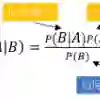
We study the certifiable robustness of ML classifiers on dirty datasets that could contain missing values. A test point is certifiably robust for an ML classifier if the classifier returns the same prediction for that test point, regardless of which cleaned version (among exponentially many) of the dirty dataset the classifier is trained on. In this paper, we show theoretically that for Naive Bayes Classifiers (NBC) over dirty datasets with missing values: (i) there exists an efficient polynomial time algorithm to decide whether multiple input test points are all certifiably robust over a dirty dataset; and (ii) the data poisoning attack, which aims to make all input test points certifiably non-robust by inserting missing cells to the clean dataset, is in polynomial time for single test points but NP-complete for multiple test points. Extensive experiments demonstrate that our algorithms are efficient and outperform existing baselines.
翻译:本研究探讨了机器学习分类器在可能包含缺失值的脏数据集上的可验证鲁棒性。若某测试点在分类器上的预测结果保持不变,无论分类器是在脏数据集(存在指数级数量的清洗版本)的哪个清洗版本上训练得到,则该测试点对该分类器具有可验证鲁棒性。本文从理论上证明,对于处理含缺失值脏数据集的朴素贝叶斯分类器:(i) 存在一种高效的多项式时间算法,可判定多个输入测试点是否在脏数据集上均具有可验证鲁棒性;(ii) 数据投毒攻击(旨在通过向干净数据集插入缺失单元格使所有输入测试点均失去可验证鲁棒性)对单个测试点可在多项式时间内完成,但对多个测试点则属于NP完全问题。大量实验表明,我们提出的算法具有高效性,且性能优于现有基线方法。