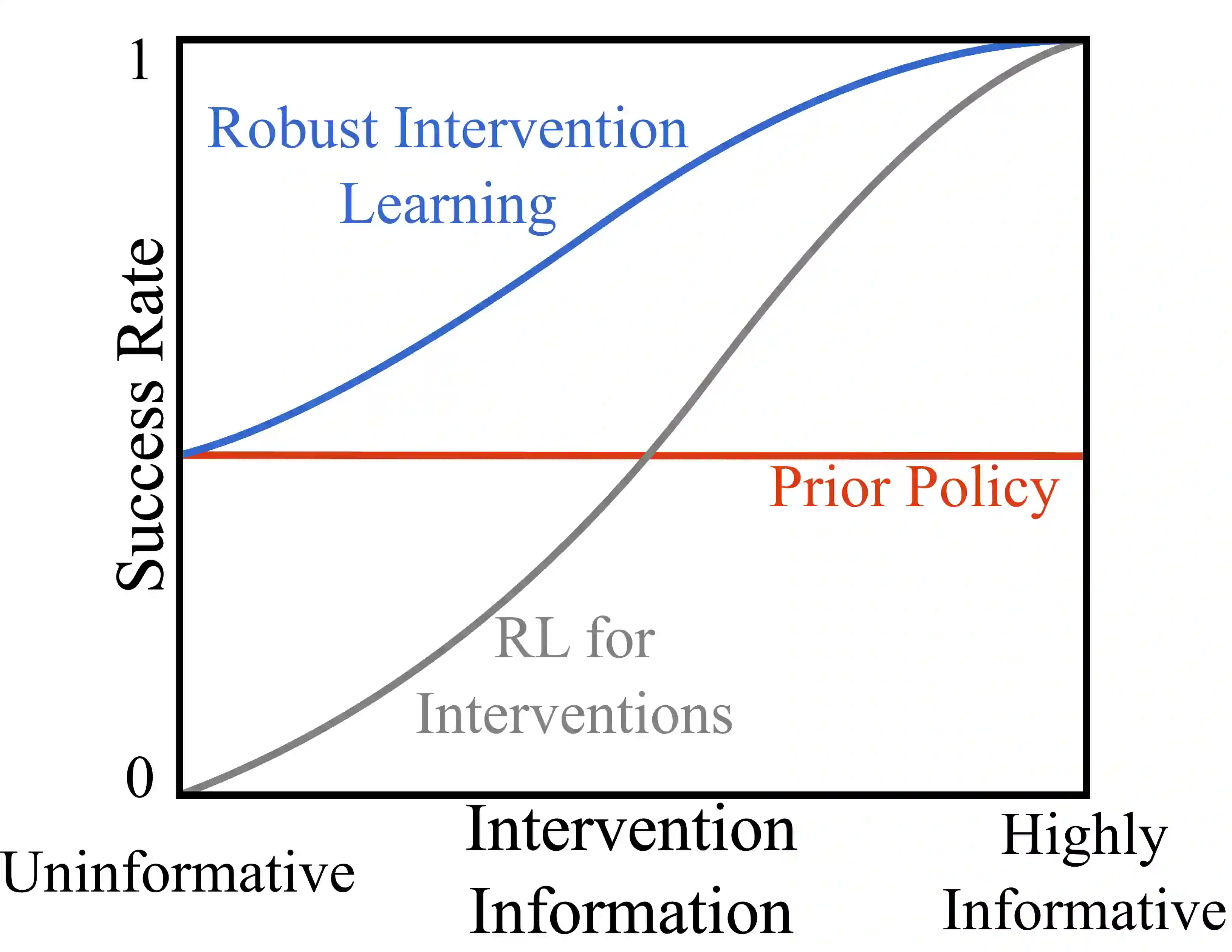
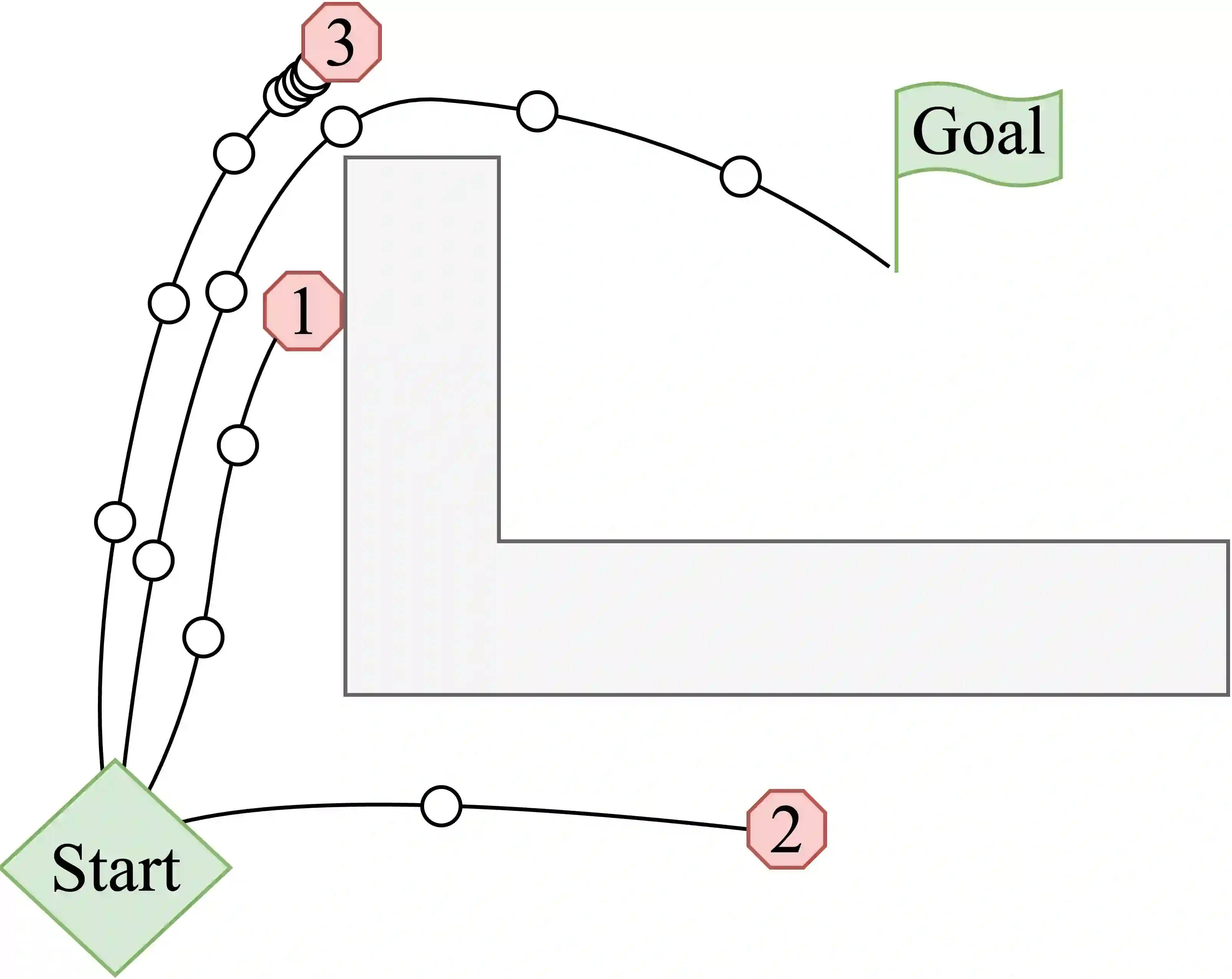
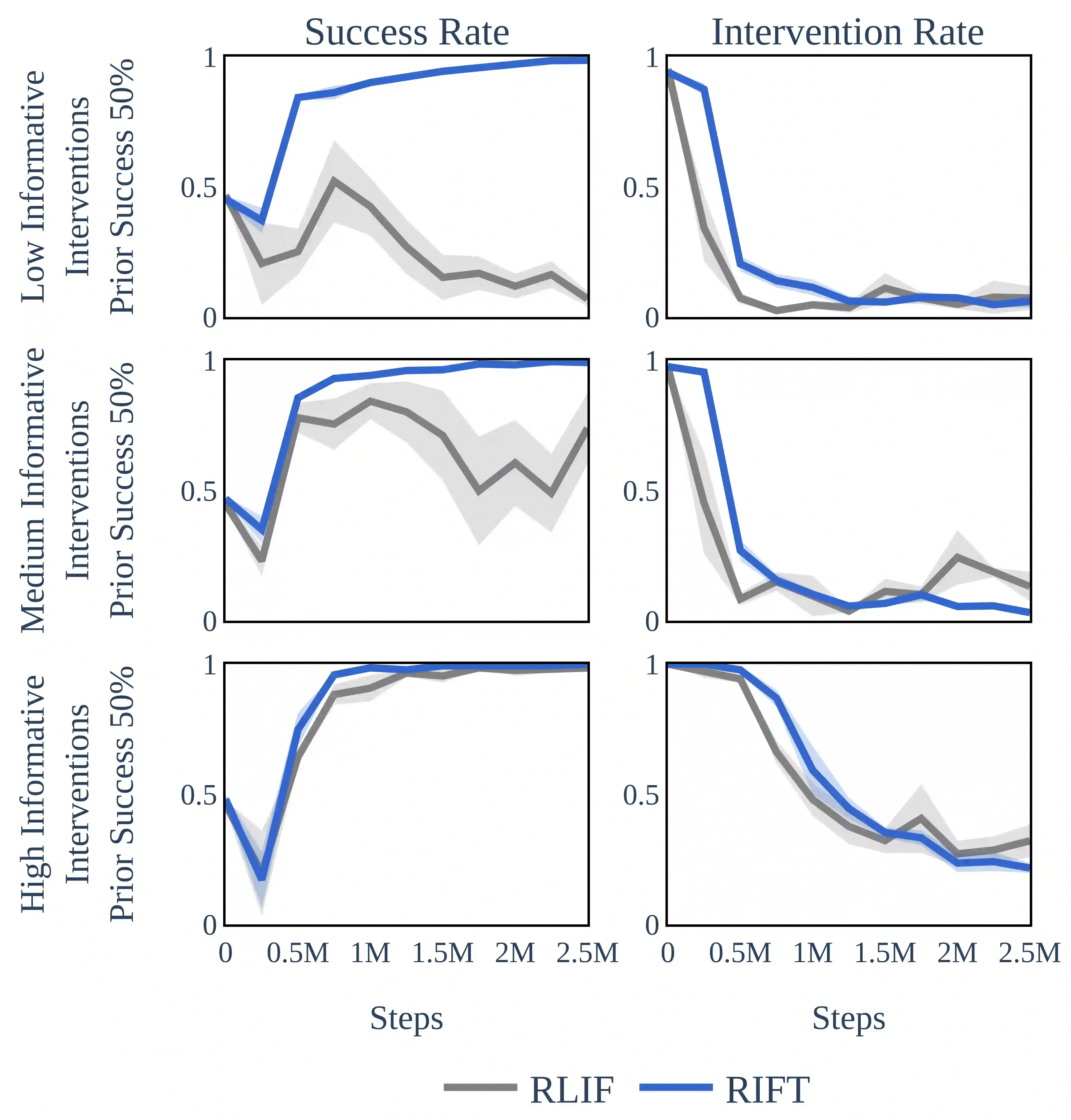
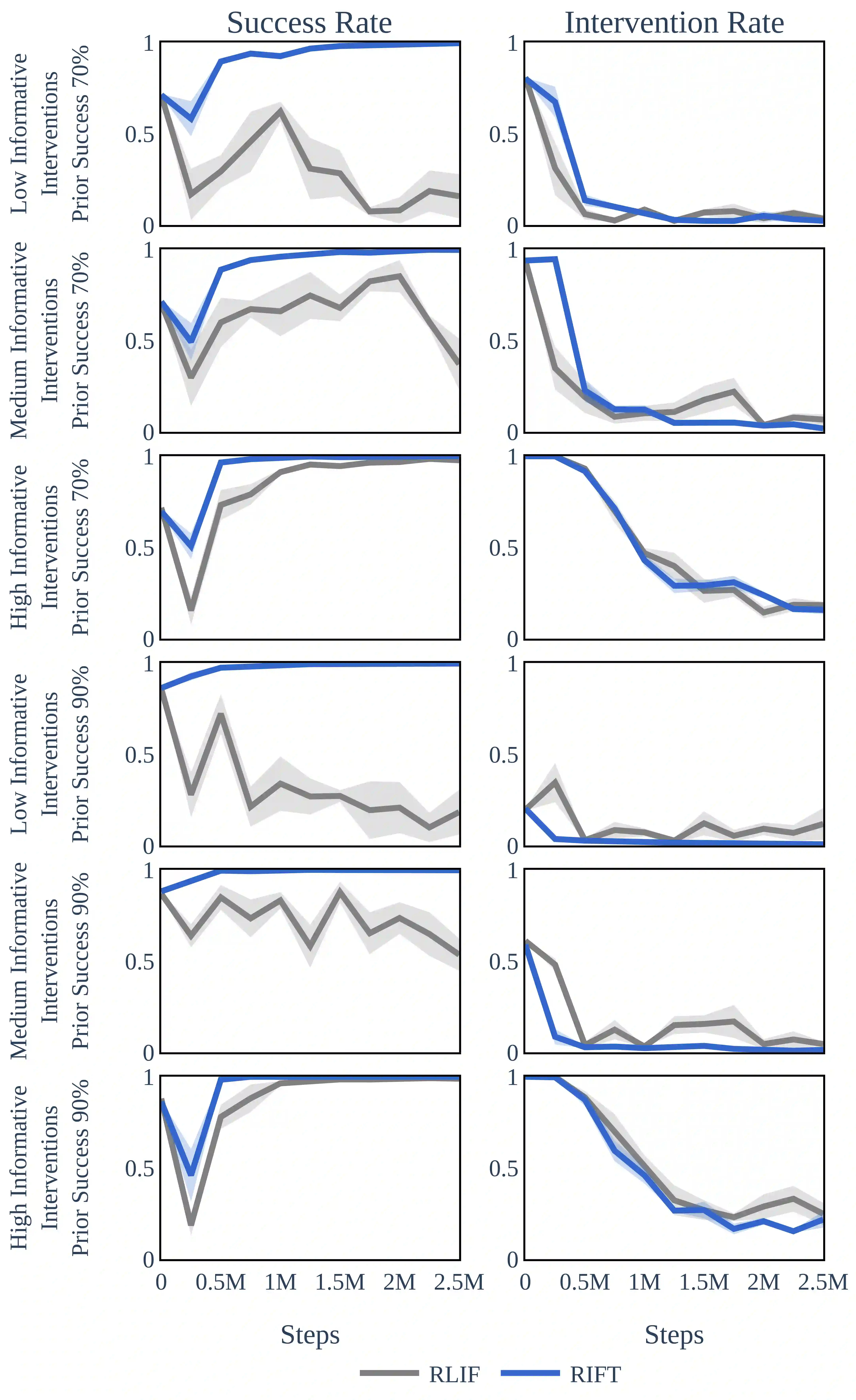
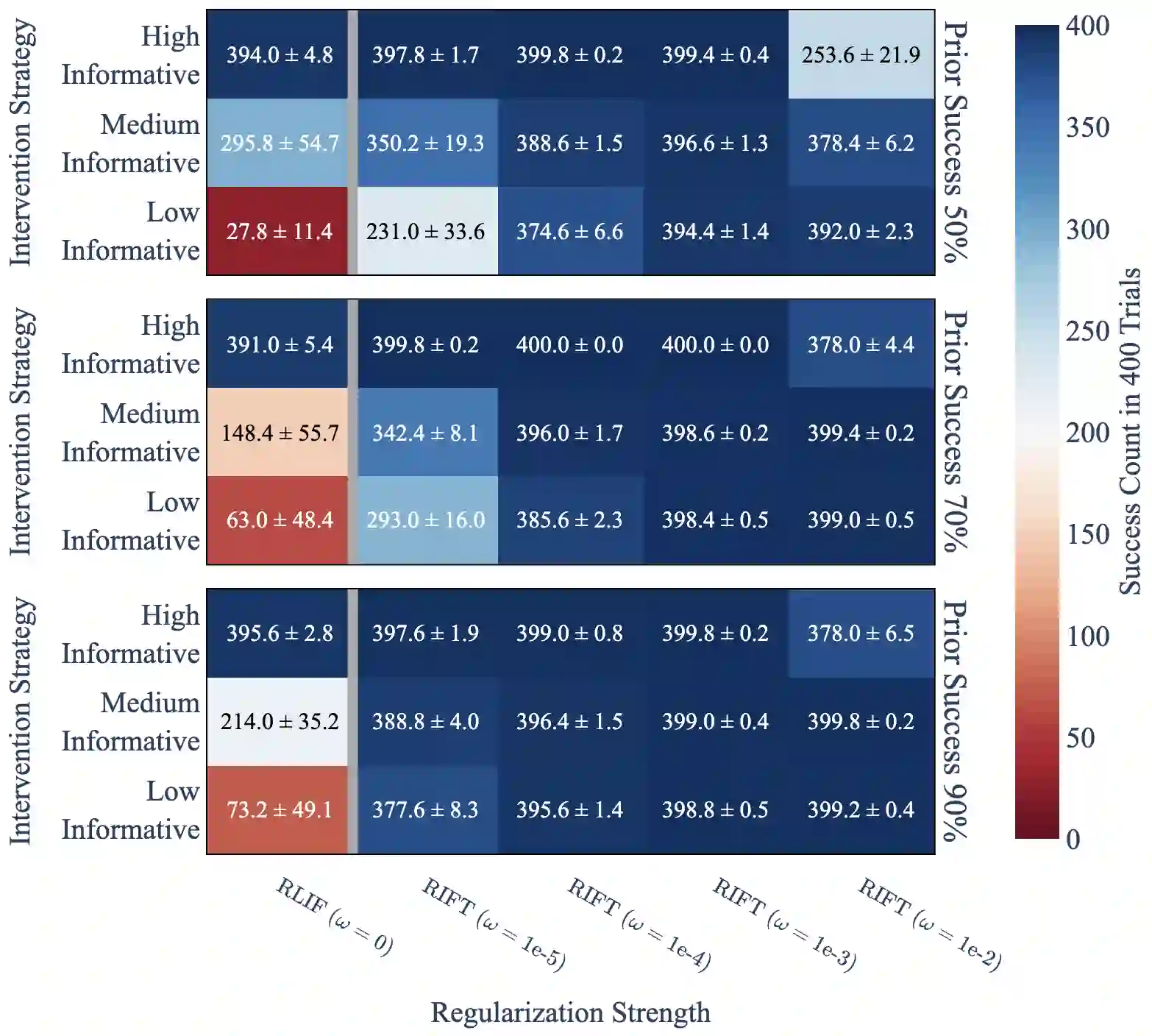
Human interventions are a common source of data in autonomous systems during testing. These interventions provide an important signal about where the current policy needs improvement, but are often noisy and incomplete. We define