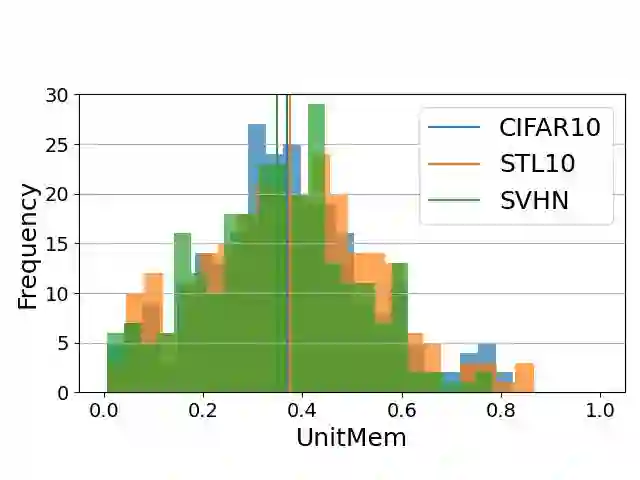
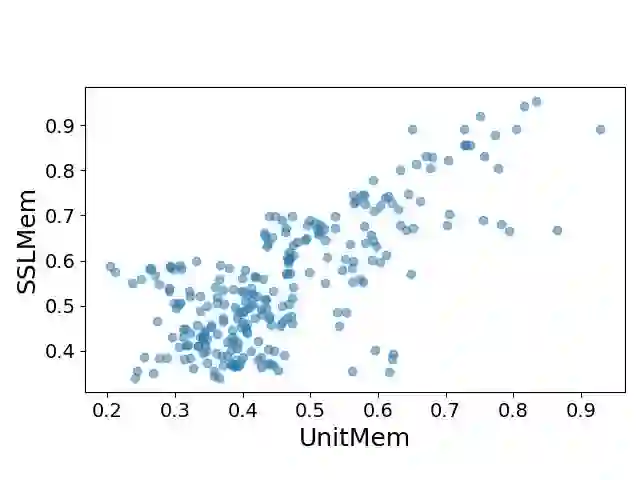
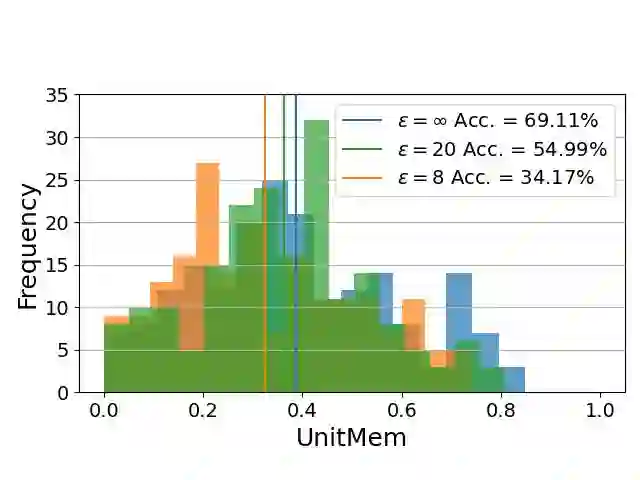
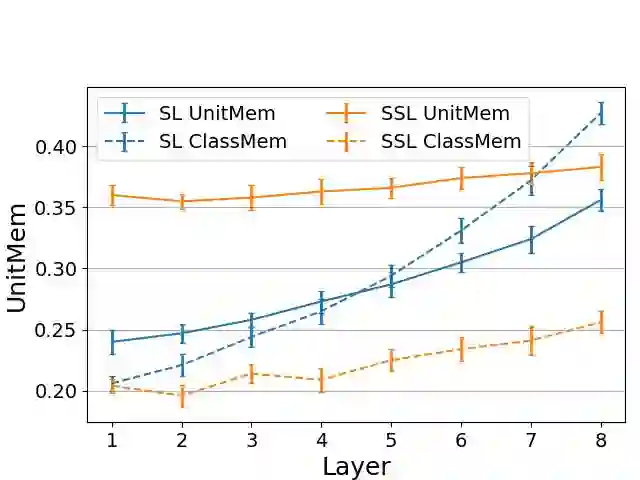
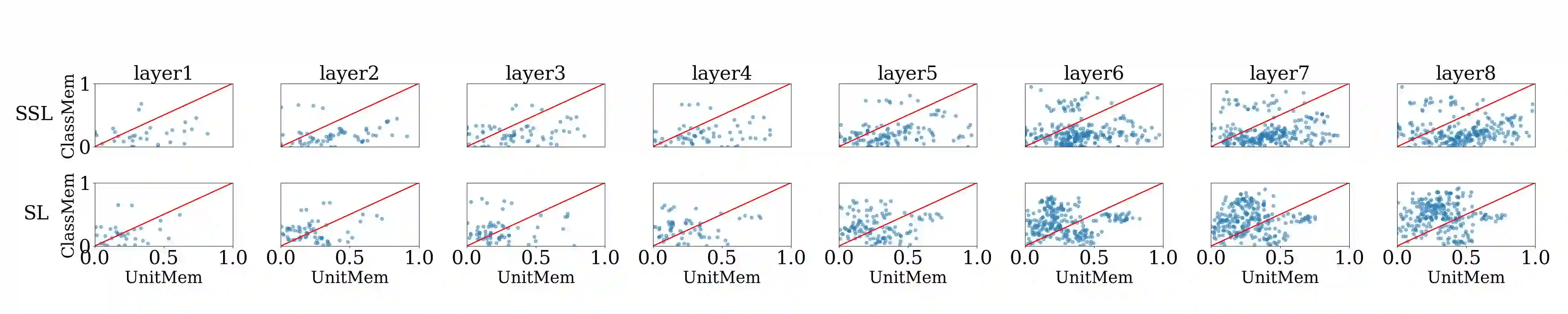
Recent work on studying memorization in self-supervised learning (SSL) suggests that even though SSL encoders are trained on millions of images, they still memorize individual data points. While effort has been put into characterizing the memorized data and linking encoder memorization to downstream utility, little is known about where the memorization happens inside SSL encoders. To close this gap, we propose two metrics for localizing memorization in SSL encoders on a per-layer (layermem) and per-unit basis (unitmem). Our localization methods are independent of the downstream task, do not require any label information, and can be performed in a forward pass. By localizing memorization in various encoder architectures (convolutional and transformer-based) trained on diverse datasets with contrastive and non-contrastive SSL frameworks, we find that (1) while SSL memorization