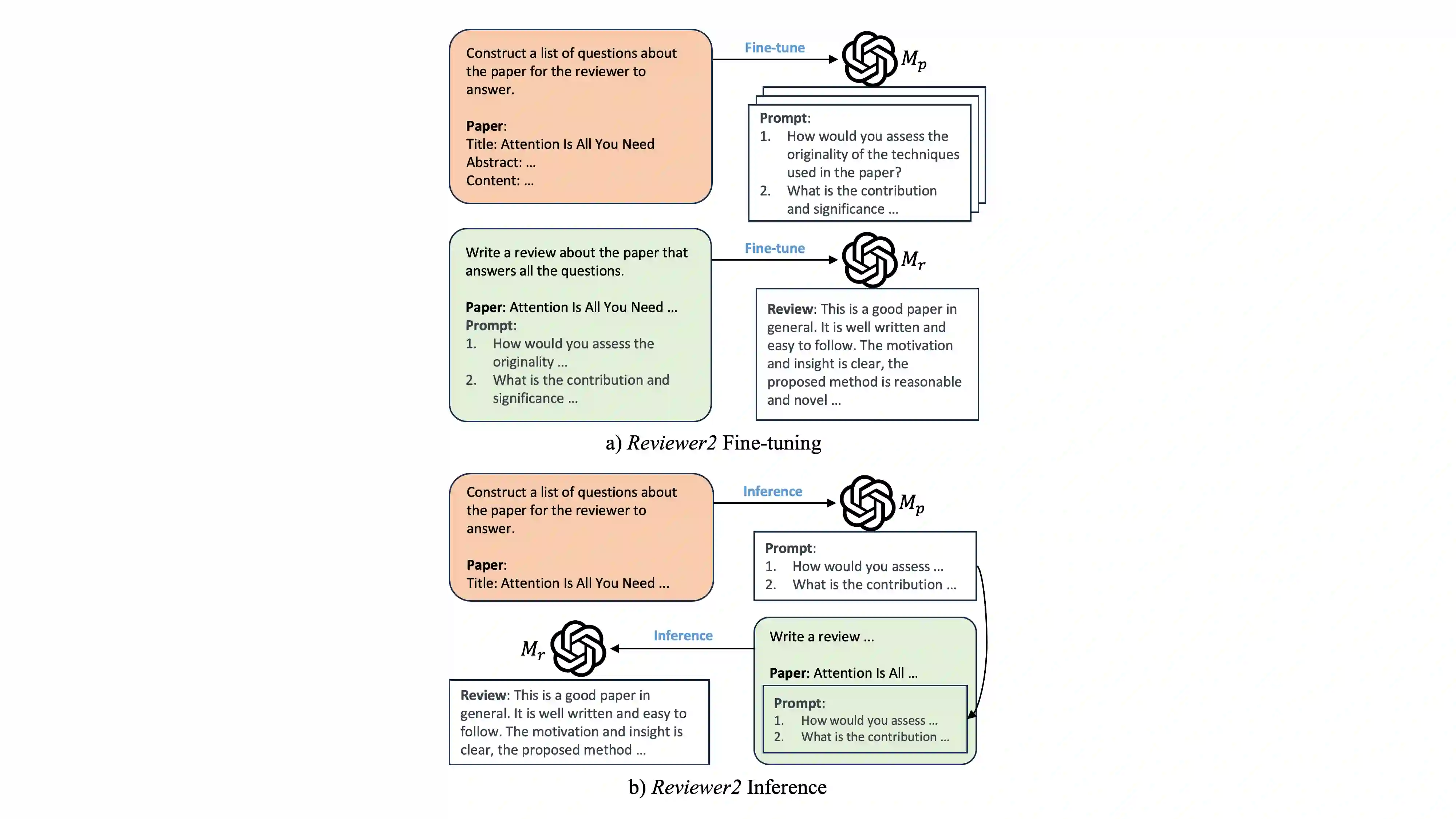
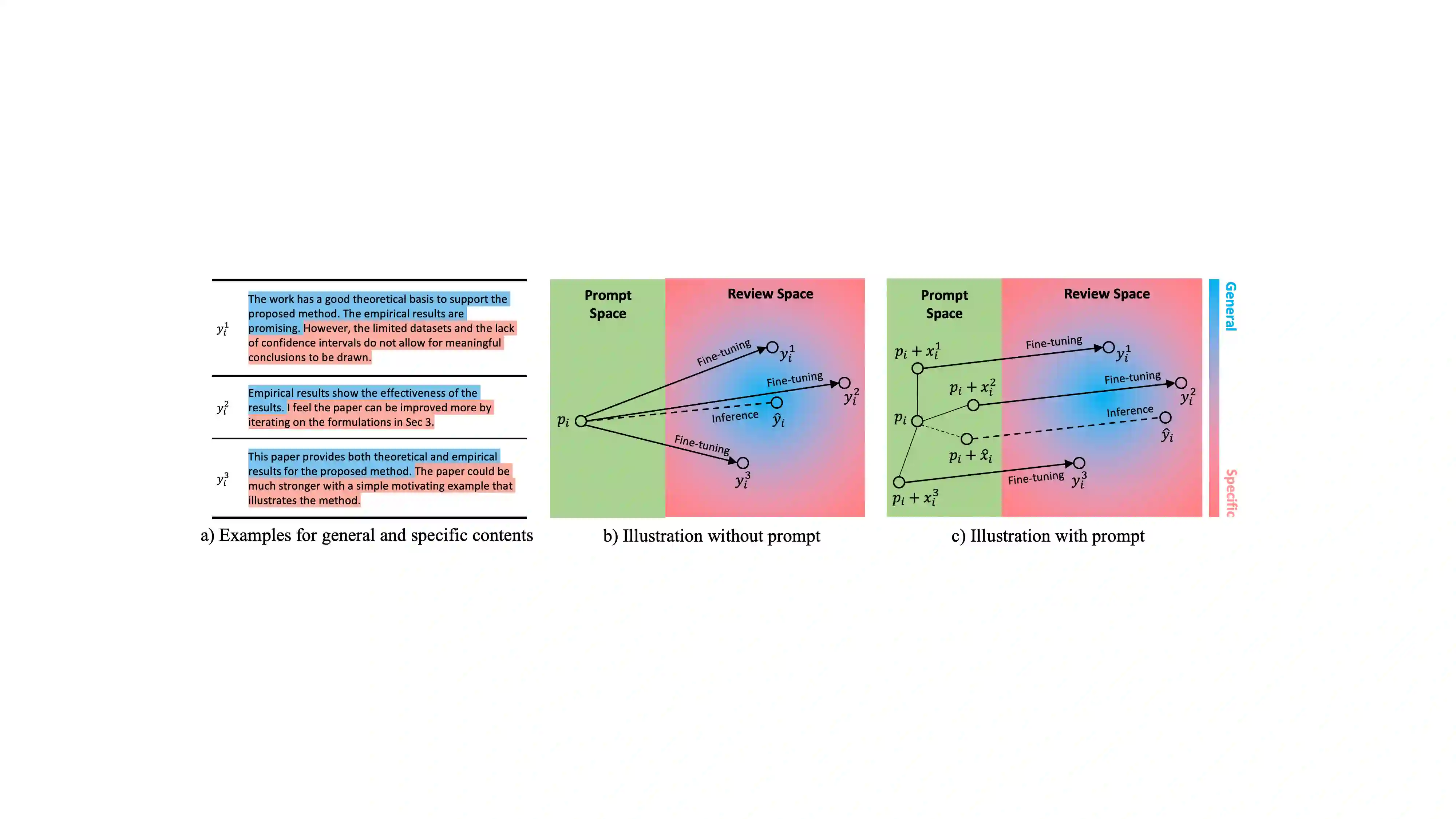
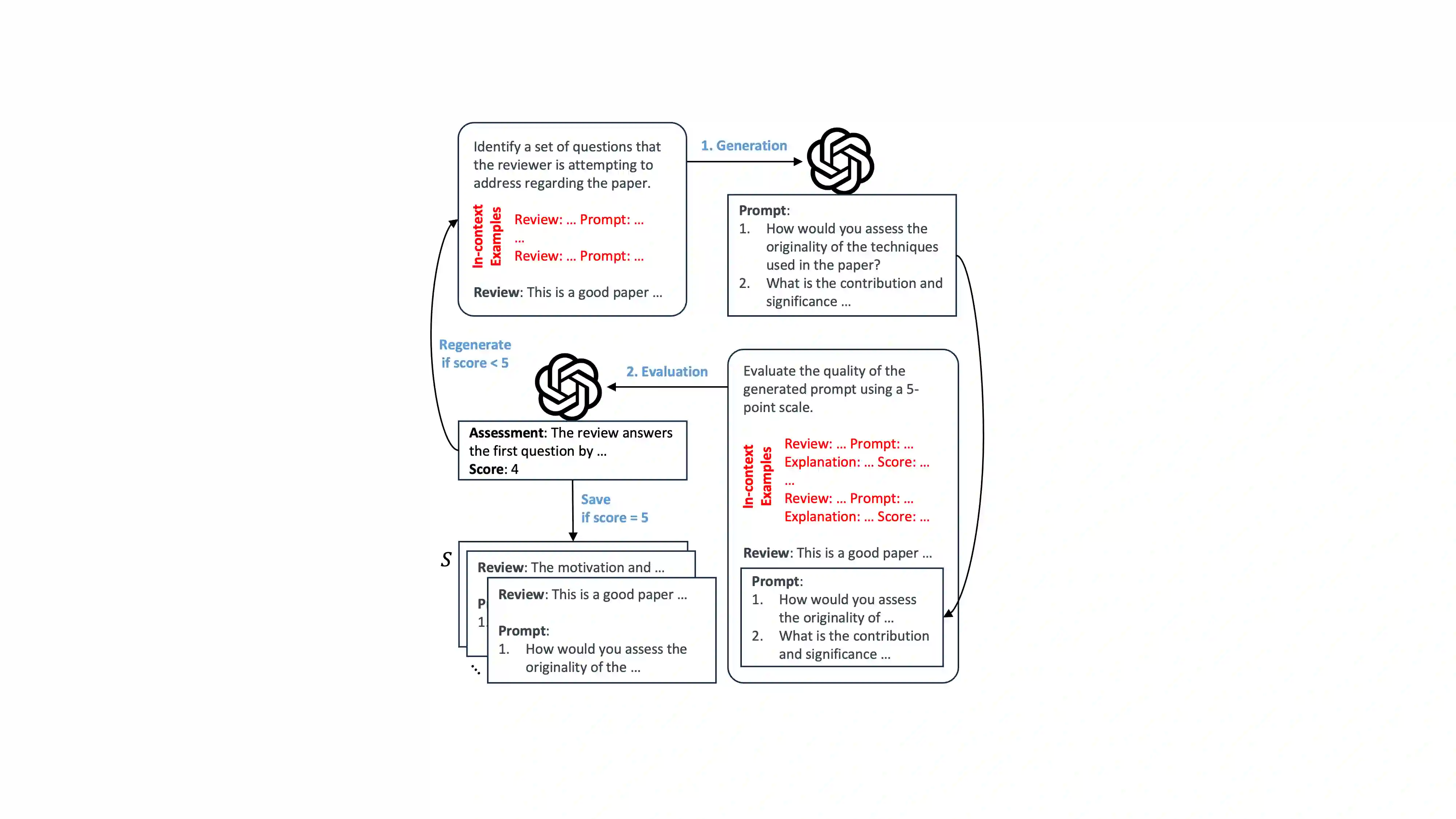
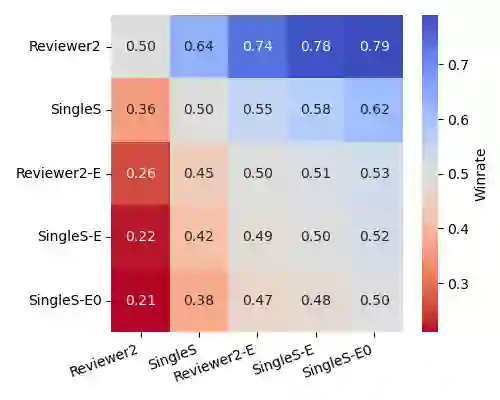
Recent developments in LLMs offer new opportunities for assisting authors in improving their work. In this paper, we envision a use case where authors can receive LLM-generated reviews that uncover weak points in the current draft. While initial methods for automated review generation already exist, these methods tend to