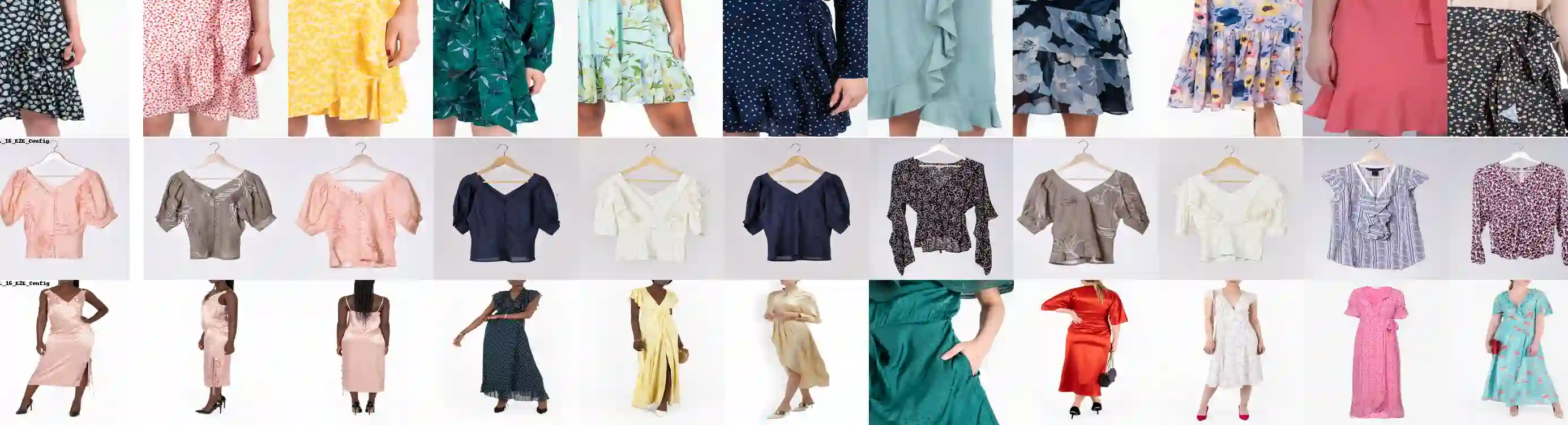
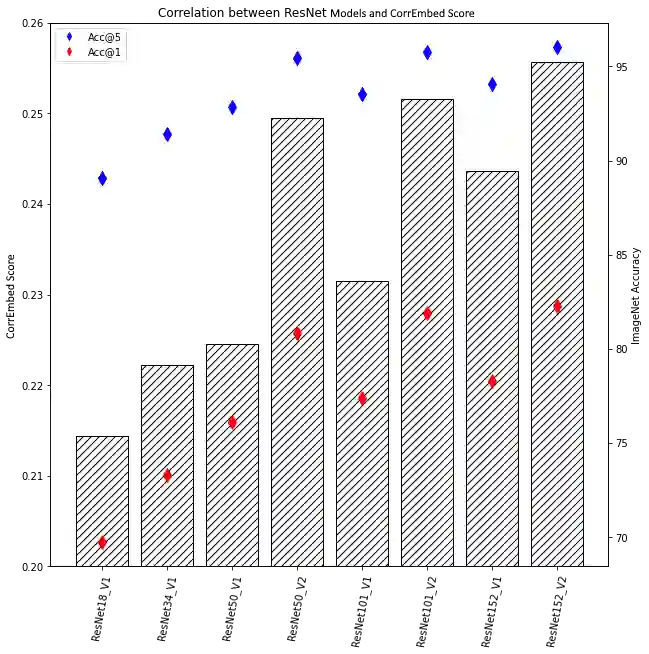
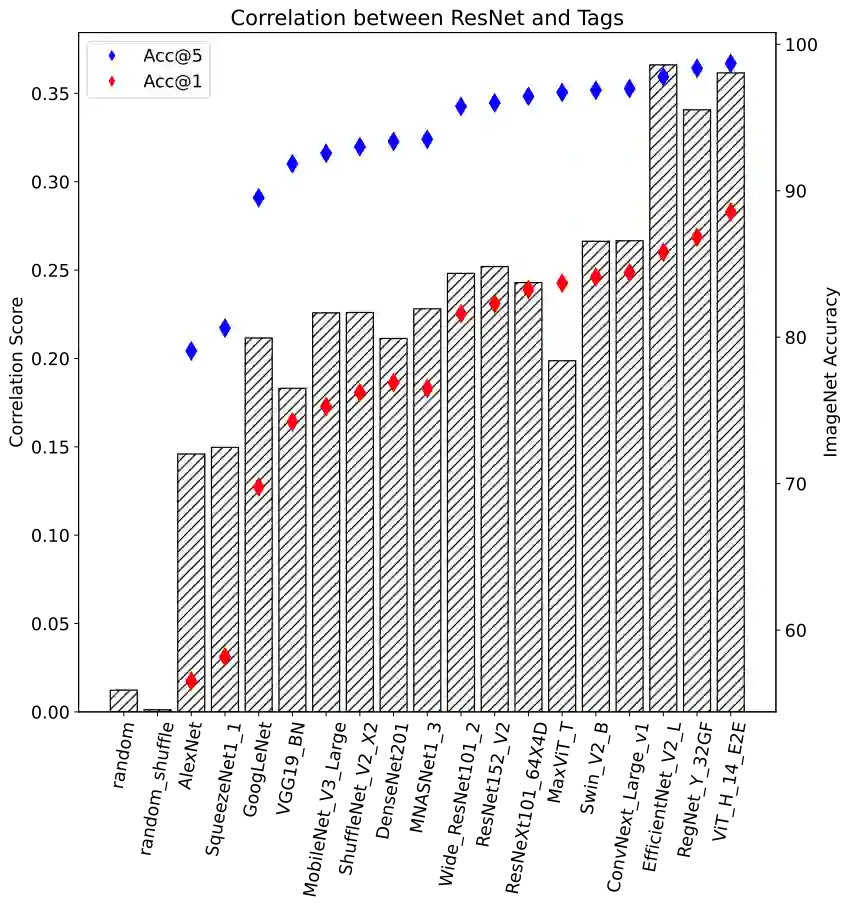
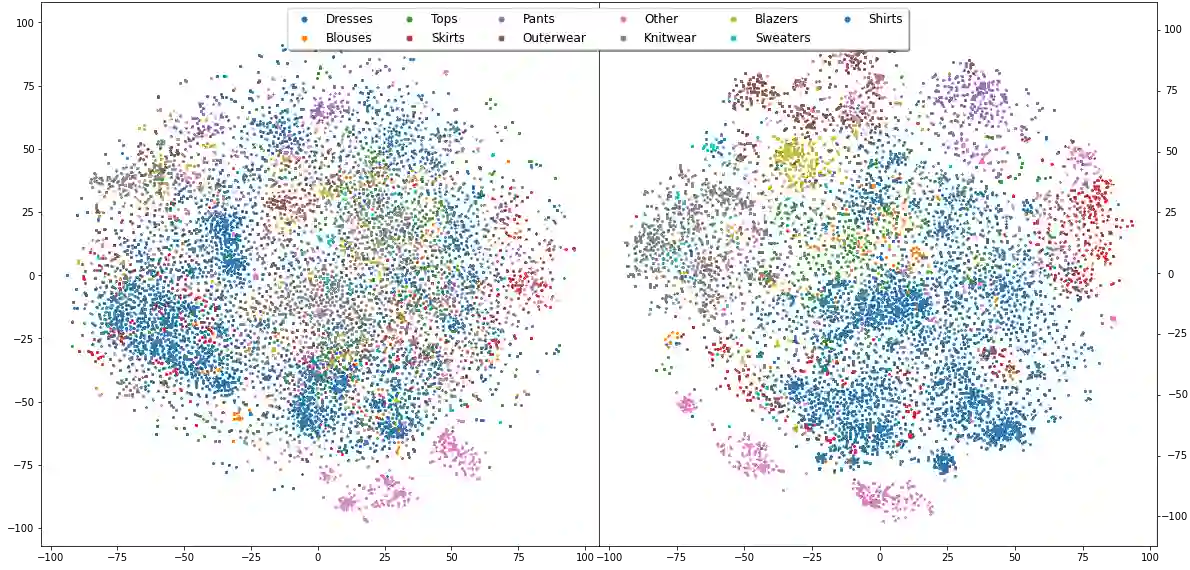
Detecting visually similar images is a particularly useful attribute to look to when calculating product recommendations. Embedding similarity, which utilizes pre-trained computer vision models to extract high-level image features, has demonstrated remarkable efficacy in identifying images with similar compositions. However, there is a lack of methods for evaluating the embeddings generated by these models, as conventional loss and performance metrics do not adequately capture their performance in image similarity search tasks. In this paper, we evaluate the viability of the image embeddings from numerous pre-trained computer vision models using a novel approach named CorrEmbed. Our approach computes the correlation between distances in image embeddings and distances in human-generated tag vectors. We extensively