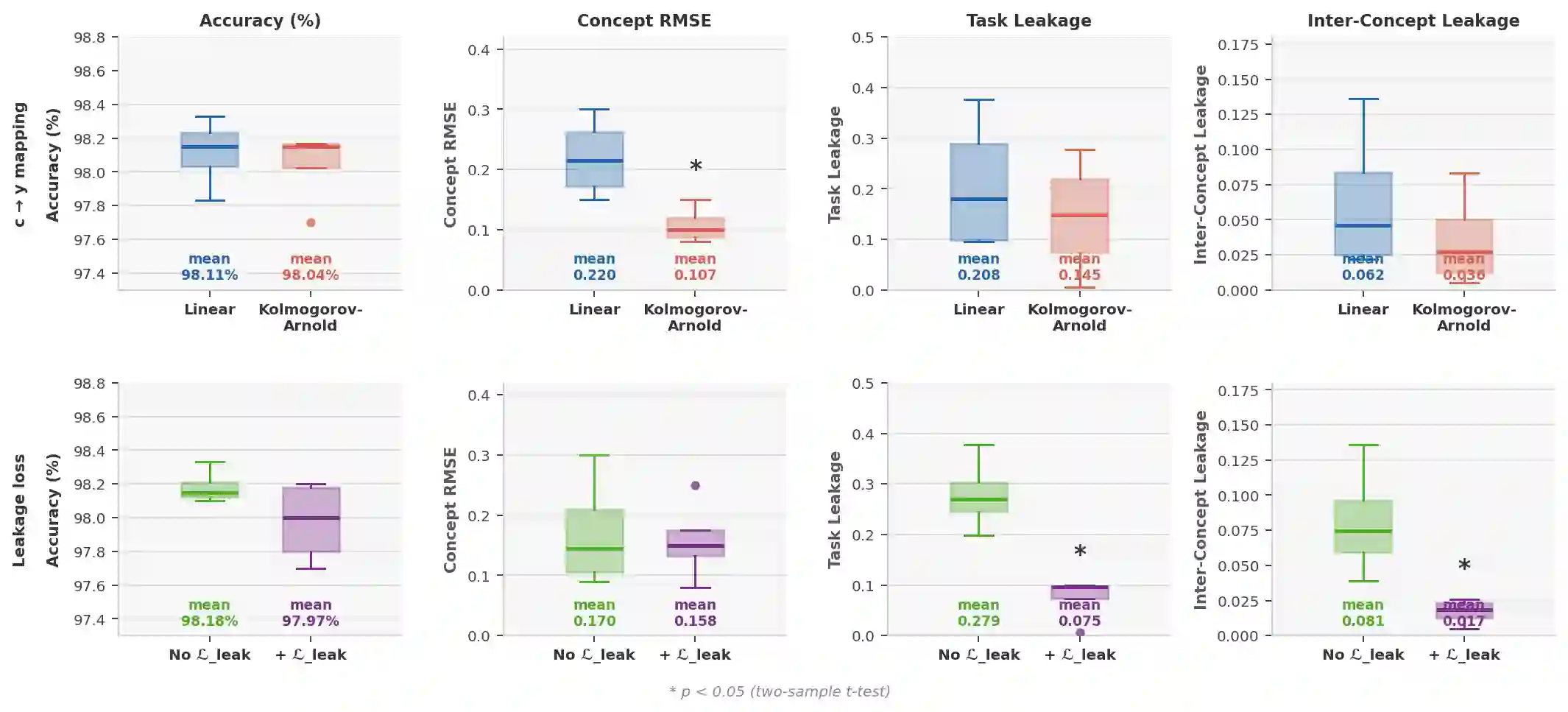
Concept Bottleneck Models (CBMs) are interpretable models that route predictions through a layer of human-interpretable concepts. While widely studied in vision and, more recently, in NLP, CBMs remain largely unexplored in multimodal settings. For their explanations to be faithful, CBMs must satisfy two conditions: concepts must be properly detected, and concept representations must encode only their intended semantics, without smuggling extraneous task-relevant or inter-concept information into final predictions, a phenomenon known as leakage. Existing approaches treat concept detection and leakage mitigation as separate problems, and typically improve one at the expense of predictive accuracy. In this work, we introduce f-CBM, a faithful multimodal CBM framework built on a vision-language backbone that jointly targets both aspects through two complementary strategies: a differentiable leakage loss to mitigate leakage, and a Kolmogorov-Arnold Network prediction head that provides sufficient expressiveness to improve concept detection. Experiments demonstrate that f-CBM achieves the best trade-off between task accuracy, concept detection, and leakage reduction, while applying seamlessly to both image and text or text-only datasets, making it versatile across modalities.
翻译:概念瓶颈模型(CBMs)是一种可解释的模型,其通过一层人类可解释的概念层来传递预测。尽管在视觉领域已得到广泛研究,最近也在自然语言处理领域有所探索,但CBMs在多模态场景中很大程度上仍未得到充分研究。为了使其解释具有可信性,CBMs必须满足两个条件:概念必须被正确检测,且概念表示必须仅编码其预期语义,而不应将额外的任务相关信息或概念间信息“泄露”到最终预测中,这种现象被称为泄漏。现有方法将概念检测和泄漏缓解视为两个独立的问题,并且通常以牺牲预测准确性为代价来改进其中一方面。在本工作中,我们提出了f-CBM,一个基于视觉-语言主干网络构建的可信多模态CBM框架,它通过两种互补策略共同解决这两个方面:一种可微分的泄漏损失函数来缓解泄漏,以及一个提供足够表达能力以改进概念检测的Kolmogorov-Arnold Network预测头。实验表明,f-CBM在任务准确性、概念检测和泄漏减少之间实现了最佳权衡,同时可无缝应用于图像和文本或纯文本数据集,使其具备跨模态的通用性。