increases with layer depth, highly memorizing units are distributed across the entire encoder, (2) a significant fraction of units in SSL encoders experiences surprisingly high memorization of individual data points, which is in contrast to models trained under supervision, (3) atypical (or outlier) data points cause much higher layer and unit memorization than standard data points, and (4) in vision transformers, most memorization happens in the fully-connected layers. Finally, we show that localizing memorization in SSL has the potential to improve fine-tuning and to inform pruning strategies.
翻译:近期关于自监督学习(SSL)中记忆现象的研究表明,即使SSL编码器在数百万张图像上进行训练,它们仍会记忆单个数据点。尽管已有研究致力于描述被记忆数据的特征,并将编码器记忆与下游任务效用联系起来,但关于记忆发生在SSL编码器内部何处的问题仍知之甚少。为填补这一空白,我们提出了两种在SSL编码器中定位记忆的度量方法:基于层的记忆定位(layermem)和基于单元的记忆定位(unitmem)。我们的定位方法独立于下游任务,无需任何标签信息,且可通过单次前向传播完成。通过对在不同数据集上使用对比式与非对比式SSL框架训练的各种编码器架构(基于卷积和基于Transformer)进行记忆定位分析,我们发现:(1)虽然SSL记忆随网络层深度增加而增强,但高记忆单元分布在整个编码器中;(2)SSL编码器中存在显著比例的单元对单个数据点表现出惊人的高记忆度,这与监督训练模型形成鲜明对比;(3)非典型(或异常)数据点引发的层记忆和单元记忆远高于标准数据点;(4)在视觉Transformer中,大部分记忆发生在全连接层。最后,我们证明SSL记忆定位具有改进微调效果和为剪枝策略提供指导的潜力。