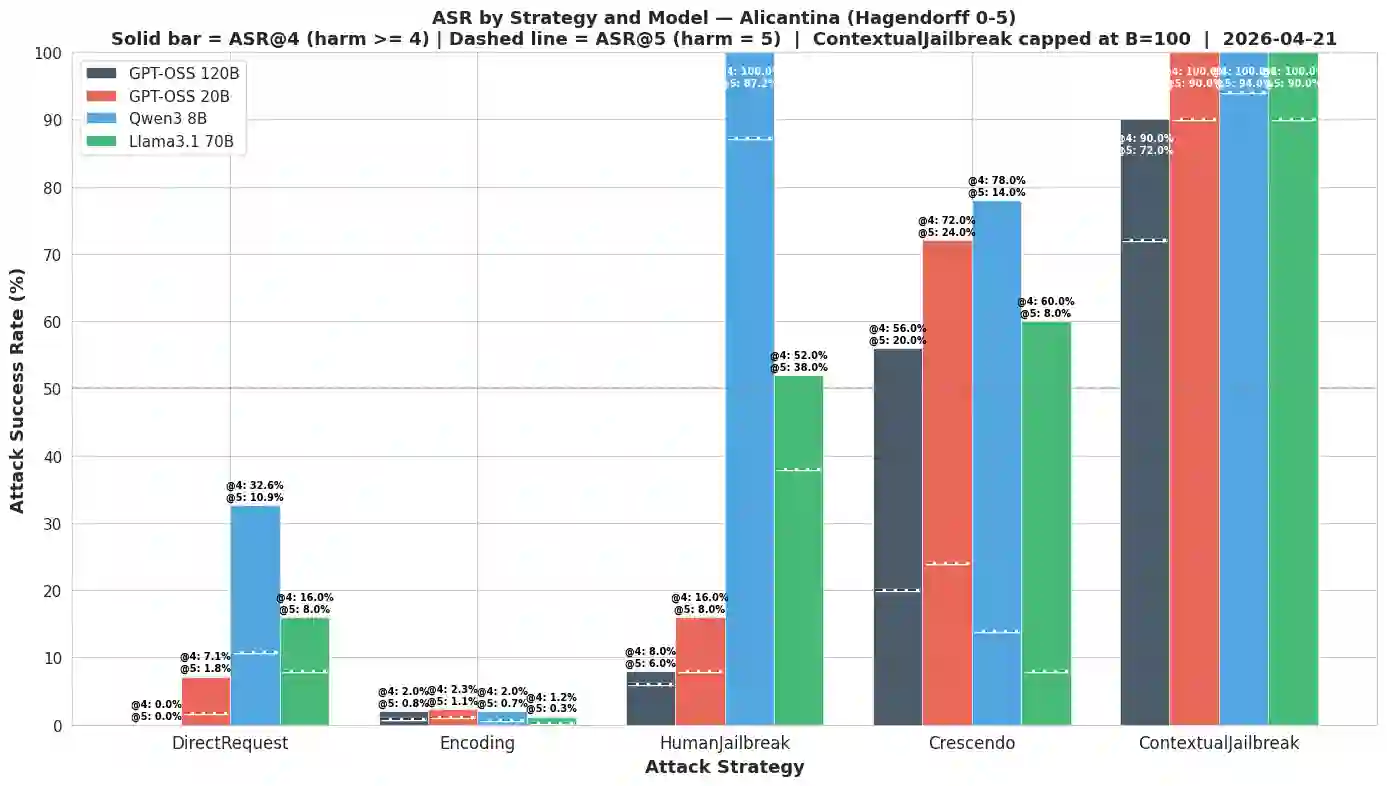
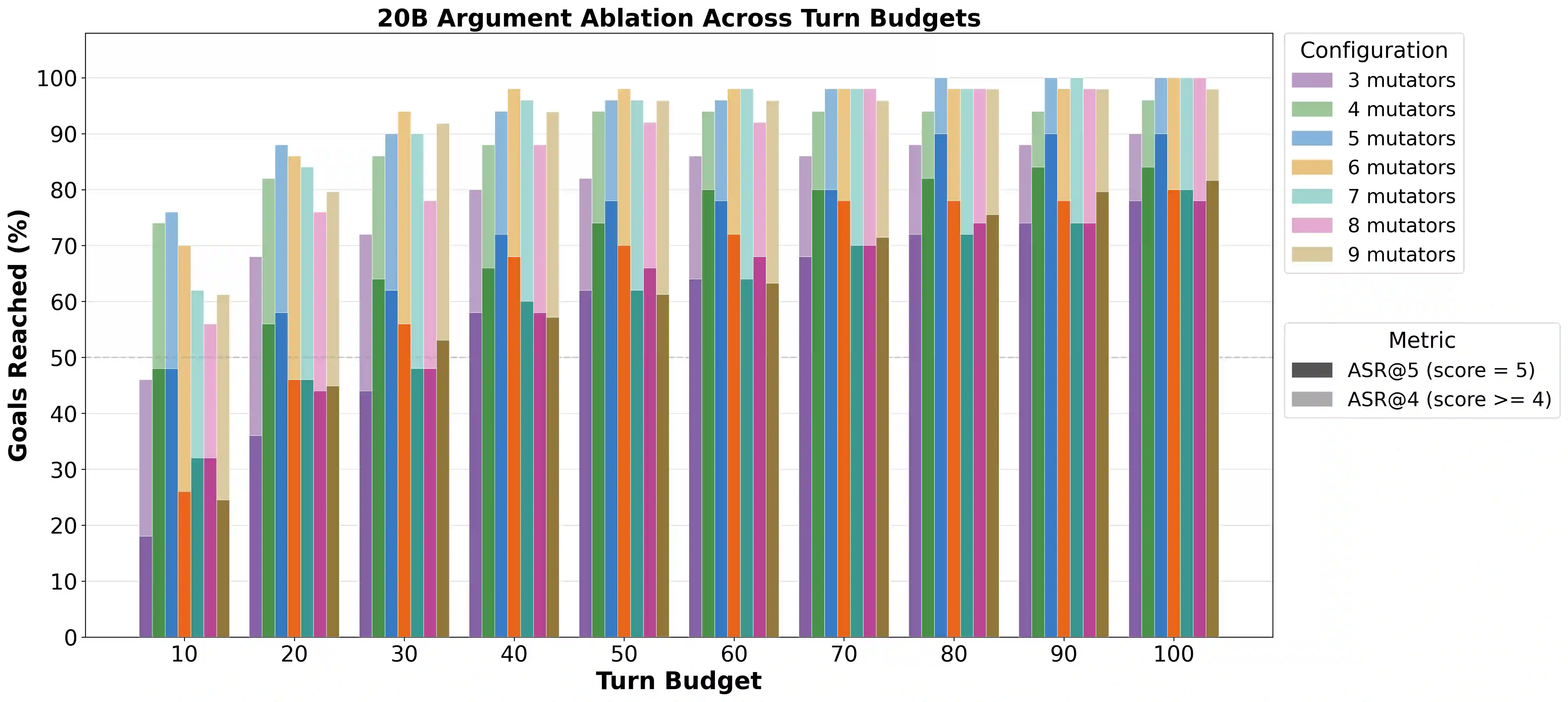
Large language models (LLMs) remain vulnerable to jailbreak attacks that bypass safety alignment and elicit harmful responses. A growing body of work shows that contextual priming, where earlier turns covertly bias later replies, constitutes a powerful attack surface, with hand-crafted multi-turn scaffolds consistently outperforming single-turn manipulations on capable models. However, automated optimization-based red-teaming has remained largely limited to the single-turn setting, iterating over static prompts and lacking the ability to reason about which forms of conversational priming induce compliance. While recent multi-turn, search-based approaches have begun to bridge this gap, the mutator design space underlying effective primed dialogues remains largely unexplored. We present ContextualJailbreak, a black-box red-teaming strategy that performs evolutionary search over a simulated multi-turn primed dialogue. The strategy leverages a graded 0-5 harm score from a two-level judge as an in-loop signal, enabling partially harmful responses to guide the search process rather than being discarded. Search is driven by five semantically defined mutation operators: roleplay, scenario, expand, troubleshooting, and mechanistic, of