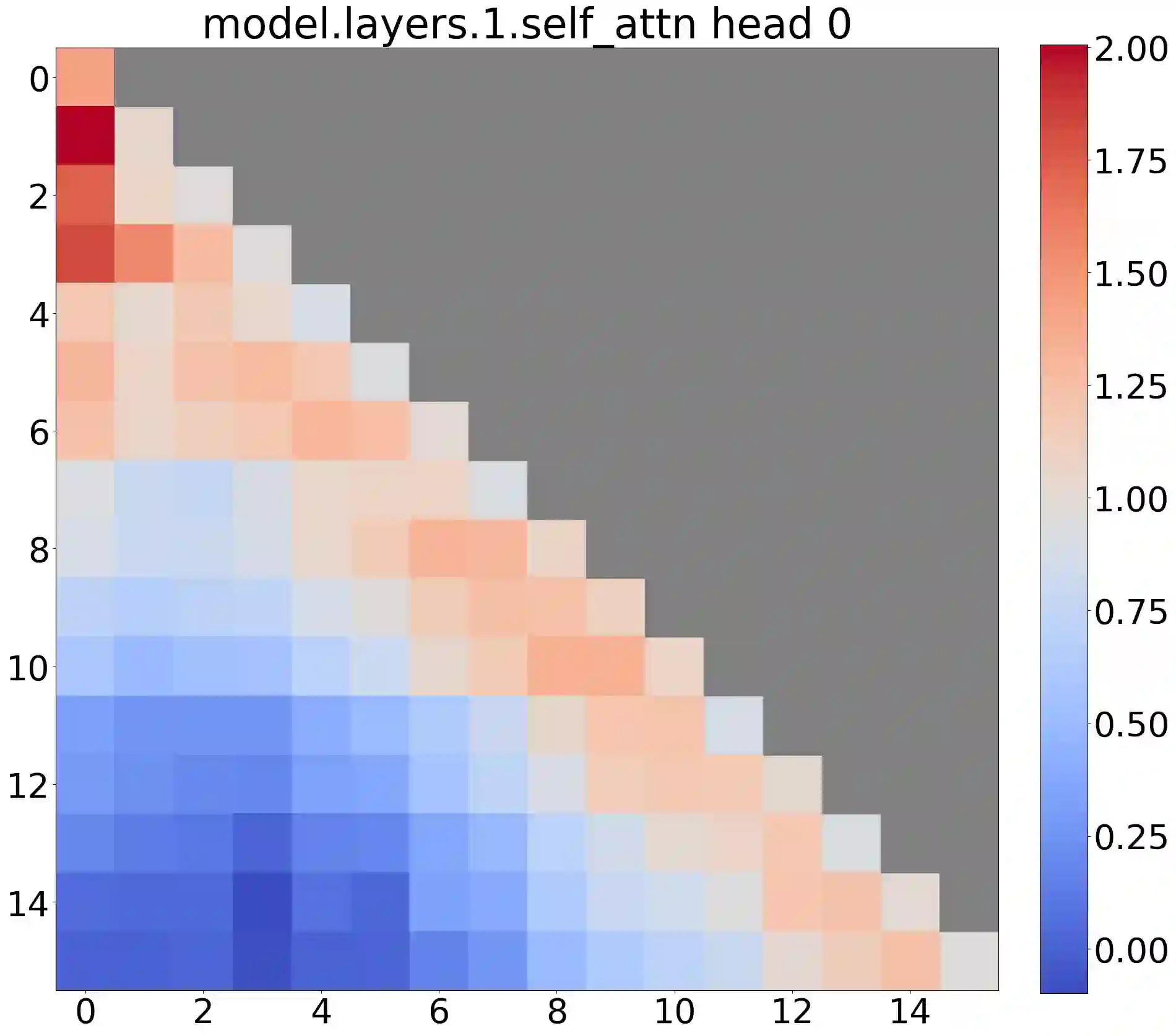
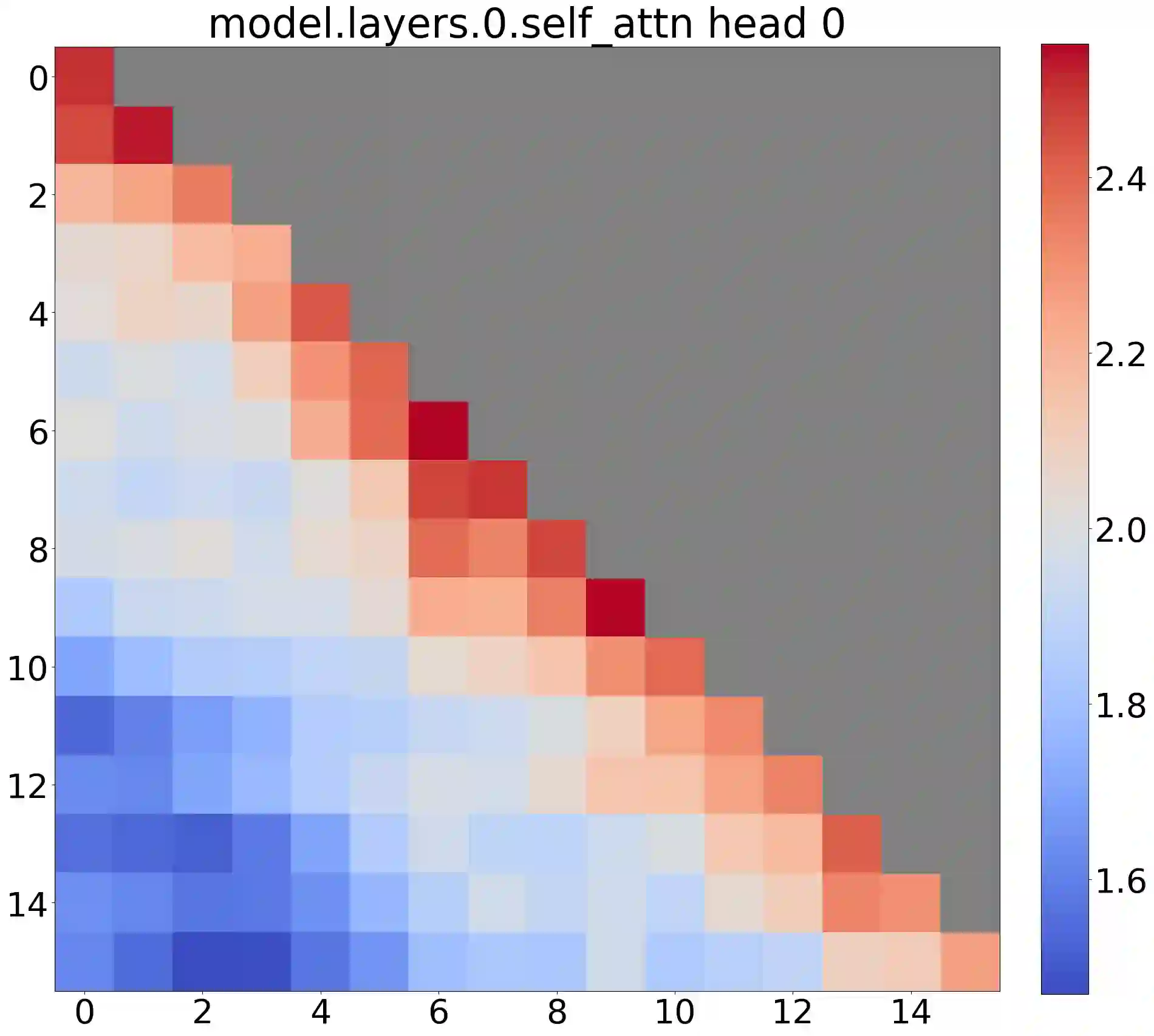
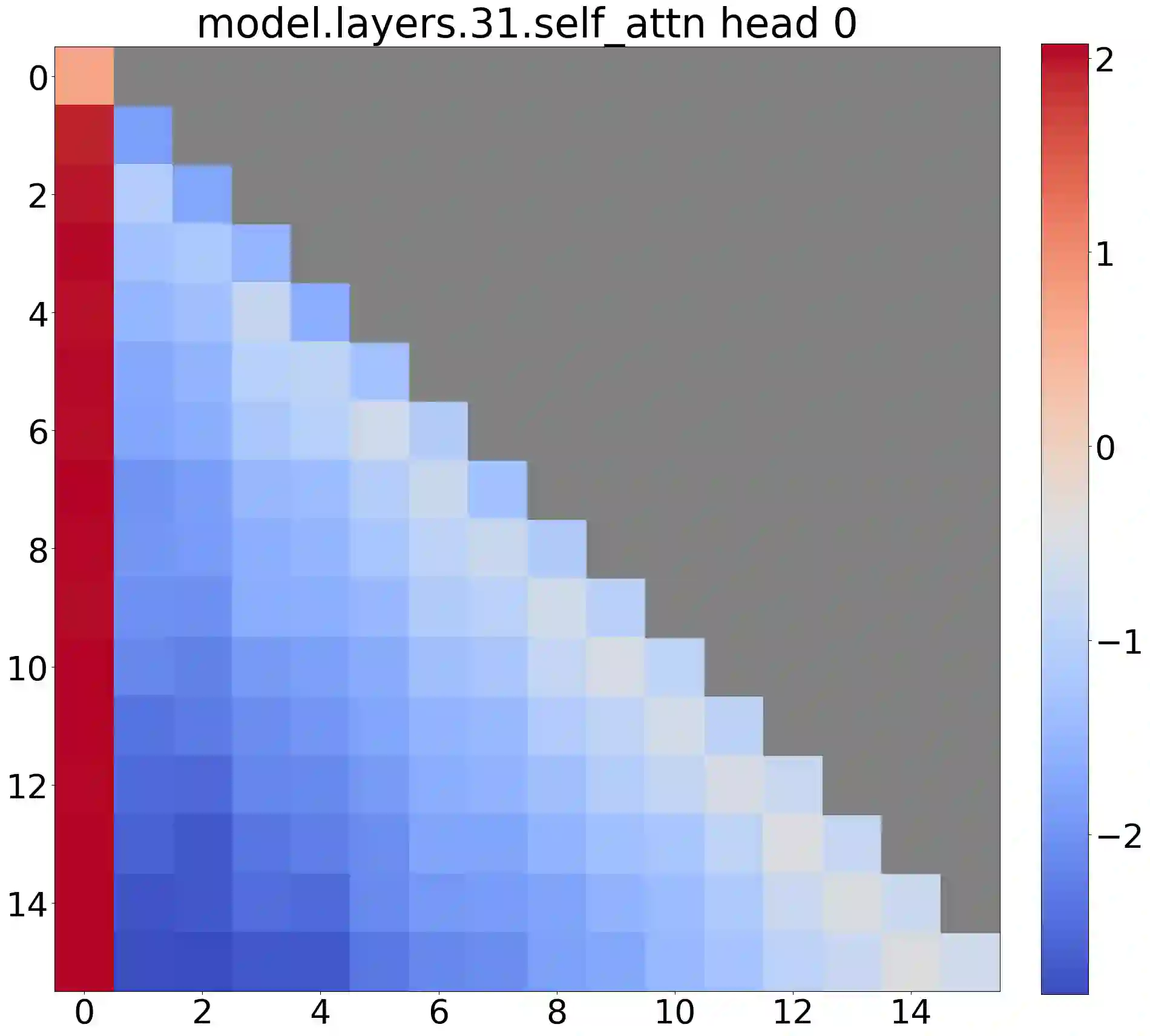
Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during the decoding stage, caching previous tokens' Key and Value states (KV) consumes extensive memory. Secondly, popular LLMs cannot generalize to longer texts than the training sequence length. Window attention, where only the most recent KVs are cached, is a natural approach -- but we show that it fails when the text length surpasses the cache size. We observe an interesting phenomenon, namely attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention. In