evaluate numerous pre-trained Torchvision models using this metric, revealing an intuitive relationship of linear scaling between ImageNet1k accuracy scores and tag-correlation scores. Importantly, our method also identifies deviations from this pattern, providing insights into how different models capture high-level image features. By offering a robust performance evaluation of these pre-trained models, CorrEmbed serves as a valuable tool for researchers and practitioners seeking to develop effective, data-driven approaches to similar item recommendations in fashion retail.
翻译:检测视觉相似的图像是计算产品推荐时特别有用的属性。嵌入相似性利用预训练的计算机视觉模型提取高级图像特征,已在识别构图相似的图像方面展现出显著效能。然而,目前缺乏评估这些模型生成的嵌入的方法,因为传统的损失和性能指标无法充分捕捉它们在图像相似性搜索任务中的表现。本文提出一种名为CorrEmbed的新颖方法,用于评估多个预训练计算机视觉模型生成的图像嵌入的可行性。我们的方法计算图像嵌入距离与人工生成标签向量距离之间的相关性。我们使用该指标广泛评估了众多预训练的Torchvision模型,揭示了ImageNet1k准确率分数与标签相关性分数之间直观的线性缩放关系。重要的是,我们的方法还识别了偏离此模式的情况,从而揭示了不同模型如何捕捉高级图像特征。通过为这些预训练模型提供稳健的性能评估,CorrEmbed成为研究人员和实践者开发有效、数据驱动的时尚零售中相似商品推荐方法的宝贵工具。