Robust Intervention Learning (RIL) as the problem of learning from intervention data while remaining robust to the quality and informativeness of the intervention signal. In the best case, interventions are precise and avoiding them is sufficient to solve the task, but in many realistic settings avoiding interventions is necessary but not sufficient for achieving good performance. We study robust intervention learning in the context of emergency stop interventions and propose Residual Intervention Fine-Tuning (RIFT), a residual fine-tuning algorithm that treats intervention feedback as an incomplete learning signal and explicitly combines it with a prior policy. By framing intervention learning as a fine-tuning problem, our approach leverages structure encoded in the prior policy to resolve ambiguity when intervention signals under-specify the task. We provide theoretical analysis characterizing conditions under which this formulation yields principled policy improvement, and identify regimes where intervention learning is expected to fail. Our experiments reveal that residual fine-tuning enables robust and consistent policy improvement across a range of intervention strategies and prior policy qualities, and highlight robust intervention learning as a promising direction for future work.
翻译:在自主系统的测试过程中,人工干预是常见的数据来源。这些干预为当前策略需要改进之处提供了重要信号,但通常具有噪声且不完整。我们将鲁棒干预学习(RIL)定义为从干预数据中学习、同时对干预信号的质量和信息量保持鲁棒性的问题。在理想情况下,干预是精确的,避免干预即足以完成任务;但在许多实际场景中,避免干预是必要条件,却不足以实现良好性能。本研究以紧急停止干预为背景探讨鲁棒干预学习,并提出残差干预微调(RIFT)算法——一种将干预反馈视为不完整学习信号,并显式地将其与先验策略相结合的残差微调算法。通过将干预学习构建为微调问题,我们的方法利用先验策略中编码的结构来化解干预信号未能充分定义任务时的歧义。我们提供了理论分析,刻画了该框架能够产生原则性策略改进的条件,并界定了干预学习预期会失效的机制范围。实验表明,残差微调能够在多种干预策略和先验策略质量下实现鲁棒且一致的策略改进,从而凸显了鲁棒干预学习作为未来研究方向的潜力。