this paper, we first demonstrate that the emergence of attention sink is due to the strong attention scores towards initial tokens as a ``sink'' even if they are not semantically important. Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence lengths without any fine-tuning. We show that StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more. In addition, we discover that adding a placeholder token as a dedicated attention sink during pre-training can further improve streaming deployment. In streaming settings, StreamingLLM outperforms the sliding window recomputation baseline by up to 22.2x speedup. Code and datasets are provided at https://github.com/mit-han-lab/streaming-llm.
翻译:在流式应用(如多轮对话)中部署大型语言模型(LLMs)以处理长时交互任务具有迫切需求,但面临两大挑战。首先,解码阶段缓存历史词元的键值对(KV)会消耗大量内存。其次,主流LLMs无法泛化到超过训练序列长度的文本。采用仅缓存最近KVs的窗口注意力虽属自然方案,但我们发现当文本长度超过缓存大小时该方法会失效。我们观察到一种有趣现象——注意力汇聚,即保留初始词元的KV可大幅恢复窗口注意力性能。本文首先证明注意力汇聚的产生源于模型对初始词元赋予的强注意力分数,即使这些词元不具有语义重要性,它们仍充当了注意力“汇聚点”。基于上述分析,我们提出StreamingLLM高效框架,使经过有限长度注意力窗口训练的LLMs无需微调即可泛化到无限序列长度。实验表明,StreamingLLM可支持Llama-2、MPT、Falcon和Pythia等模型对高达400万及以上词元进行稳定高效的语言建模。此外,我们发现在预训练阶段插入占位符词元作为专用注意力汇聚点可进一步提升流式部署性能。在流式场景中,StreamingLLM相较滑动窗口重计算基线方法实现了最高22.2倍加速。代码与数据集已开源至https://github.com/mit-han-lab/streaming-llm。