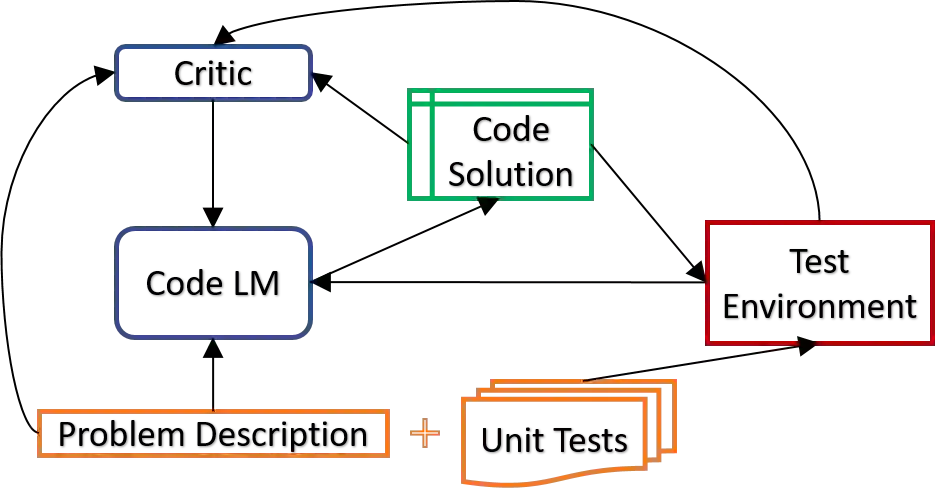
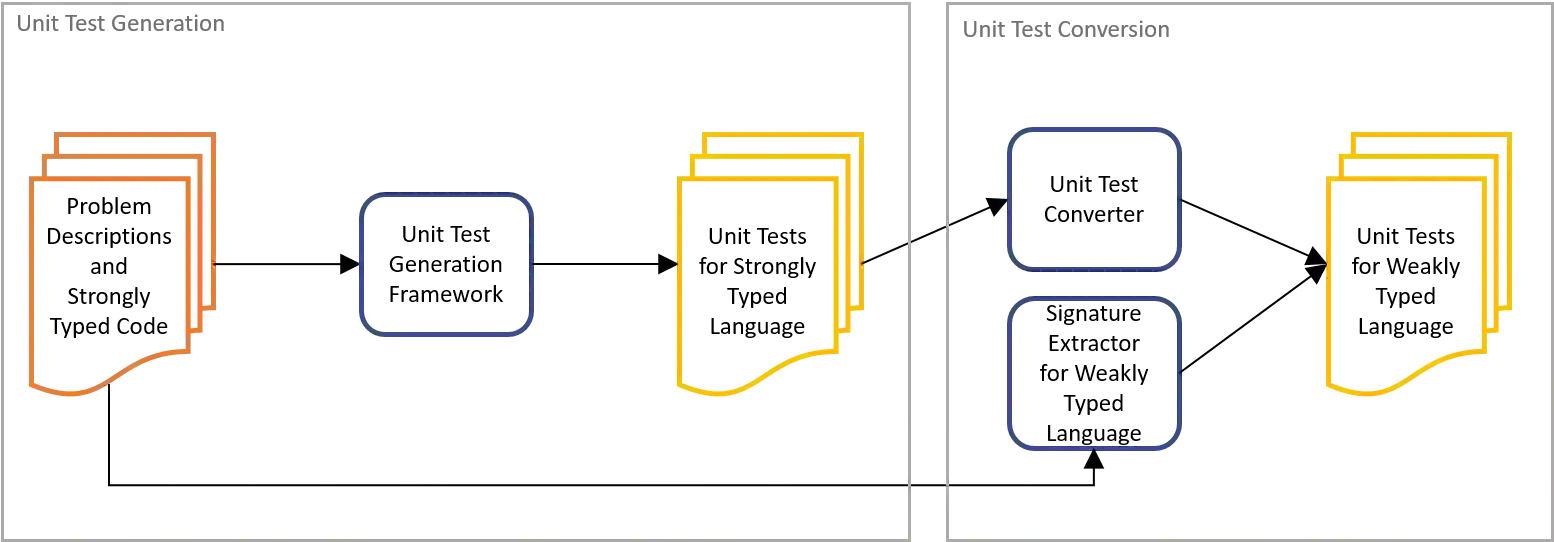
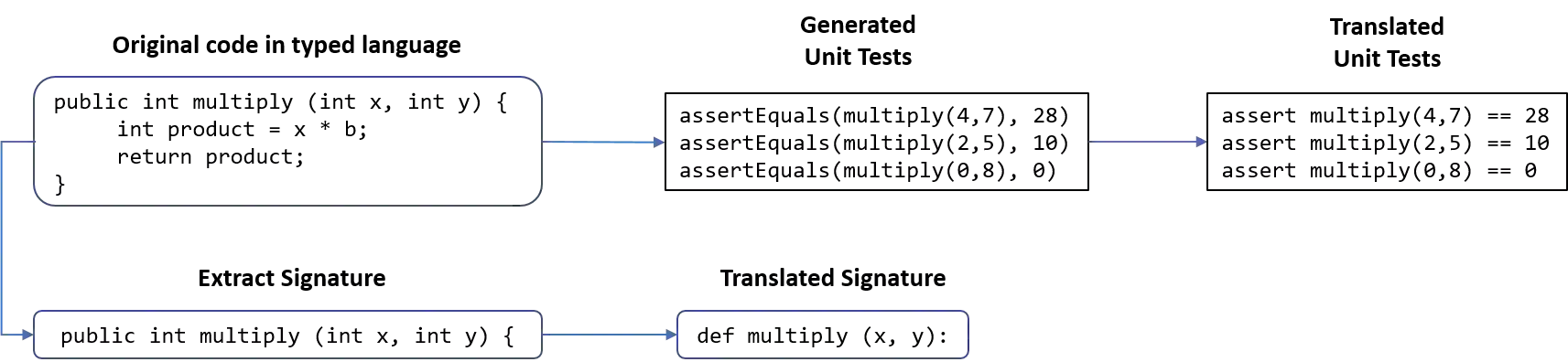
The advent of large pre-trained language models in the domain of Code Synthesis has shown remarkable performance on various benchmarks, treating the problem of Code Generation in a fashion similar to Natural Language Generation, trained with a Language Modelling (LM) objective. In addition, the property of programming language code being precisely evaluable with respect to its semantics -- through the use of Unit Tests to check its functional correctness -- lends itself to using Reinforcement Learning (RL) as a further training paradigm. Previous work has shown that RL can be applied as such to improve models' coding capabilities; however, such RL-based methods rely on a reward signal based on defined Unit Tests, which are much harder to obtain compared to the huge crawled code datasets used in LM objectives. In this work, we