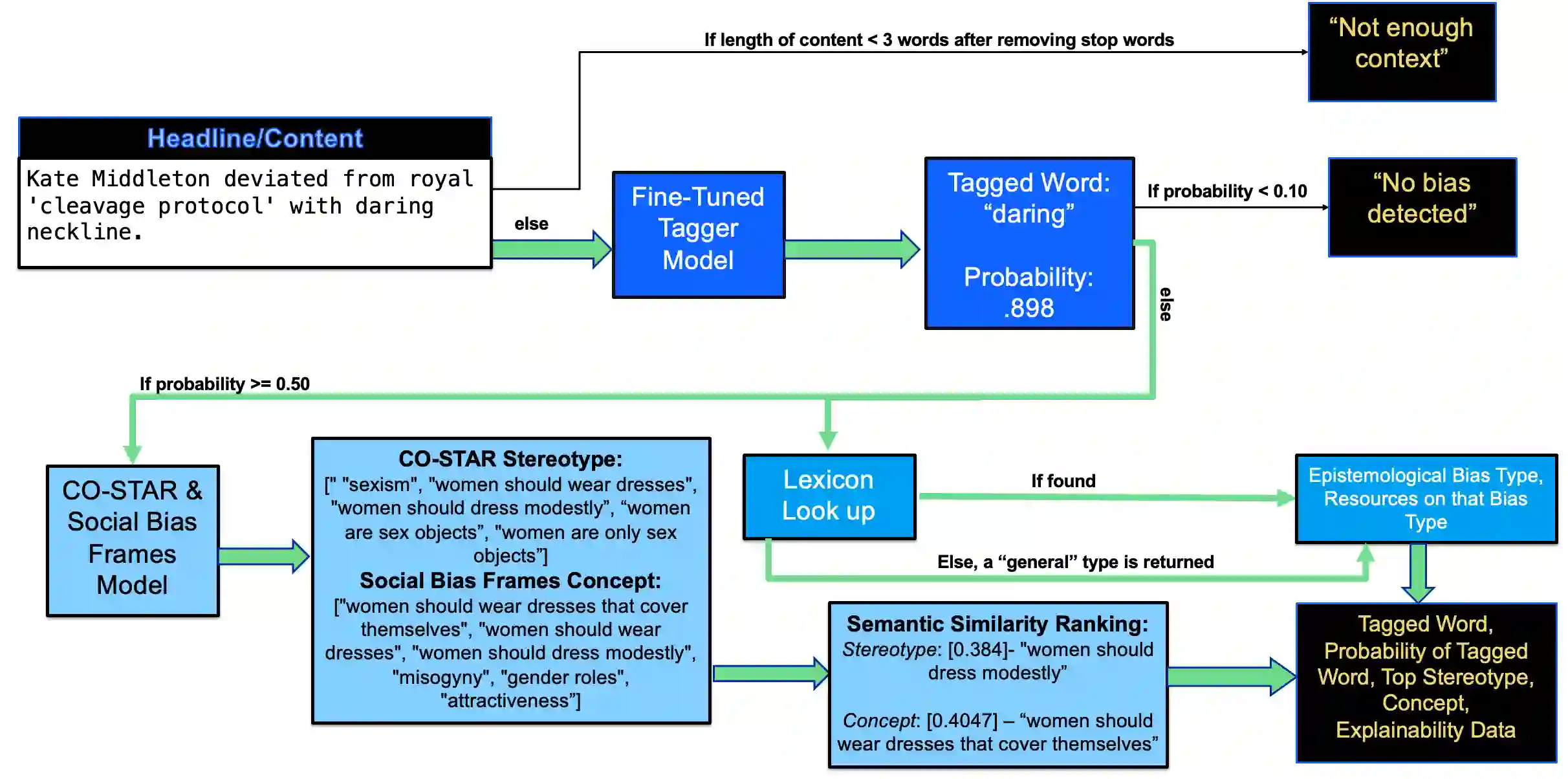
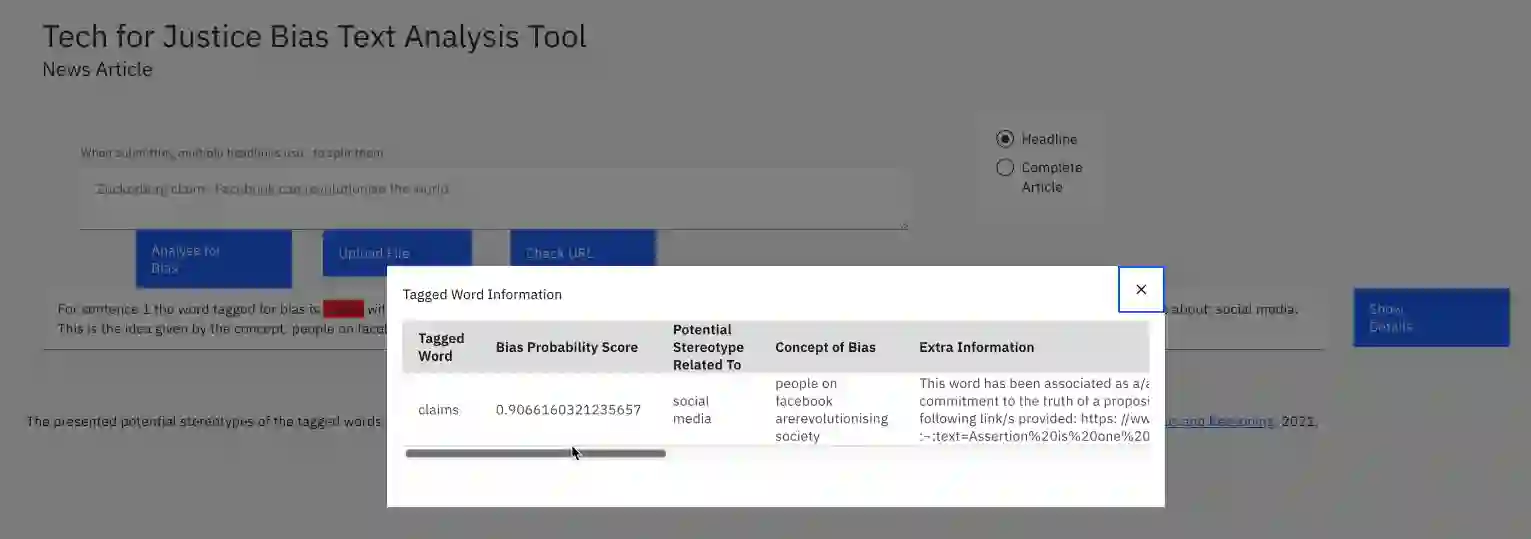
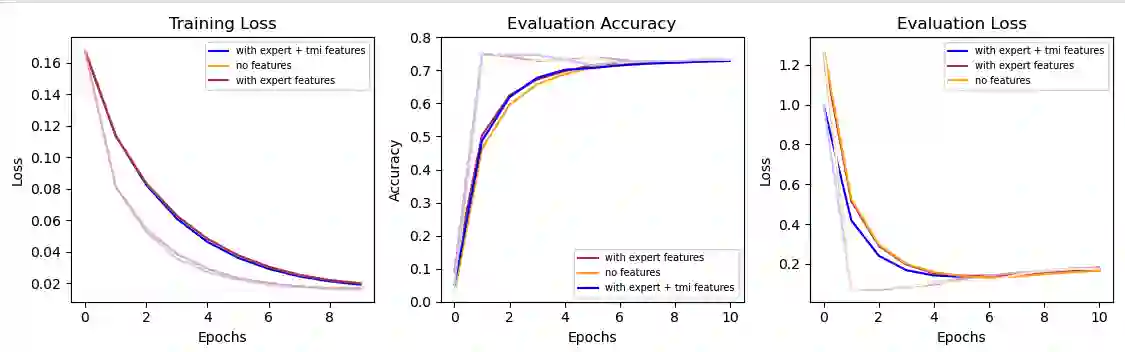
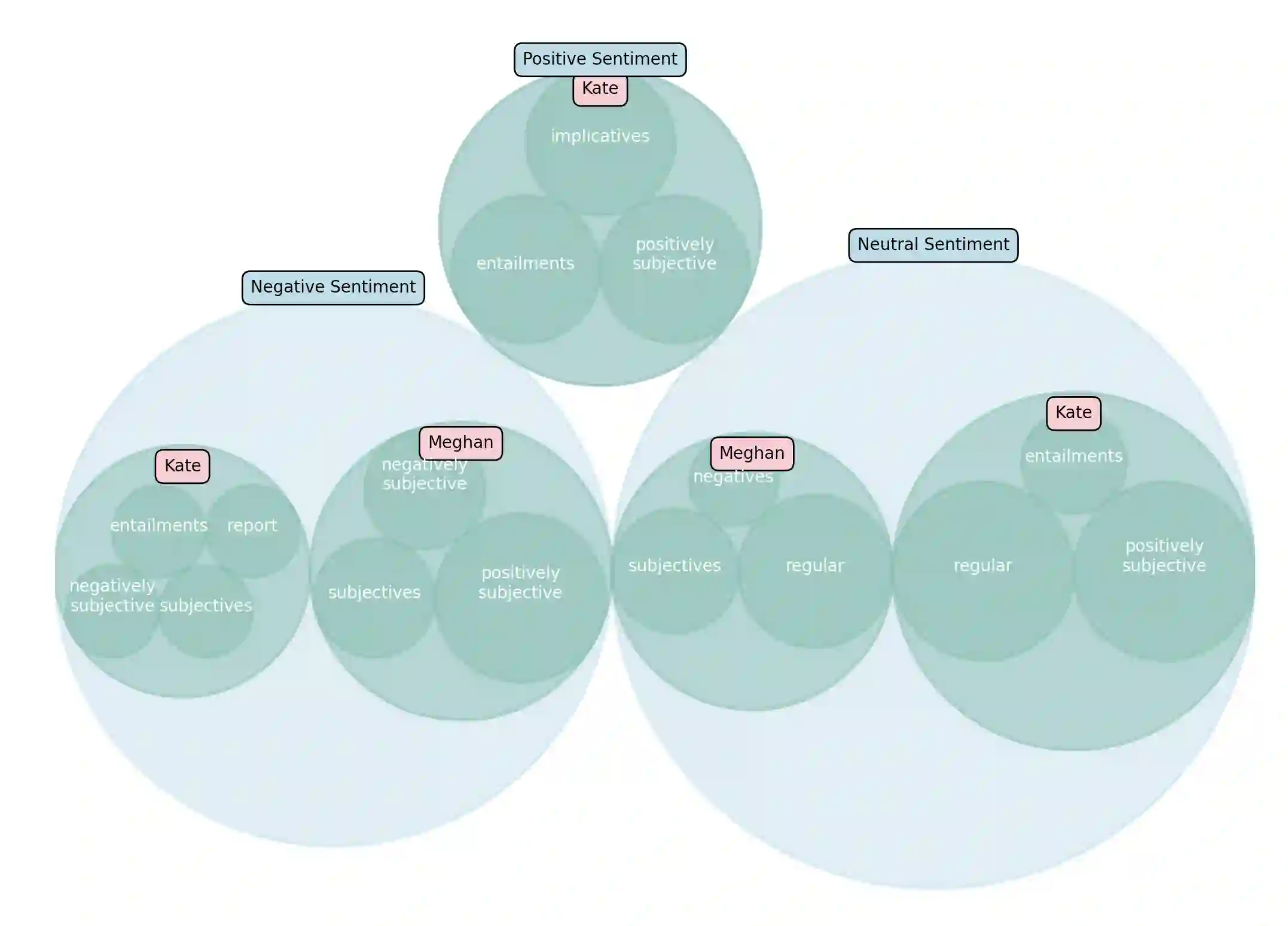
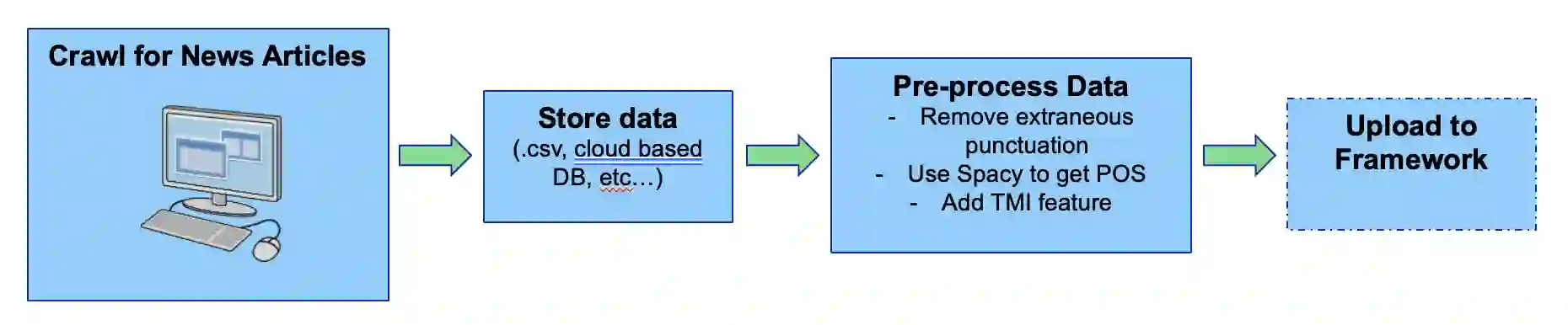
Injustice occurs when someone experiences unfair treatment or their rights are violated and is often due to the presence of implicit biases and prejudice such as stereotypes. The automated identification of