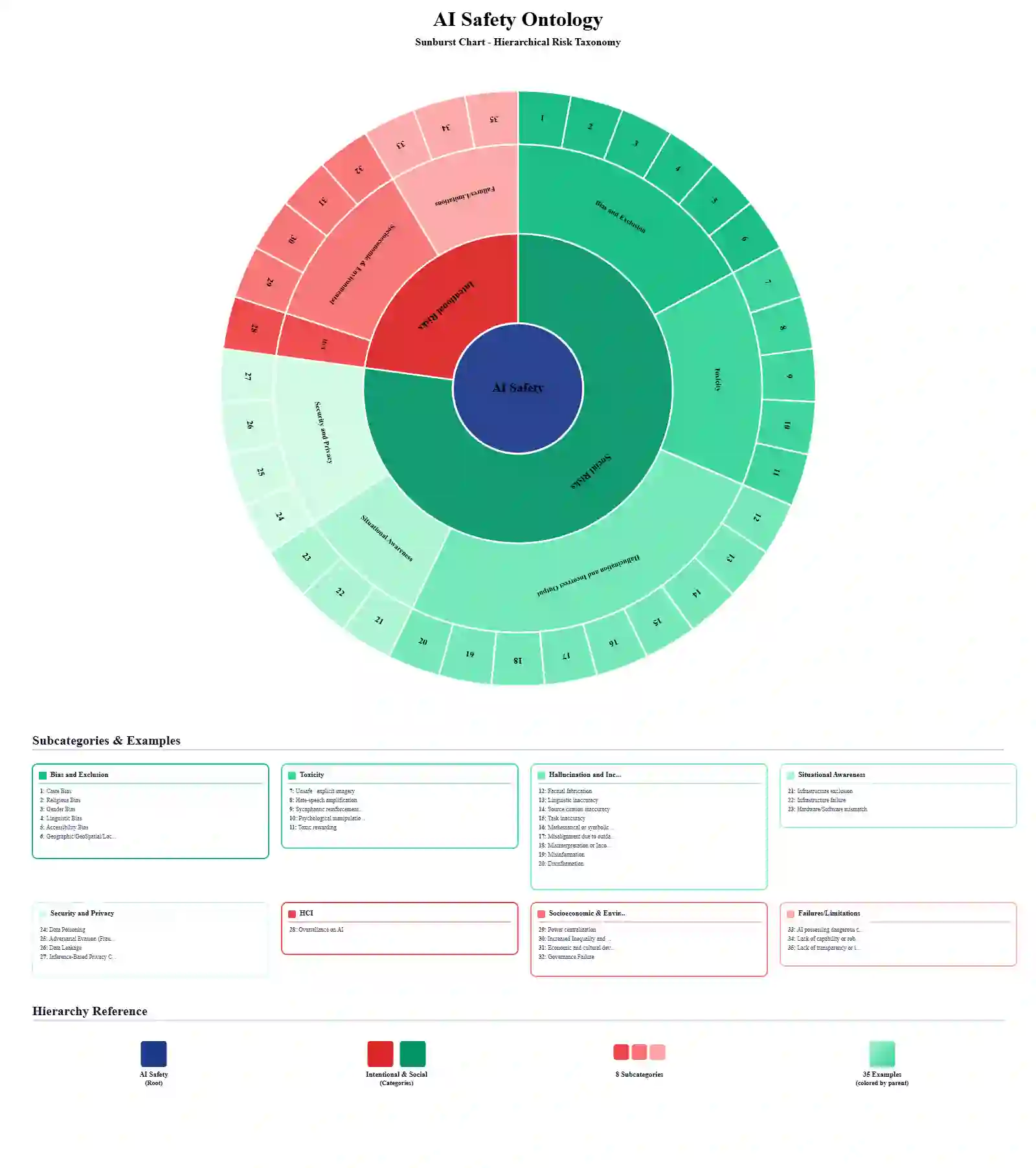
This paper argues that existing global AI safety frameworks exhibit contextual blindness towards India's unique socio-technical landscape. With a population of 1.5 billion and a massive informal economy, India's AI integration faces specific challenges such as caste-based discrimination, linguistic exclusion of vernacular speakers, and infrastructure failures in low-connectivity rural zones, that are frequently overlooked by Western, market-centric narratives. We introduce ASTRA, an empirically grounded AI Safety Risk Database designed to categorize risks through a bottom-up, inductive process. Unlike general taxonomies, ASTRA defines AI Safety Risks specifically as hazards stemming from design flaws such as skewed training sets or lack of guardrails that can be mitigated through technical iteration or architectural changes. This framework employs a tripartite causal taxonomy to evaluate risks based on their implementation timing (development, deployment, or usage), the responsible entity (the system or the user), and the nature of the intent (unintentional vs. intentional). Central to the research is a domain-agnostic ontology that organizes 37 leaf-level risk classes into two primary meta-categories: Social Risks and Frontier/Socio-Structural Risks. By focusing initial efforts on the Education and Financial Lending sectors, the paper establishes a scalable foundation for a "living" regulatory utility intended to evolve alongside India's expanding AI ecosystem.
翻译:本文认为,现有全球人工智能安全框架对印度独特的社会技术环境存在情境盲区。印度拥有15亿人口和庞大的非正规经济,其人工智能融合面临种姓歧视、方言使用者语言排斥以及低连接性农村地区基础设施故障等具体挑战,这些常被西方以市场为中心的论述所忽视。我们提出ASTRA——一个基于实证的人工智能安全风险数据库,旨在通过自下而上的归纳过程对风险进行分类。与通用分类法不同,ASTRA将人工智能安全风险明确定义为源于设计缺陷(如训练集偏差或防护机制缺失)的危害,此类风险可通过技术迭代或架构调整予以缓解。该框架采用三重因果分类法,依据风险的实施时机(开发、部署或使用阶段)、责任主体(系统或用户)以及意图性质(无意与有意)进行评估。研究的核心是一个领域无关的本体论,它将37个叶级风险类别组织成两个主要元类别:社会风险与前沿/社会结构风险。通过将初期研究重点集中于教育和金融信贷领域,本文为构建"动态"监管工具奠定了可扩展的基础,该工具旨在伴随印度不断扩展的人工智能生态系统同步演进。