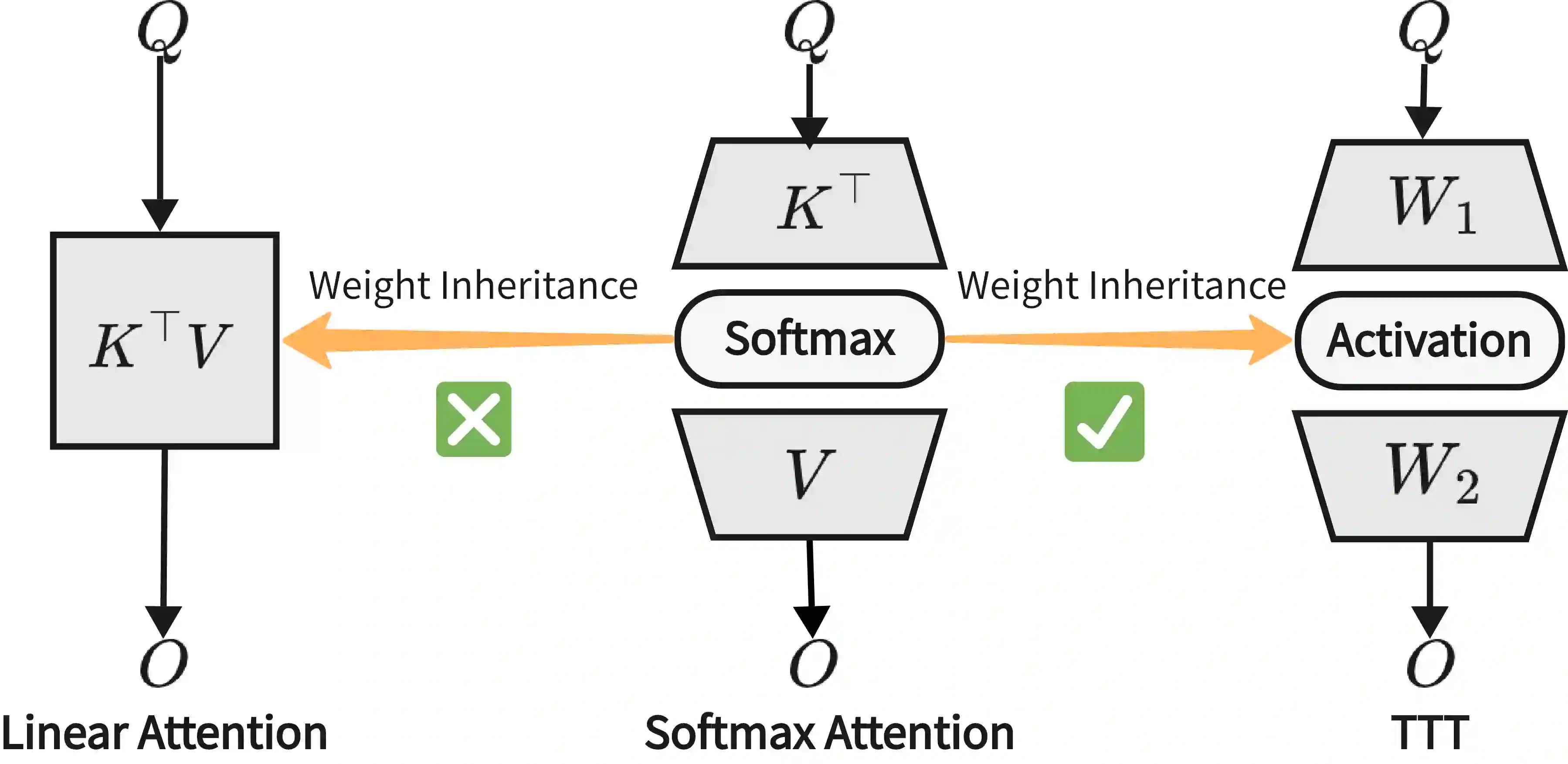
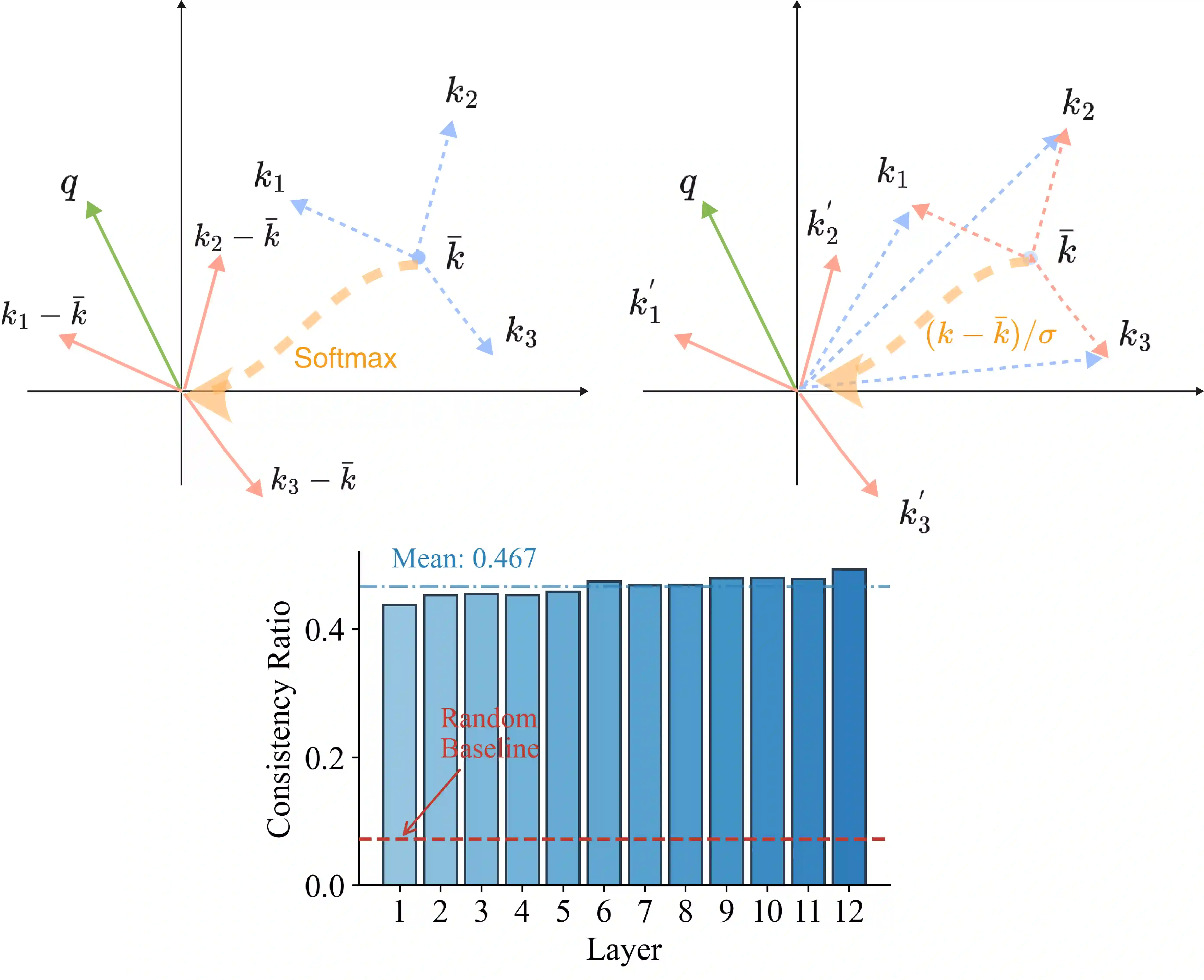
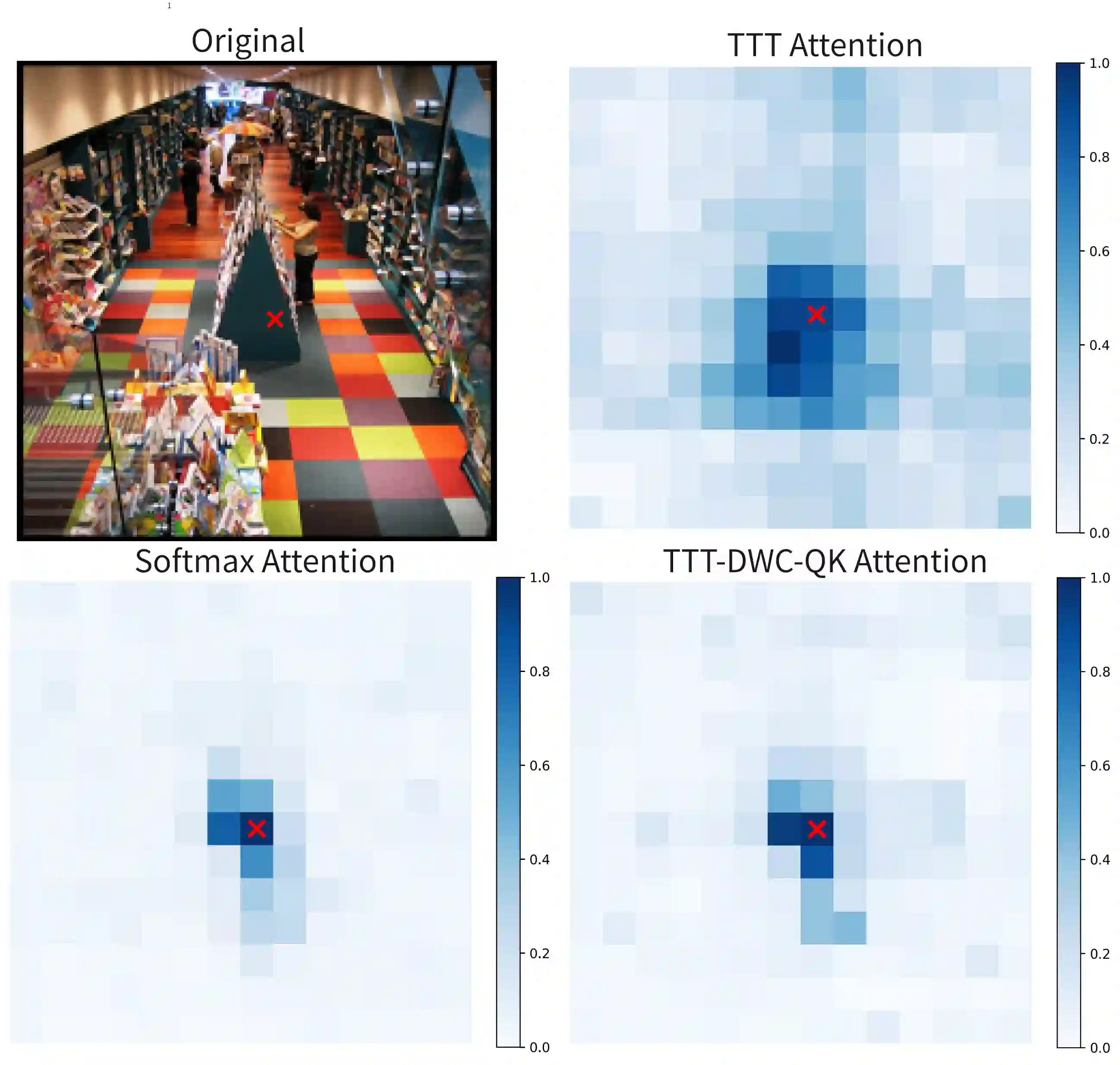
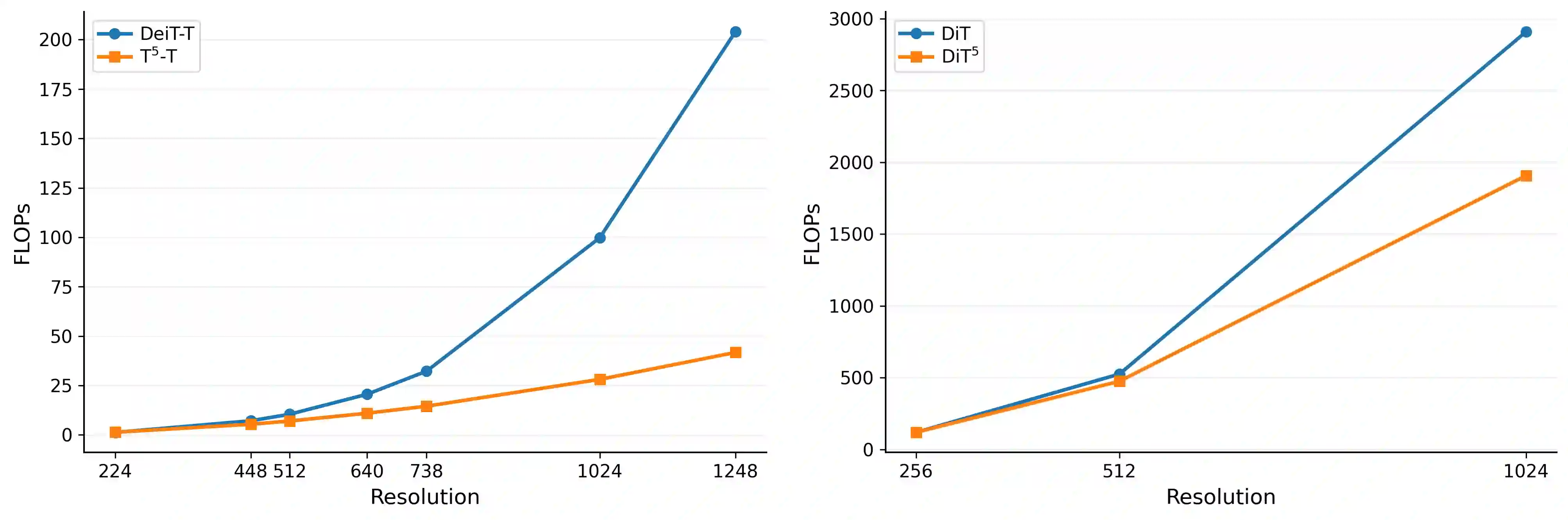
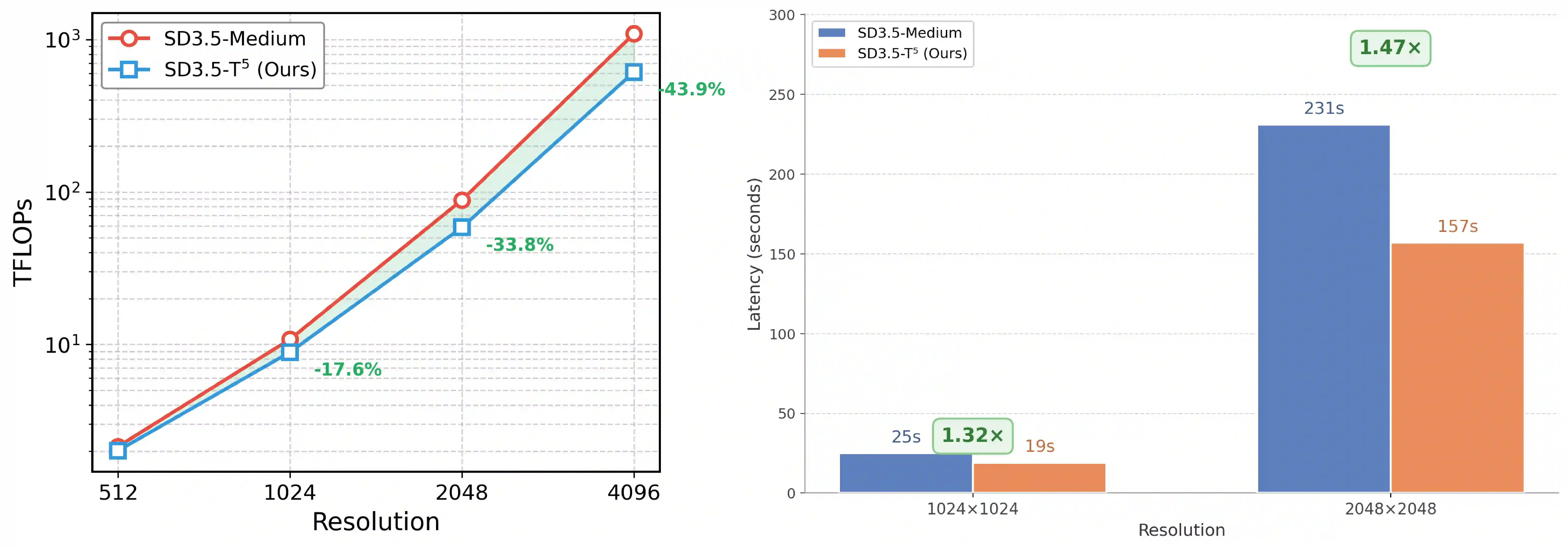
While linear-complexity attention mechanisms offer a promising alternative to Softmax attention for overcoming the quadratic bottleneck, training such models from scratch remains prohibitively