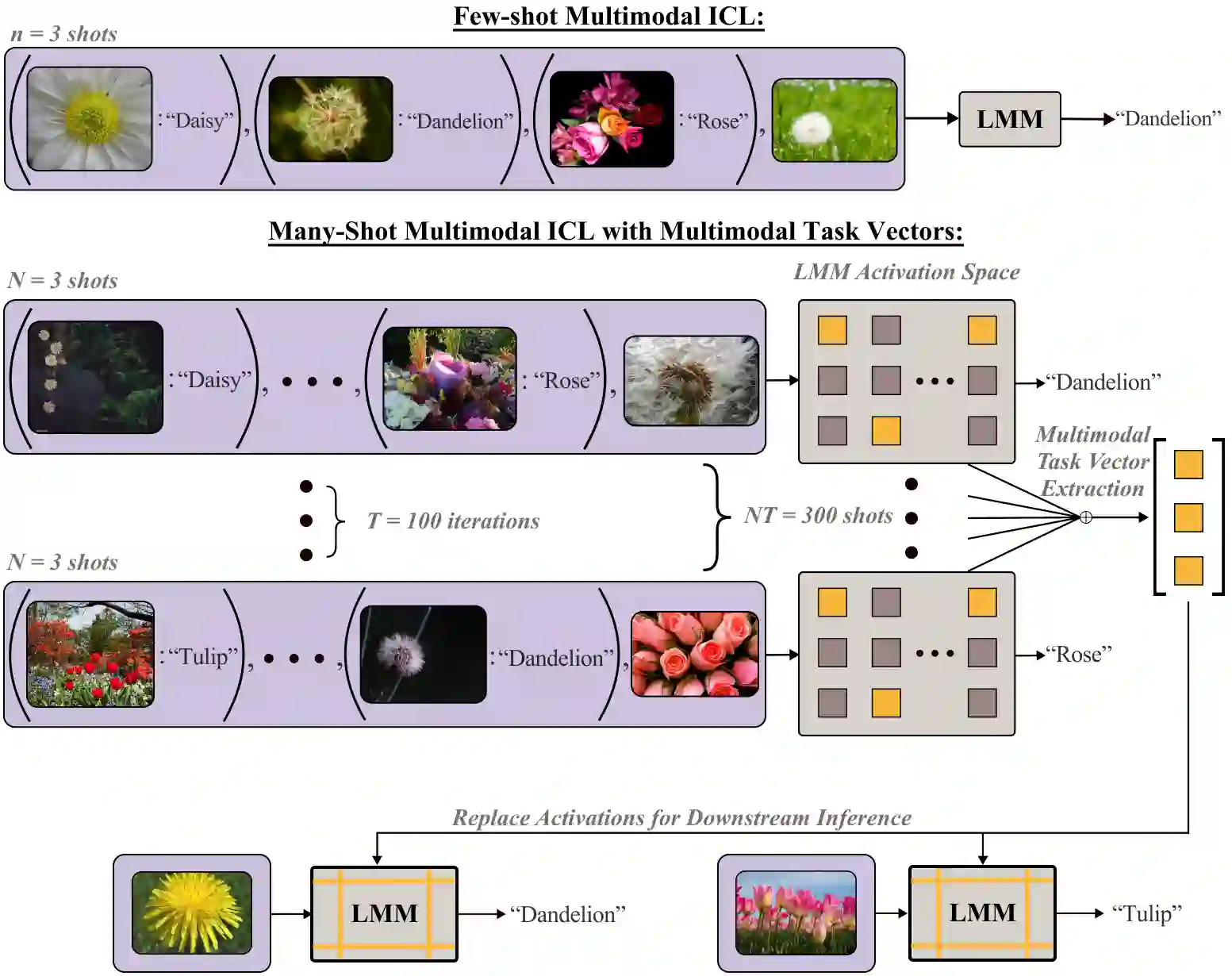
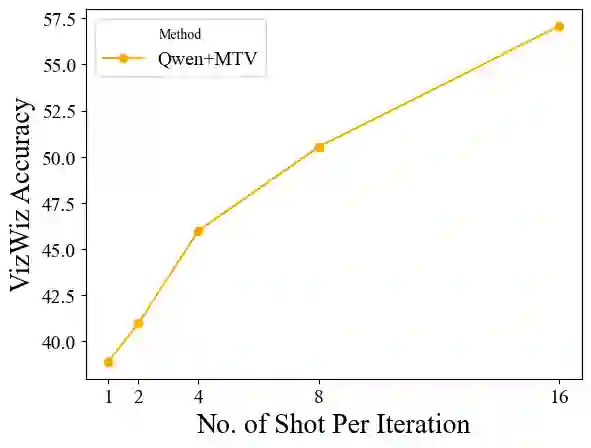
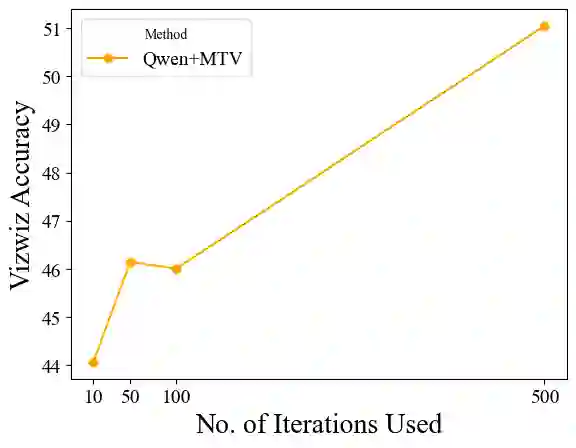
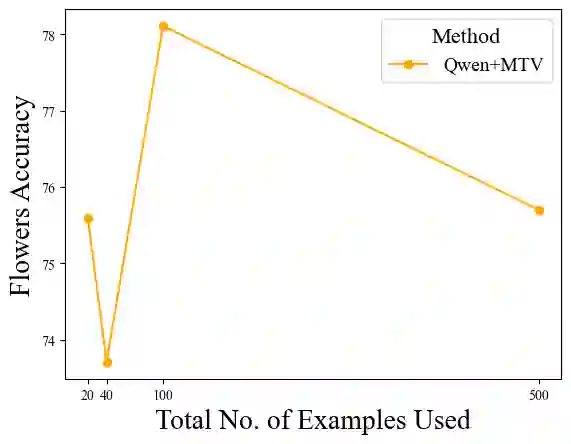
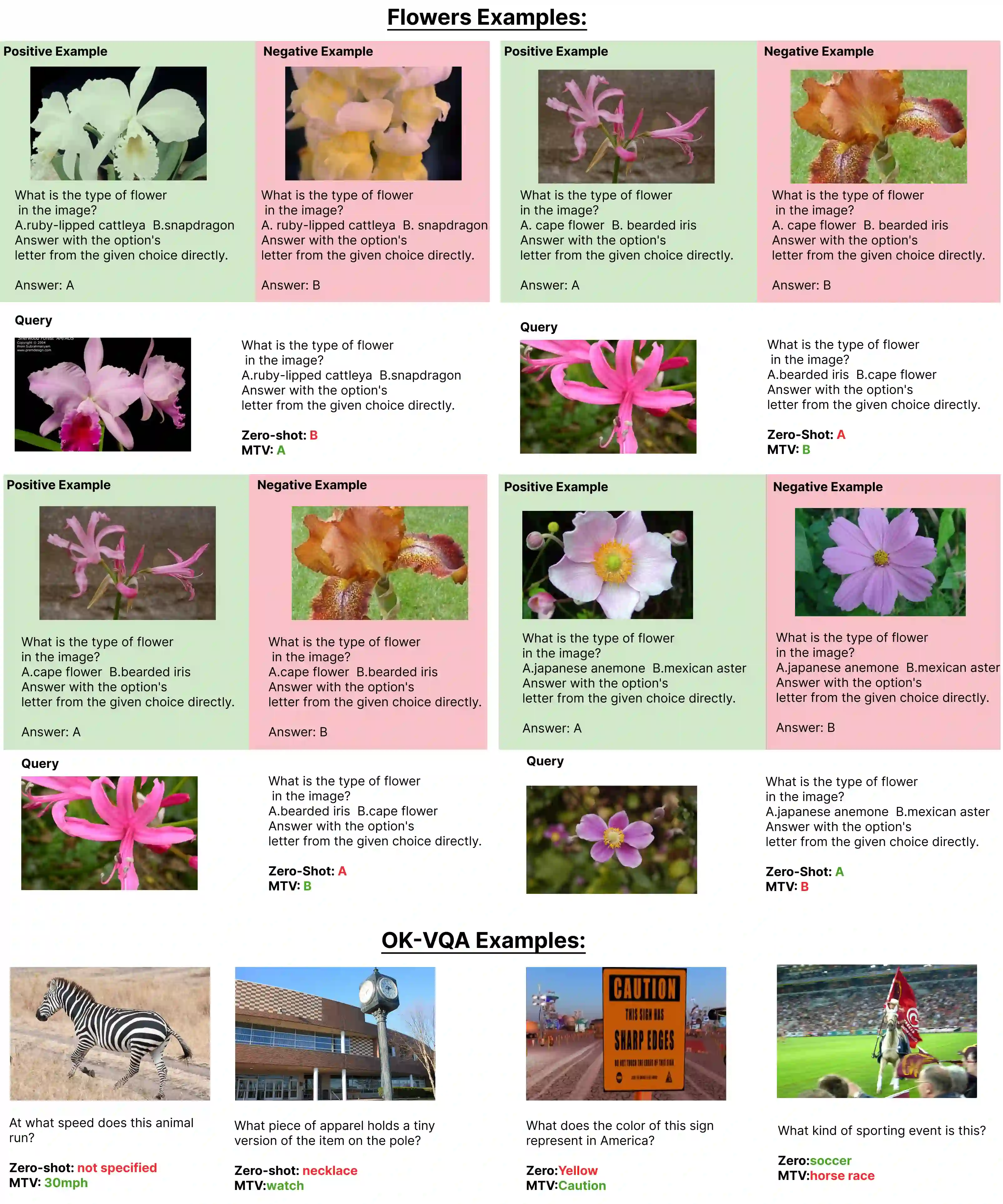
The recent success of interleaved Large Multimodal Models (LMMs) in few-shot learning suggests that in-context learning (ICL) with many examples can be promising for learning new tasks. However, this many-shot multimodal ICL setting has one crucial problem: it is fundamentally limited by the model's context length set at pretraining. The problem is especially prominent in