
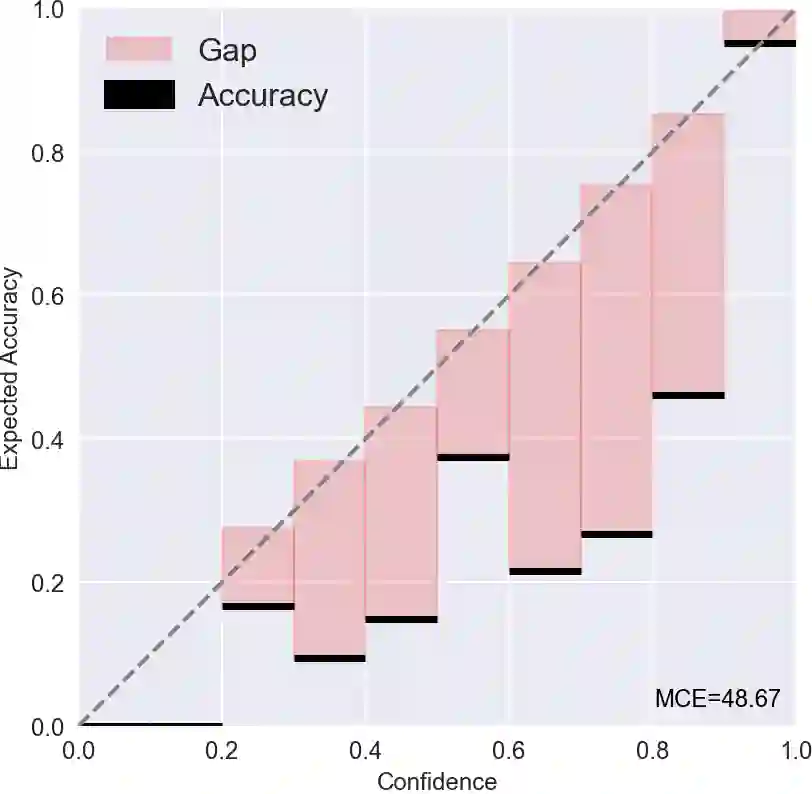
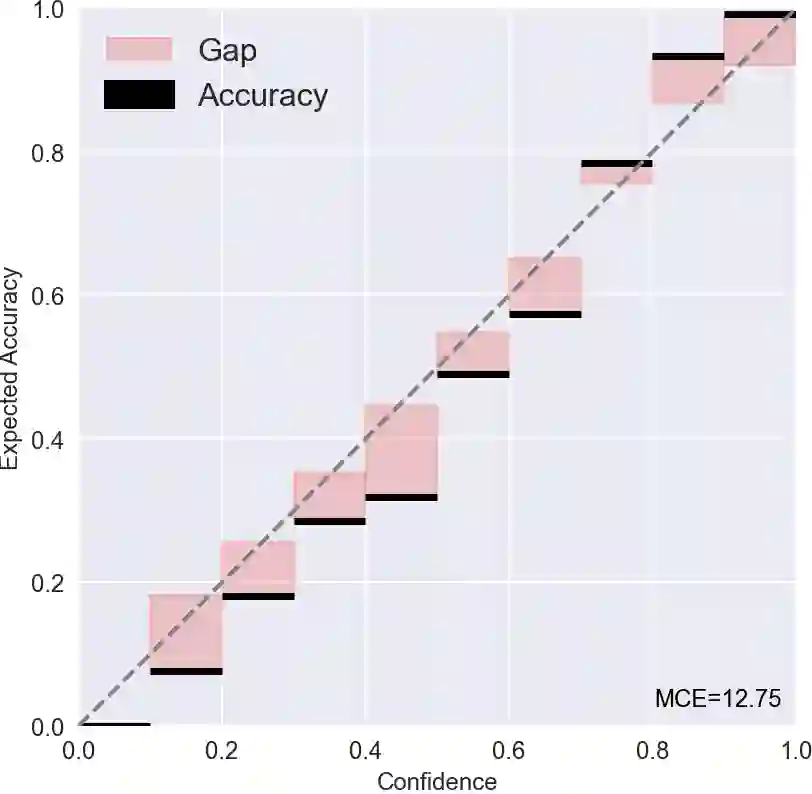
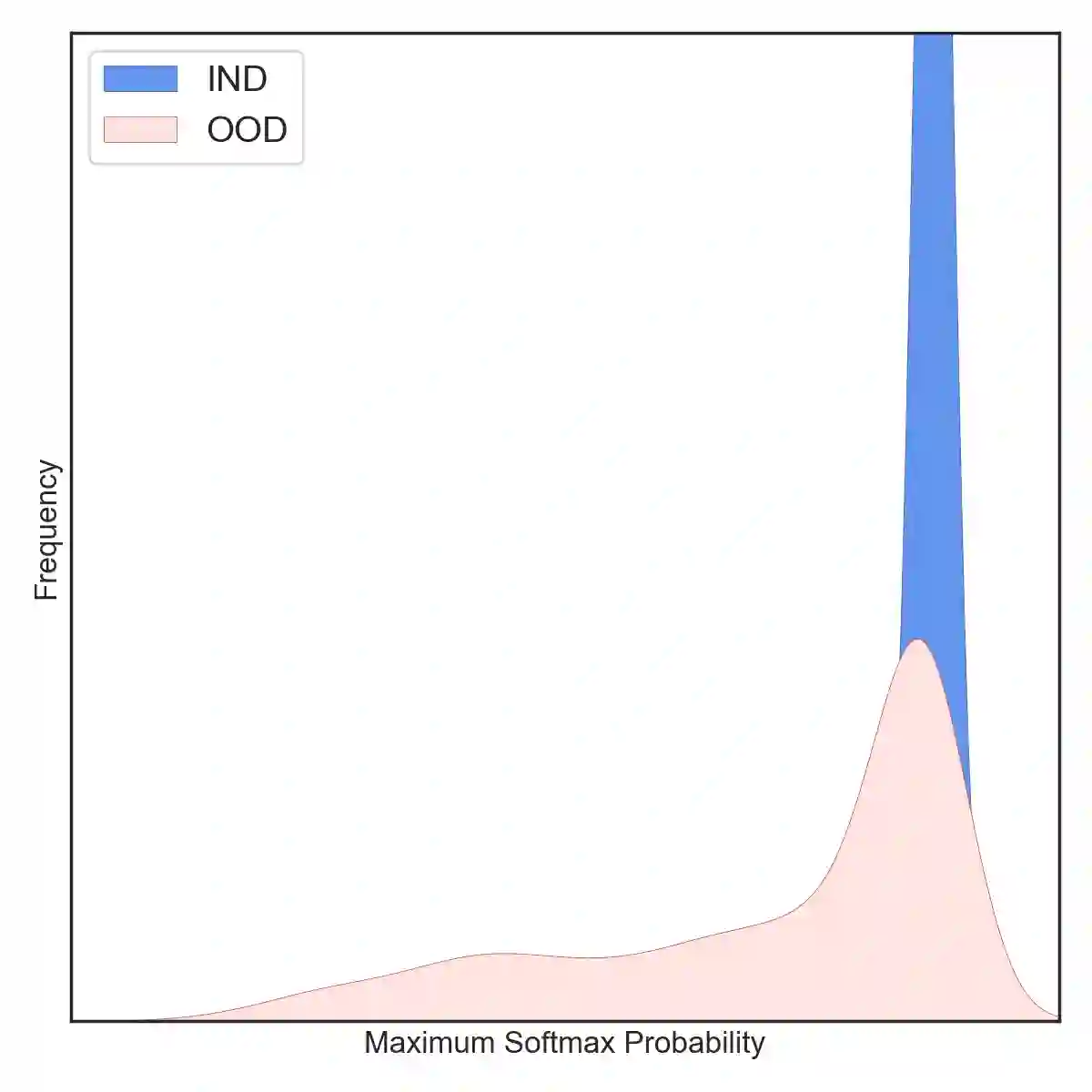
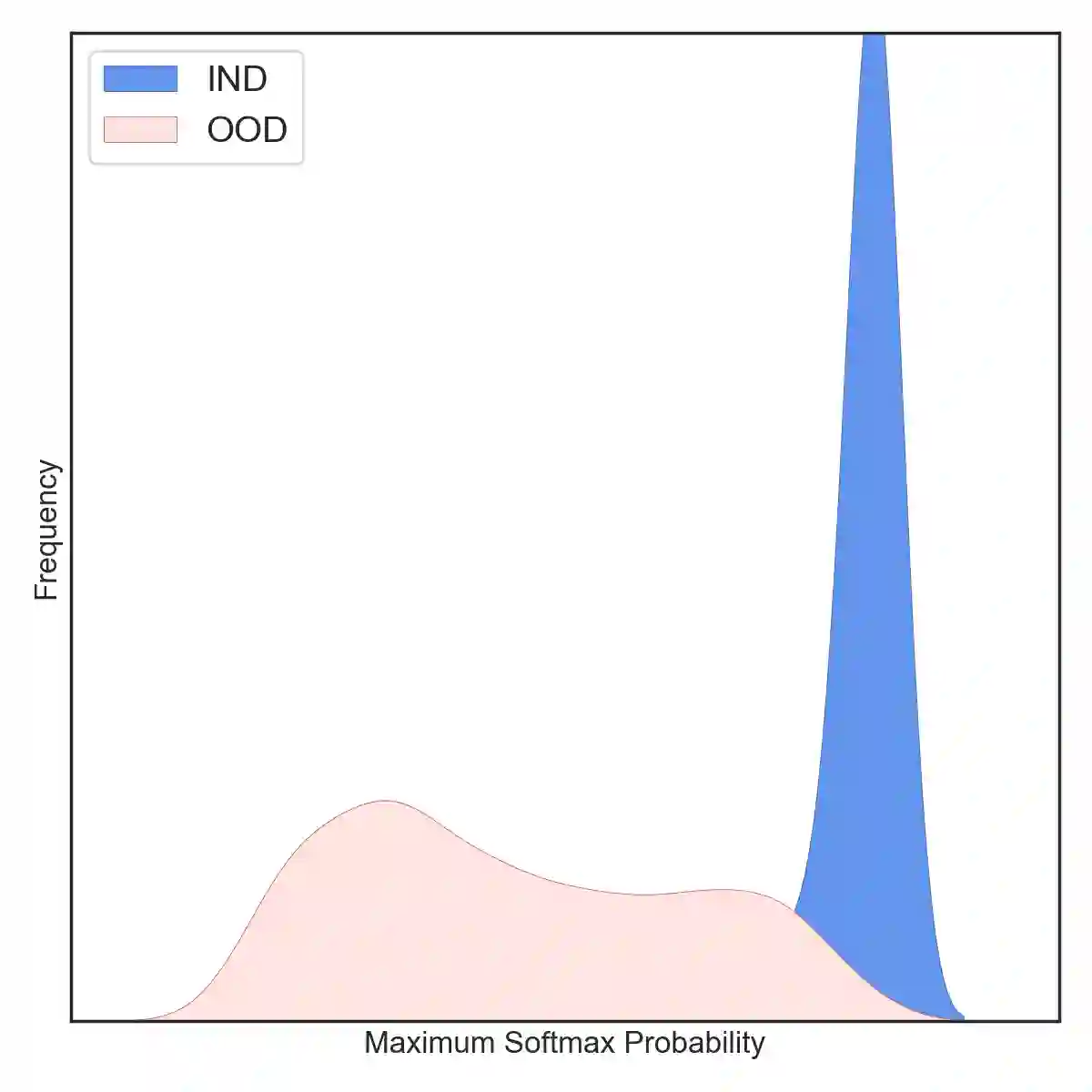
Most existing methods of Out-of-Domain (OOD) intent classification rely on extensive auxiliary OOD corpora or specific training paradigms. However, they are underdeveloped in the underlying principle that the models should have differentiated confidence in In- and Out-of-domain intent. In this work, we shed light on the fundamental cause of model overconfidence on OOD and demonstrate that calibrated subnetworks can be uncovered by pruning the overparameterized model. Calibrated confidence provided by the subnetwork can better distinguish In- and Out-of-domain, which can be a benefit for almost all post hoc methods. In addition to bringing fundamental insights, we also extend the Lottery Ticket Hypothesis to open-world scenarios. We conduct extensive experiments on four real-world datasets to demonstrate our approach can establish consistent improvements compared with a suite of competitive baselines.
翻译:大多数现有的域外意图分类方法依赖于大量辅助的域外语料库或特定的训练范式。然而,它们在模型应对域内和域外意图时应具有差异化置信度的基本原理方面尚未得到充分发展。本研究揭示了模型对域外样本过度自信的根本原因,并证明通过剪枝过参数化模型可以揭示经过校准的子网络。子网络提供的校准置信度能更好地区分域内与域外样本,这一特性几乎适用于所有后处理方法。除提供基本原理层面的洞见外,我们还将彩票假说扩展至开放世界场景。通过在四个真实数据集上开展广泛实验,我们证明该方法相较于一系列强基线模型能够实现持续性的性能提升。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