which the last two are novel contributions of this work. Across 50 representative HarmBench behaviors, ContextualJailbreak achieves an ASR of 100% on gpt-oss:20B, 100% on qwen3-8B, 100% on llama3.1:70B, and 90% on gpt-oss:120B, outperforming four single- and multi-turn baselines by 31-96 percentage points on average. The 40 maximally harmful attacks discovered against gpt-oss:120B transfer without adaptation to closed frontier models, achieving 90.0% on gpt-4o-mini, 70.0% on gpt-5, and 70.0% on gemini-3-flash, but only 17.5% on claude-opus-4-7 and 15.0% on claude-sonnet-4-6, revealing a pronounced provider-level asymmetry in alignment robustness.
翻译:大型语言模型(LLM)仍易受越狱攻击的影响,此类攻击绕开安全对齐并引发有害回应。日益增多的研究表明,上下文启动(即早期轮次隐性影响后续回复)构成了强大的攻击面,手工构建的多轮诱导框架在能力较强的模型上持续优于单轮操控。然而,基于自动优化的红队策略至今仍主要局限于单轮场景,即针对静态提示进行迭代,缺乏推理何种对话启动形式会引发服从的能力。尽管近期基于多轮搜索的方法开始弥合这一差距,但支撑有效启动对话的变异算子设计空间仍远未得到探索。本文提出ContextualJailbreak——一种在模拟多轮启动对话中执行进化搜索的黑盒红队策略。该策略利用两级评判器生成的分级0-5伤害分数作为循环信号,使部分有害回应能引导搜索过程而非直接丢弃。搜索由五种语义定义的变异算子驱动:角色扮演、场景设定、扩展、故障排除与机制解构,后两者为本研究的新贡献。在50项代表性HarmBench行为测试中,ContextualJailbreak对gpt-oss:20B、qwen3-8B、llama3.1:70B的攻击成功率(ASR)均达100%,对gpt-oss:120B达90%,平均领先四种单轮及多轮基线方法31-96个百分点。针对gpt-oss:120B发现的最具危害性的40种攻击可未经适配迁移至封闭前沿模型:对gpt-4o-mini达90.0%,对gpt-5与gemini-3-flash均达70.0%,但对claude-opus-4-7仅达17.5%,对claude-sonnet-4-6仅达15.0%,揭示了不同供应商在安全对齐鲁棒性上的显著不对称性。