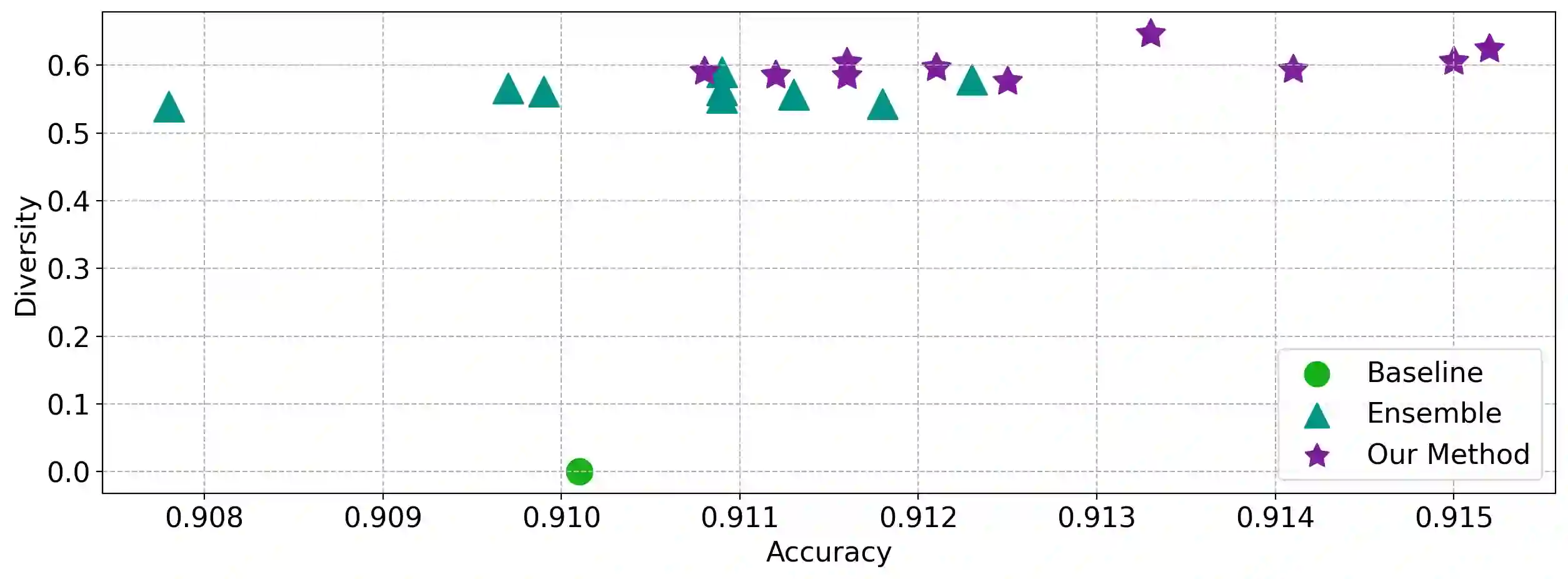
Ensembling a neural network is a widely recognized approach to enhance model performance, estimate uncertainty, and improve robustness in deep supervised learning. However, deep ensembles often come with high computational costs and memory demands. In addition, the efficiency of a deep ensemble is related to diversity among the ensemble members which is challenging for large, over-parameterized deep neural networks. Moreover, ensemble learning has not yet seen such widespread adoption, and it remains a challenging endeavor for self-supervised or unsupervised representation learning. Motivated by these challenges, we present a novel self-supervised training regime that leverages an ensemble of independent sub-networks, complemented by a new loss function designed to encourage diversity. Our method efficiently builds a sub-model ensemble with high diversity, leading to well-calibrated estimates of model uncertainty, all achieved with minimal computational overhead compared to traditional deep self-supervised ensembles. To evaluate the effectiveness of our approach, we conducted extensive experiments across various tasks, including in-distribution generalization, out-of-distribution detection, dataset corruption, and semi-supervised settings. The results demonstrate that our method significantly improves prediction reliability. Our approach not only achieves excellent accuracy but also enhances calibration, surpassing baseline performance across a wide range of self-supervised architectures in computer vision, natural language processing, and genomics data.
翻译:神经网络集成是深度监督学习中提升模型性能、估计不确定性以及改善鲁棒性的一种广泛认可的方法。然而,深度集成通常伴随高昂的计算成本和内存需求。此外,深度集成的效率与集成成员之间的多样性相关,而对于大规模、过参数化的深度神经网络而言,实现这种多样性颇具挑战。不仅如此,集成学习在自监督或无监督表示学习领域尚未得到如此广泛的采用,仍然是一项具有挑战性的任务。针对这些挑战,我们提出了一种新颖的自监督训练范式,利用独立子网络集成,并辅以专为鼓励多样性而设计的新损失函数。我们的方法高效地构建了一个具有高多样性的子模型集成,从而得到校准良好的模型不确定性估计,且相较于传统的深度自监督集成,仅带来最小的计算开销。为评估我们方法的有效性,我们在多种任务上进行了广泛实验,包括分布内泛化、分布外检测、数据集损坏以及半监督场景。结果表明,我们的方法显著提升了预测可靠性。我们的方法不仅实现了卓越的准确性,还改善了校准性能,在计算机视觉、自然语言处理和基因组学数据等多种自监督架构上均超越了基线表现。