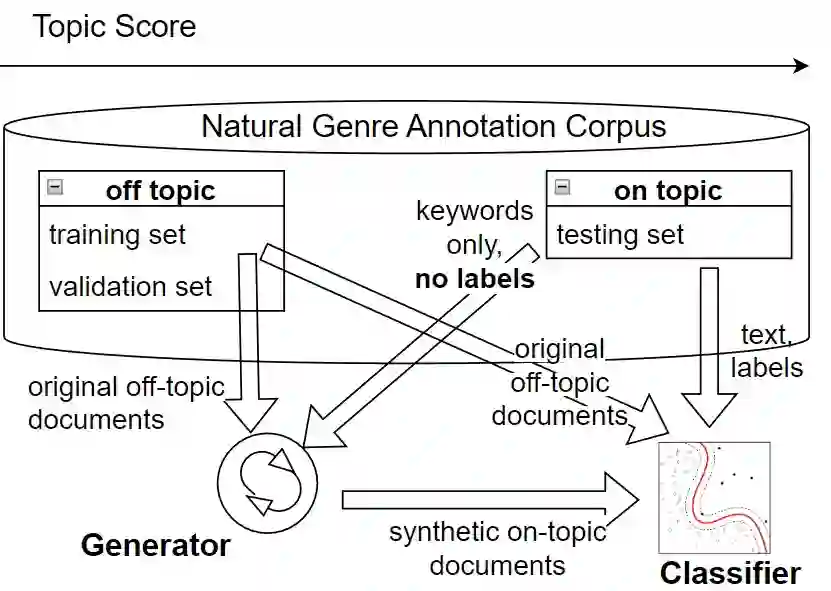
While performance of many text classification tasks has been recently improved due to Pre-trained Language Models (PLMs), in this paper we show that they still suffer from a performance gap when the underlying distribution of topics changes. For example, a genre classifier trained on \textit{political} topics often fails when tested on documents about \textit{sport} or \textit{medicine}. In this work, we quantify this phenomenon empirically with a large corpus and a large set of topics. Consequently, we verify that domain transfer remains challenging both for classic PLMs, such as BERT, and for modern large models, such as GPT-3. We also suggest and successfully test a possible remedy: after augmenting the training dataset with topically-controlled synthetic texts, the F1 score improves by up to 50\% for some topics, nearing on-topic training results, while others show little to no improvement. While our empirical results focus on genre classification, our methodology is applicable to other classification tasks such as gender, authorship, or sentiment classification. The code and data to replicate the experiments are available at https://github.com/dminus1/genre
翻译:尽管预训练语言模型(Pre-trained Language Models, PLMs)近期提升了许多文本分类任务的性能,但本文发现,当主题的潜在分布发生变化时,这些模型仍存在性能差距。例如,基于政治主题训练的体裁分类器在测试体育或医学文档时往往失效。本研究通过大规模语料库和广泛主题集对这一现象进行量化验证,证实领域迁移对经典PLM(如BERT)和现代大型模型(如GPT-3)均构成挑战。我们提出并成功测试了一种可能的解决方案:在训练数据中增强主题可控的合成文本后,部分主题的F1分数提升高达50%,接近同主题训练结果,而其他主题则收效甚微。虽然本实证研究聚焦于体裁分类,但该方法同样适用于性别、作者身份或情感分析等其他分类任务。实验复现的代码与数据可通过https://github.com/dminus1/genre获取。