the multimodal domain, which processes both text and images, requiring additional tokens. This motivates the need for a multimodal method to compress many shots into fewer tokens without finetuning. In this work, we enable LMMs to perform multimodal, many-shot in-context learning by leveraging Multimodal Task Vectors (MTV)--compact implicit representations of in-context examples compressed in the model's attention heads. Specifically, we first demonstrate the existence of such MTV in LMMs and then leverage these extracted MTV to enable many-shot in-context learning for various vision-and-language tasks. Our experiments suggest that MTV can scale in performance with the number of compressed shots and generalize to similar out-of-domain tasks without additional context length for inference.
翻译:近期,交错式大型多模态模型在少样本学习中的成功表明,利用大量示例进行上下文学习有望成为学习新任务的有效途径。然而,这种多模态多示例上下文学习设置存在一个关键问题:其根本上受到预训练阶段设定的模型上下文长度限制。该问题在多模态领域尤为突出,因为需要同时处理文本和图像,占用额外的标记空间。这促使我们寻求一种无需微调即可将大量示例压缩至更少标记的多模态方法。本研究通过利用多模态任务向量——一种压缩在模型注意力头中的上下文示例的紧凑隐式表示,使大型多模态模型能够执行多模态多示例上下文学习。具体而言,我们首先验证了此类MTV在大型多模态模型中的存在性,进而利用提取的MTV为多种视觉-语言任务实现多示例上下文学习。实验表明,MTV的性能可随压缩示例数量扩展,并能泛化至相似的域外任务,且无需在推理阶段增加上下文长度。