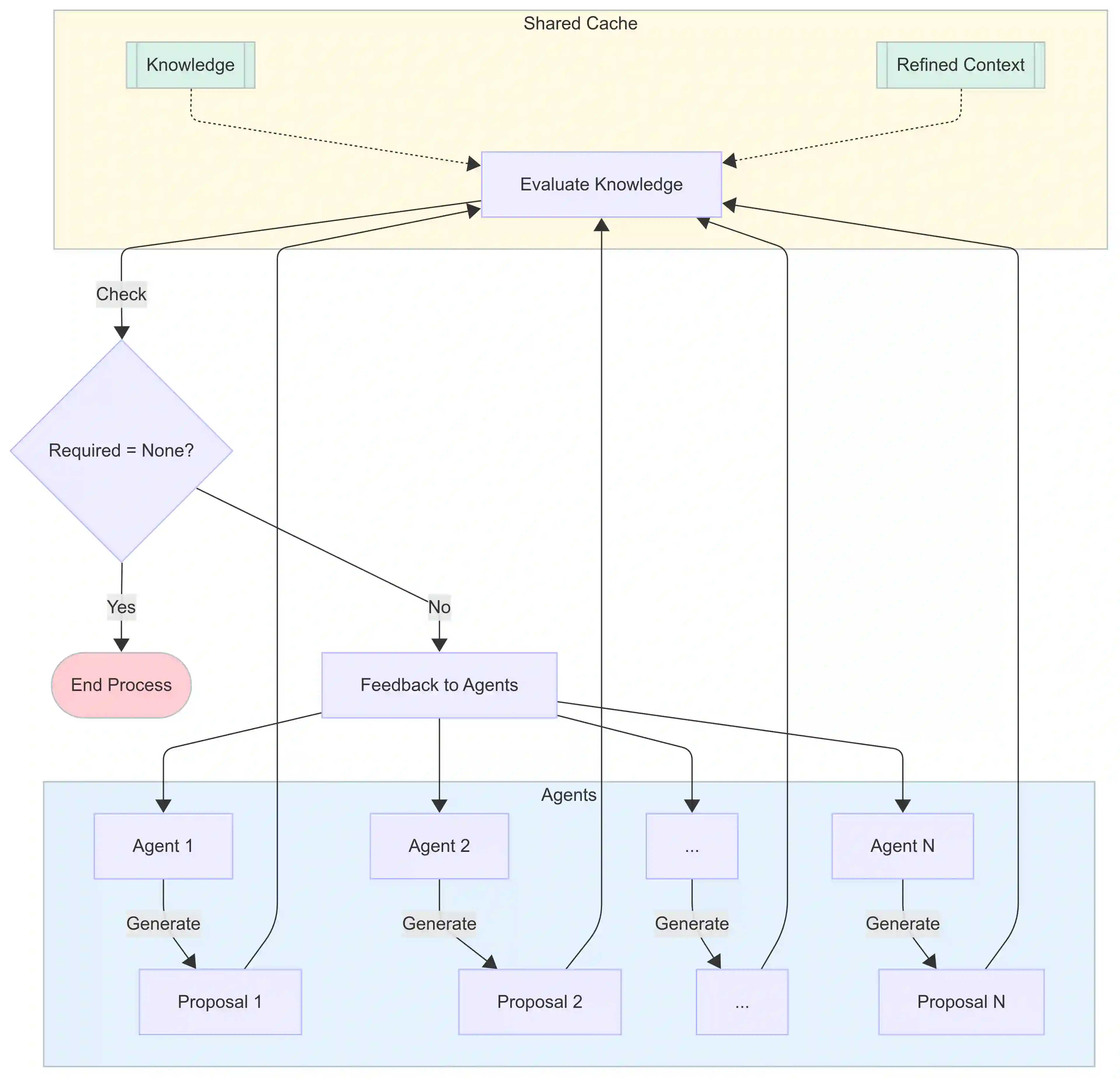
We introduce a novel large language model (LLM)-driven agent framework, which iteratively refines queries and filters contextual evidence by leveraging dynamically evolving knowledge. A defining feature of the system is its decoupling of external sources from an internal knowledge cache that is progressively updated to guide both query generation and evidence selection. This design mitigates bias-reinforcement loops and enables dynamic, trackable search exploration paths, thereby optimizing the trade-off between exploring diverse information and maintaining accuracy through autonomous agent decision-making. Our approach is evaluated on a broad range of open-domain question answering benchmarks, including multi-step tasks that mirror real-world scenarios where integrating information from multiple sources is critical, especially given the vulnerabilities of LLMs that lack explicit reasoning or planning capabilities. The results show that the proposed system not only outperforms single-step baselines regardless of task difficulty but also, compared to conventional iterative retrieval methods, demonstrates pronounced advantages in complex tasks through precise evidence-based reasoning and enhanced efficiency. The proposed system supports both competitive and collaborative sharing of updated context, enabling multi-agent extension. The benefits of multi-agent configurations become especially prominent as task difficulty increases. The number of convergence steps scales with task difficulty, suggesting cost-effective scalability.
翻译:我们提出了一种新型的大语言模型驱动的智能体框架,该框架通过利用动态演化的知识,迭代地优化查询并筛选上下文证据。该系统的核心特征在于将外部来源与内部知识缓存解耦,后者通过渐进式更新来指导查询生成与证据选择。这一设计缓解了偏见强化循环,实现了动态、可追踪的搜索探索路径,从而通过自主智能体决策优化了探索多样化信息与保持准确性之间的权衡。我们在广泛的开放域问答基准上评估了该方法,包括模拟现实场景的多步骤任务——此类场景中整合多源信息至关重要,尤其考虑到大语言模型缺乏显式推理或规划能力的固有缺陷。结果表明,无论任务难度如何,所提出的系统均优于单步基线方法;相较于传统迭代检索方法,其在复杂任务中通过基于证据的精确推理与提升的效率展现出显著优势。该系统支持更新后上下文的竞争性与协作性共享,实现了多智能体扩展。随着任务难度增加,多智能体配置的优势尤为突出。收敛步数随任务难度呈比例增长,表明其具备成本效益的可扩展性。