present a novel approach to automatically obtain data consisting of function signatures and associated Unit Tests, suitable for RL training of Code Synthesis models. We also introduce a straightforward, simple yet effective Actor-Critic RL training scheme and show that it, in conjunction with automatically generated training data, leads to improvement of a pre-trained code language model's performance by up to 9.9% improvement over the original underlying code synthesis LM, and up to 4.3% over RL-based models trained with standard PPO or CodeRL.
翻译:大型预训练语言模型在代码合成领域的发展已在多个基准测试中展现出卓越性能,其将代码生成问题以类似自然语言生成的方式进行处理,并采用语言建模目标进行训练。此外,编程语言代码可通过单元测试对其功能正确性进行精确语义评估的特性,使得强化学习能够作为进一步的训练范式加以应用。先前研究表明,强化学习可直接用于提升模型的编码能力,然而这类基于强化学习的方法依赖已定义单元测试提供的奖励信号,相较于语言建模目标中使用的大规模网络爬取代码数据集,单元测试数据的获取难度显著更高。本文提出一种新颖方法,可自动获取包含函数签名及对应单元测试的数据集,适用于代码合成模型的强化学习训练。同时,我们引入一个简洁有效的演员-评论家强化学习训练方案,实验表明该方法与自动生成的训练数据相结合,可使预训练代码语言模型的性能较原始代码合成语言模型最高提升9.9%,较采用标准PPO或CodeRL训练的强化学习模型最高提升4.3%。