injustice in text has received little attention, due in part to the fact that underlying implicit biases or stereotypes are rarely explicitly stated and that instances often occur unconsciously due to the pervasive nature of prejudice in society. Here, we describe a novel framework that combines the use of a fine-tuned BERT-based bias detection model, two stereotype detection models, and a lexicon-based approach to show that epistemological biases (i.e., words, which presupposes, entails, asserts, hedges, or boosts text to erode or assert a person's capacity as a knower) can assist with the automatic detection of injustice in text. The news media has many instances of injustice (i.e. discriminatory narratives), thus it is our use case here. We conduct and discuss an empirical qualitative research study which shows how the framework can be applied to detect injustices, even at higher volumes of data.
翻译:当个体遭受不公平待遇或其权利受到侵犯时,便会产生不公正现象,这通常源于隐性偏见和刻板印象等先入为主的观念。文本中不公正现象的自动识别研究尚未得到充分关注,部分原因在于潜在的隐性偏见或刻板印象很少被明确表述,且由于社会偏见的普遍性,这类现象往往在无意识中发生。本文提出一种新颖的框架,通过结合微调的BERT偏见检测模型、两种刻板印象检测模型以及基于词典的方法,证明认识论偏见(即通过预设、蕴含、断言、模糊化或强化等语言手段侵蚀或确立个体认知者地位的词汇)能够辅助文本中不公正现象的自动检测。新闻媒体中存在大量不公正案例(即歧视性叙事),因此我们将其作为研究场景。我们开展并讨论了一项实证质性研究,表明该框架即使在处理大规模数据时仍能有效检测不公正现象。