produce reviews that lack detail, and they do not cover the range of opinions that human reviewers produce. To address this shortcoming, we propose an efficient two-stage review generation framework called Reviewer2. Unlike prior work, this approach explicitly models the distribution of possible aspects that the review may address. We show that this leads to more detailed reviews that better cover the range of aspects that human reviewers identify in the draft. As part of the research, we generate a large-scale review dataset of 27k papers and 99k reviews that we annotate with aspect prompts, which we make available as a resource for future research.
翻译:近期大语言模型的发展为协助作者改进其工作提供了新的机遇。本文设想一种应用场景,作者能够接收由大语言模型生成的评审意见,以揭示当前稿件中的薄弱环节。尽管自动评审生成方法已初步存在,但这些方法往往产生缺乏细节的评审,且未能涵盖人类评审者所提出的多元观点。为弥补这一不足,我们提出一个高效的两阶段评审生成框架,称为Reviewer2。与先前工作不同,该方法显式建模了评审可能涉及方面的概率分布。我们证明,这种方法能够产生更详细的评审,更好地覆盖人类评审者在稿件中识别的各方面内容。作为研究的一部分,我们构建了一个包含2.7万篇论文和9.9万条评审的大规模评审数据集,并对其进行了方面提示标注,该数据集将作为资源开放以供未来研究使用。