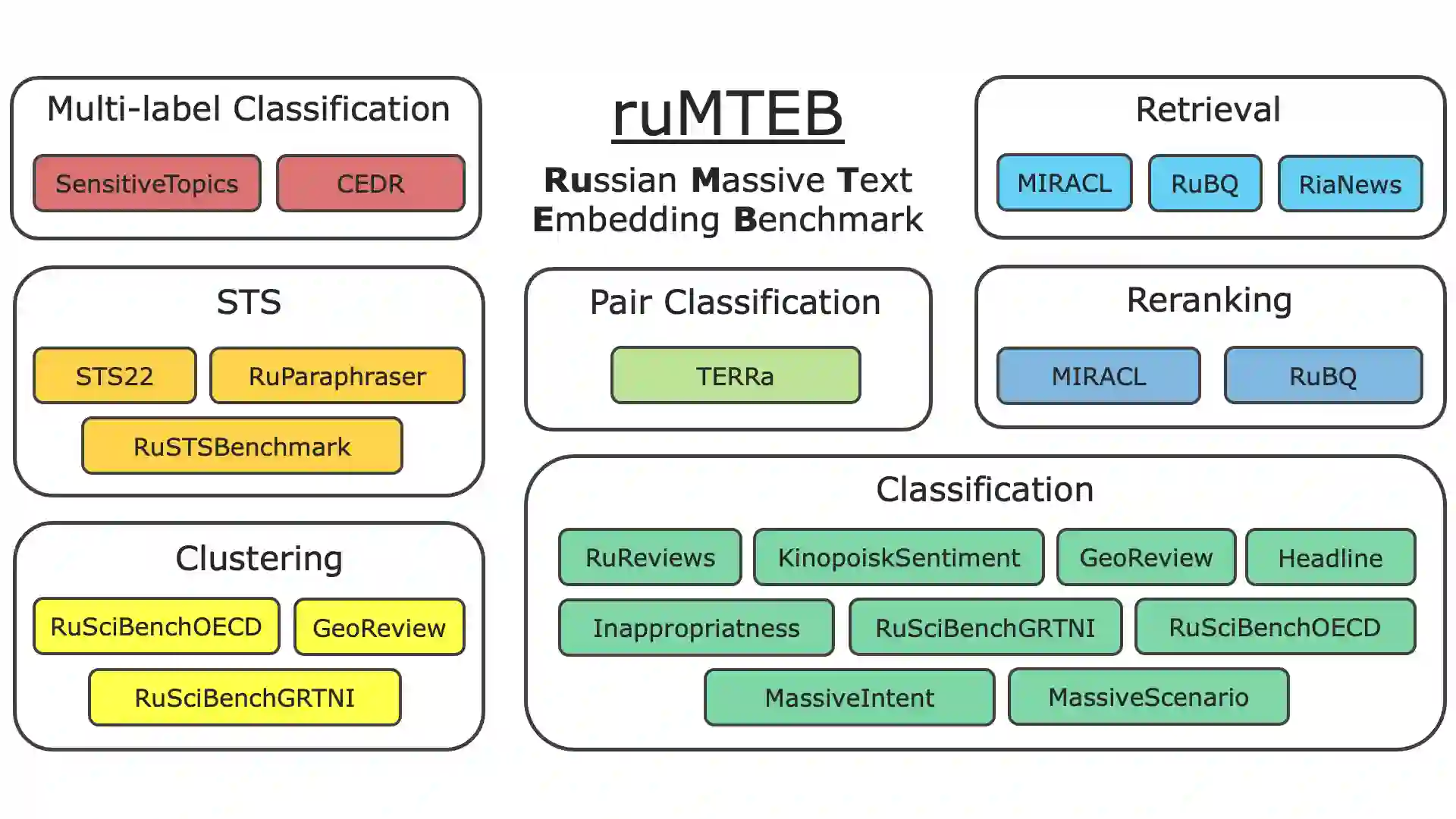
Embedding models play a crucial role in Natural Language Processing (NLP) by creating text embeddings used in various tasks such as information retrieval and assessing semantic text similarity. This paper focuses on research related to embedding models in the Russian language. It introduces a new Russian-focused embedding model called ru-en-RoSBERTa and the ruMTEB benchmark, the Russian version extending the Massive Text Embedding Benchmark (MTEB). Our benchmark includes seven categories of tasks, such as semantic textual similarity, text classification, reranking, and retrieval. The research also assesses a representative set of Russian and multilingual models on the proposed benchmark. The findings indicate that the new model achieves results that are on par with state-of-the-art models in Russian. We release the model ru-en-RoSBERTa, and the ruMTEB framework comes with open-source code, integration into the original framework and a public leaderboard.
翻译:嵌入模型在自然语言处理(NLP)中发挥着至关重要的作用,它生成的文本嵌入被广泛应用于信息检索、语义文本相似度评估等多种任务。本文聚焦于俄语嵌入模型的相关研究,提出了一个专注于俄语的新嵌入模型ru-en-RoSBERTa,并构建了俄语版大规模文本嵌入基准测试ruMTEB,该基准扩展自原版MTEB。我们的基准测试涵盖七类任务,包括语义文本相似度、文本分类、重排序和检索等。研究还在该基准上评估了一系列具有代表性的俄语及多语言模型。结果表明,新模型在俄语任务上取得了与当前最优模型相当的性能。我们发布了ru-en-RoSBERTa模型,ruMTEB框架则提供了开源代码、与原框架的集成方案以及公开排行榜。