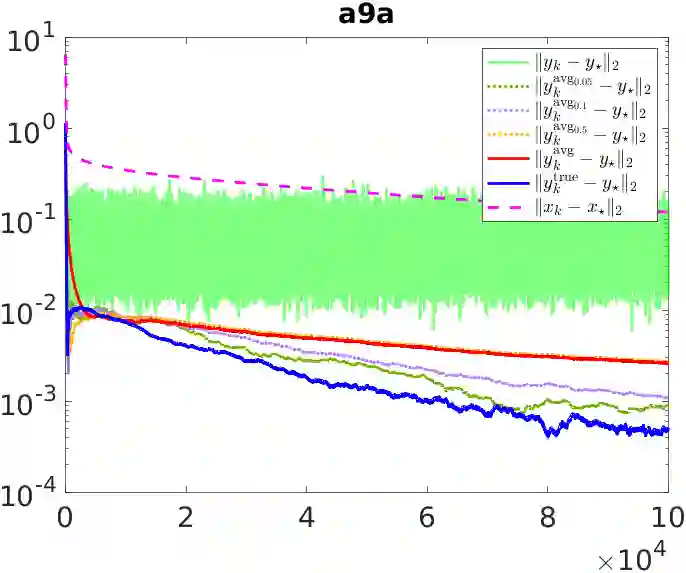
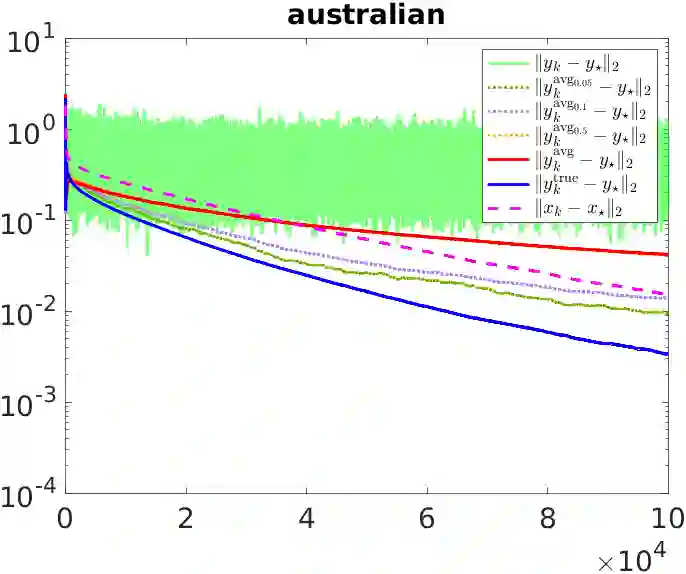
Stochastic sequential quadratic optimization (SQP) methods for solving continuous optimization problems with nonlinear equality constraints have attracted attention recently, such as for solving large-scale data-fitting problems subject to nonconvex constraints. However, for a recently proposed subclass of such methods that is built on the popular stochastic-gradient methodology from the unconstrained setting, convergence guarantees have been limited to the asymptotic convergence of the expected value of a stationarity measure to zero. This is in contrast to the unconstrained setting in which almost-sure convergence guarantees (of the gradient of the objective to zero) can be proved for stochastic-gradient-based methods. In this paper, new almost-sure convergence guarantees for the primal iterates, Lagrange multipliers, and stationarity measures generated by a stochastic SQP algorithm in this subclass of methods are proved. It is shown that the error in the Lagrange multipliers can be bounded by the distance of the primal iterate to a primal stationary point plus the error in the latest stochastic gradient estimate. It is further shown that, subject to certain assumptions, this latter error can be made to vanish by employing a running average of the Lagrange multipliers that are computed during the run of the algorithm. The results of numerical experiments are provided to demonstrate the proved theoretical guarantees.
翻译:随机逐次二次优化(SQP)方法用于求解带非线性等式约束的连续优化问题,近年来受到广泛关注,例如应用于求解受非凸约束的大规模数据拟合问题。然而,对于近期提出的一类基于无约束场景下流行的随机梯度方法构建的SQP子类方法,其收敛保证仅限于平稳性度量期望值的渐近收敛于零。这与无约束场景形成对比,在无约束场景中,基于随机梯度的方法可以证明几乎必然收敛性(即目标函数梯度趋于零)。本文证明了该子类中随机SQP算法生成的原始迭代点、拉格朗日乘子及平稳性度量的新型几乎必然收敛保证。研究表明,拉格朗日乘子的误差可由原始迭代点到原始平稳点的距离加上最新随机梯度估计的误差来界定。进一步证明,在特定假设下,通过采用算法运行过程中计算的拉格朗日乘子的运行平均值,可使后一误差消失。数值实验的结果验证了所证明的理论保证。