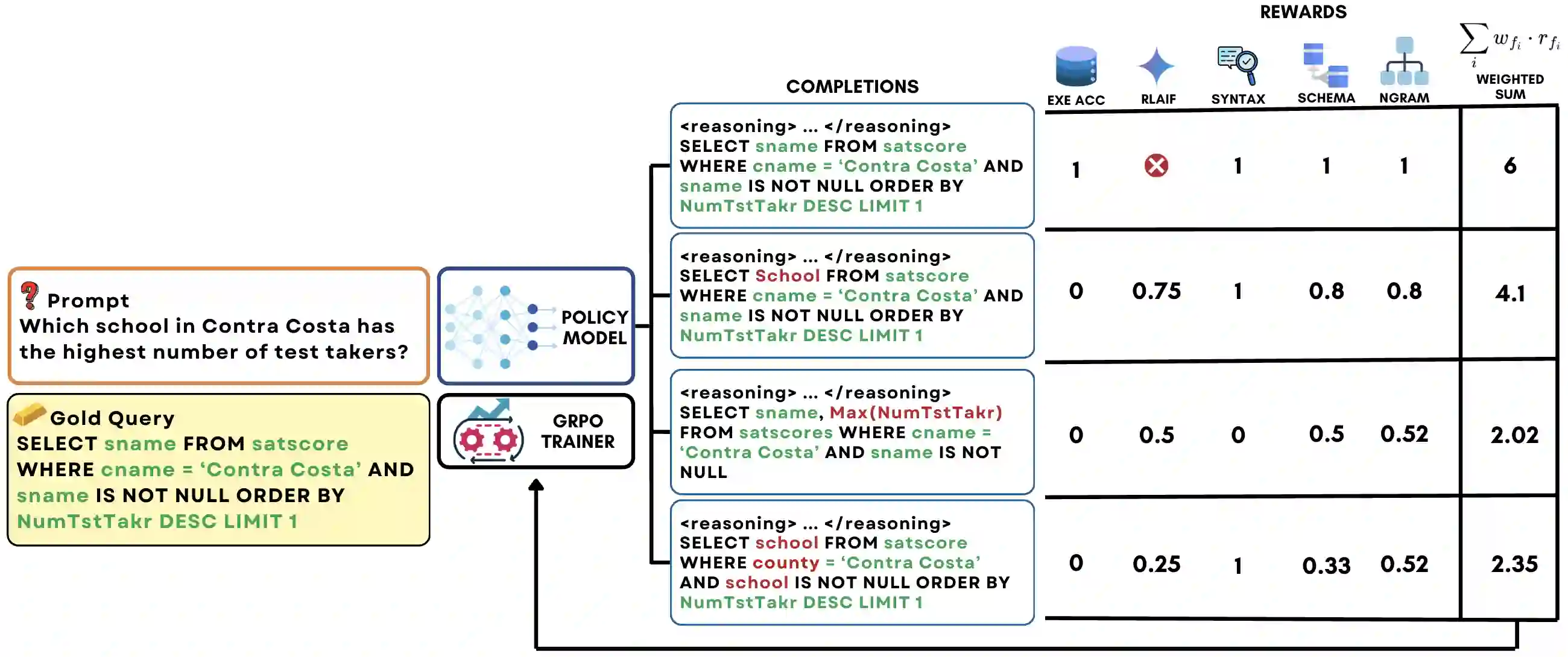
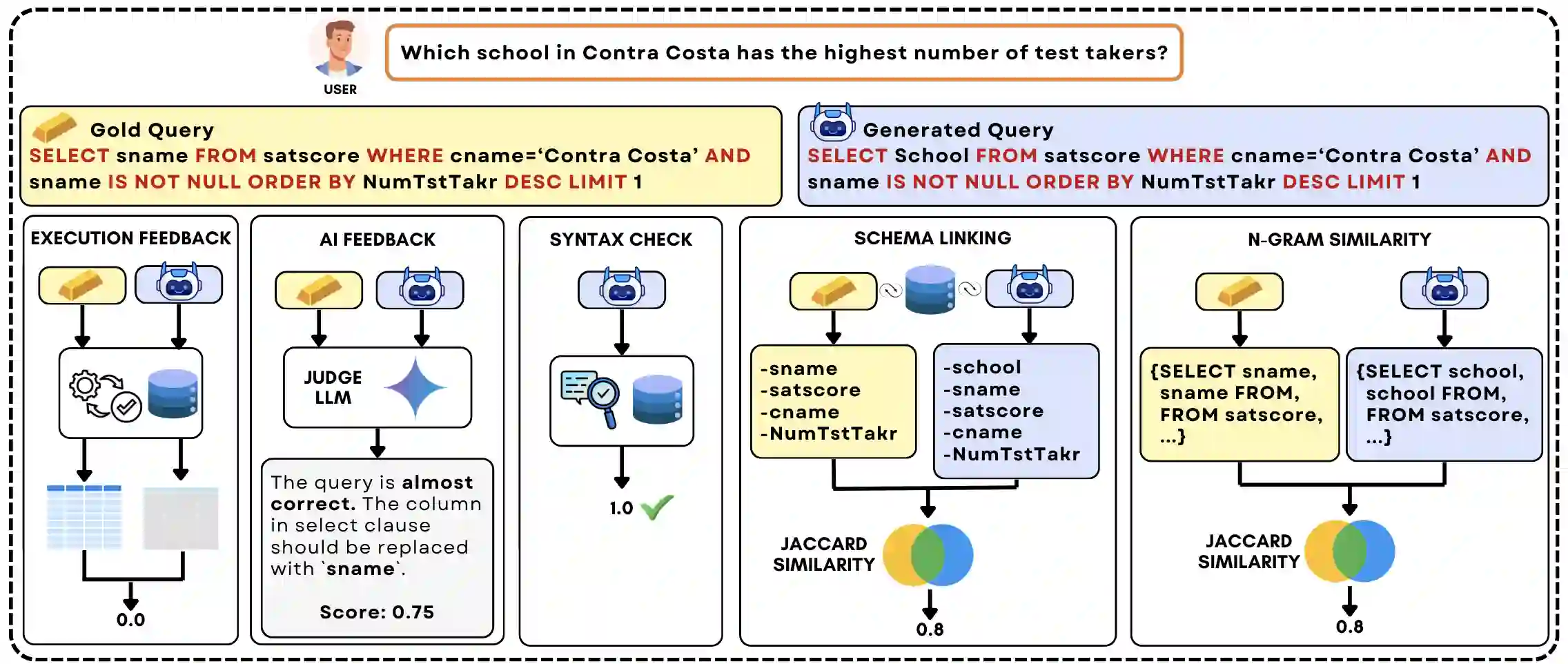
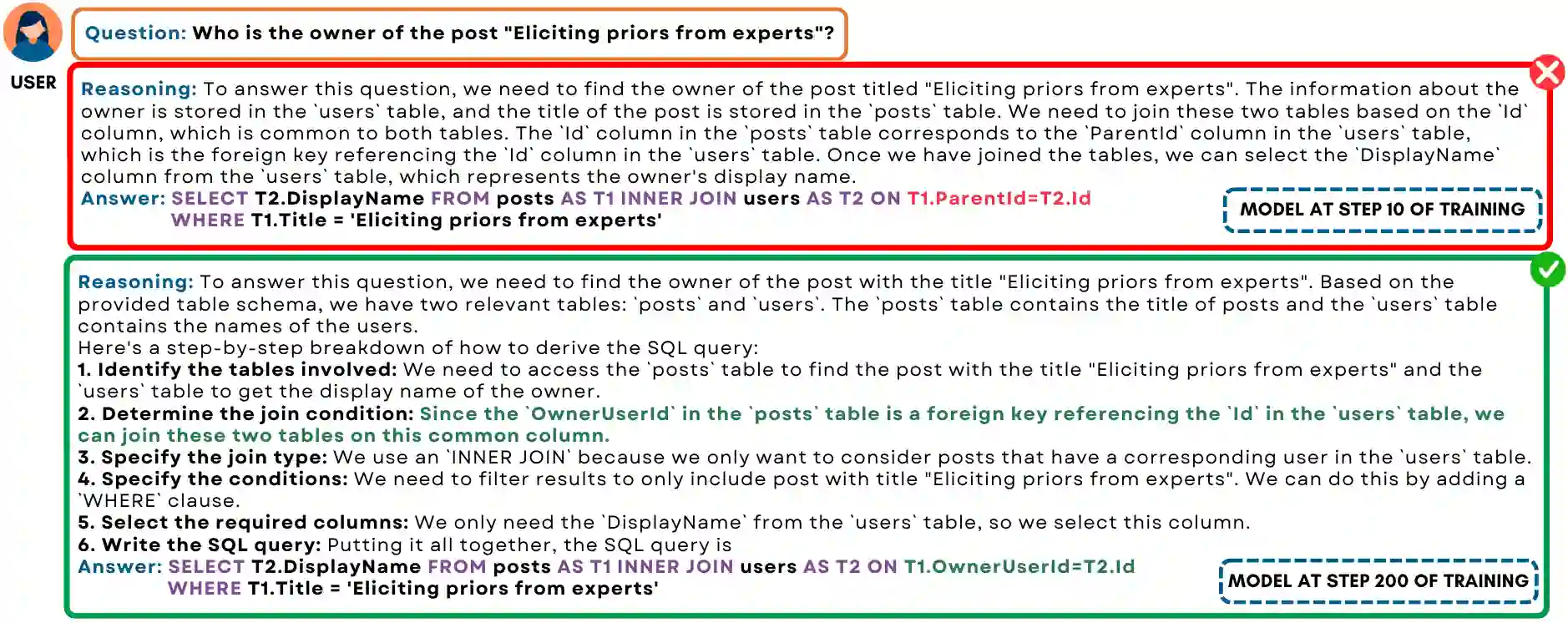
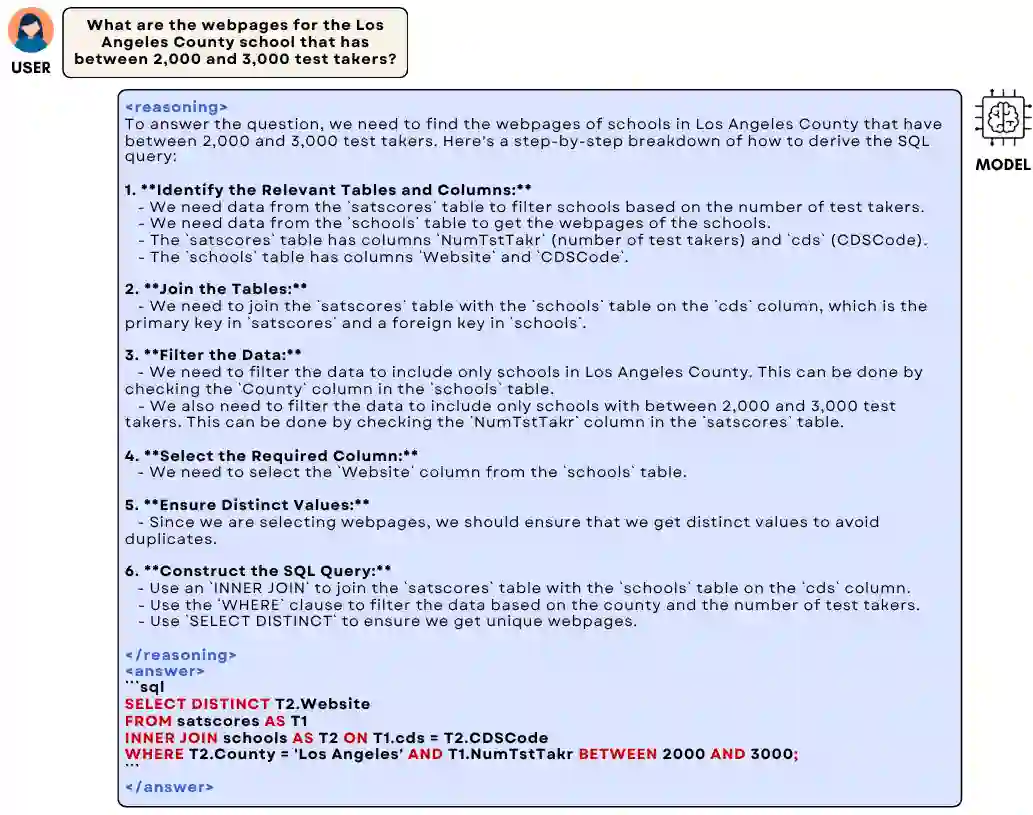
Text-to-SQL is a challenging task involving multiple reasoning-intensive subtasks, including natural language understanding, database schema comprehension, and precise SQL query formulation. Existing approaches often rely on handcrafted reasoning paths with inductive biases that can limit their overall effectiveness. Motivated by the recent success of reasoning-enhanced models such as