expensive. Inheriting weights from pretrained Transformers provides an appealing shortcut, yet the fundamental representational gap between Softmax and linear attention prevents effective weight transfer. In this work, we address this conversion challenge from two perspectives: architectural alignment and representational alignment. We identify Test-Time Training (TTT) as a linear-complexity architecture whose two-layer dynamic formulation is structurally aligned with Softmax attention, enabling direct inheritance of pretrained attention weights. To further align representational properties, including key shift-invariance and locality, we introduce key instance normalization and a lightweight locality enhancement module. We validate our approach by linearizing Stable Diffusion 3.5 and introduce SD3.5-T$^5$ (Transformer To Test Time Training). With only 1 hour of fine-tuning on 4$\times$H20 GPUs, SD3.5-T$^5$ achieves comparable text-to-image quality to the fine-tuned Softmax model, while accelerating inference by 1.32$\times$ and 1.47$\times$ at 1K and 2K resolutions.
翻译:虽然线性复杂度注意力机制为克服Softmax注意力的二次瓶颈提供了有前景的替代方案,但从头训练此类模型仍面临极高的计算成本。利用预训练Transformer的权重继承虽提供了捷径,但Softmax注意力与线性注意力之间存在根本性的表征鸿沟,阻碍了有效的权重迁移。本文从架构对齐与表征对齐两个维度解决了这一转换挑战。我们发现测试时训练(Test-Time Training, TTT)是一种线性复杂度架构,其双层动态结构在结构上与Softmax注意力对齐,从而能够直接继承预训练注意力权重。为进一步对齐表征特性(包括关键平移不变性与局部性),我们引入了关键实例归一化与轻量级局部性增强模块。通过线性化Stable Diffusion 3.5验证了方法的有效性,并提出了SD3.5-T$^5$ (Transformer To Test Time Training)。仅需在4$\times$H20 GPU上微调1小时,SD3.5-T$^5$即可达到与微调Softmax模型相当的文生图质量,同时在1K与2K分辨率下分别实现1.32倍与1.47倍的推理加速。