DeepSeek R1 and OpenAI o1, which effectively leverage reward-driven self-exploration to enhance reasoning capabilities and generalization, we propose a novel set of partial rewards tailored specifically for the Text-to-SQL task. Our reward set includes schema-linking, AI feedback, n-gram similarity, and syntax check, explicitly designed to address the reward sparsity issue prevalent in reinforcement learning (RL). Leveraging group relative policy optimization (GRPO), our approach explicitly encourages large language models (LLMs) to develop intrinsic reasoning skills necessary for accurate SQL query generation. With models of different sizes, we demonstrate that RL-only training with our proposed rewards consistently achieves higher accuracy and superior generalization compared to supervised fine-tuning (SFT). Remarkably, our RL-trained 14B-parameter model significantly outperforms larger proprietary models, e.g. o3-mini by 4% and Gemini-1.5-Pro-002 by 3% on the BIRD benchmark. These highlight the efficacy of our proposed RL-training framework with partial rewards for enhancing both accuracy and reasoning capabilities in Text-to-SQL tasks.
翻译:文本到SQL是一项具有挑战性的任务,涉及多个推理密集型子任务,包括自然语言理解、数据库模式理解和精确的SQL查询构建。现有方法通常依赖于带有归纳偏置的手工推理路径,这可能限制其整体有效性。受近期推理增强模型(如DeepSeek R1和OpenAI o1)成功的启发——这些模型有效利用奖励驱动的自我探索来增强推理能力和泛化性——我们提出了一套专为文本到SQL任务定制的新型部分奖励集合。我们的奖励集合包括模式链接、AI反馈、n-gram相似性和语法检查,这些奖励被明确设计用于解决强化学习中普遍存在的奖励稀疏性问题。通过利用组相对策略优化,我们的方法明确鼓励大语言模型发展出准确生成SQL查询所需的内在推理技能。在不同规模的模型上,我们证明了仅使用我们提出的奖励进行强化学习训练,相较于监督微调,能够持续获得更高的准确率和更优的泛化能力。值得注意的是,我们通过强化学习训练的140亿参数模型在BIRD基准测试上显著优于更大的专有模型,例如比o3-mini高出4%,比Gemini-1.5-Pro-002高出3%。这些结果凸显了我们提出的带有部分奖励的强化学习训练框架在提升文本到SQL任务准确性和推理能力方面的有效性。