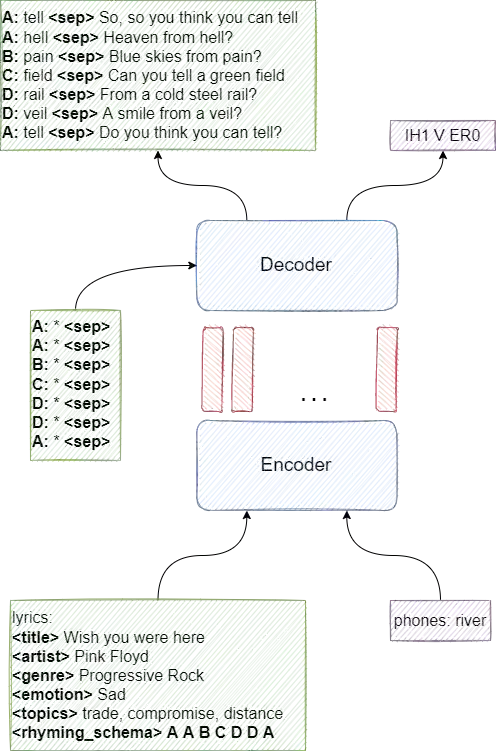
Composing poetry or lyrics involves several creative factors, but a challenging aspect of generation is the adherence to a more or less strict metric and rhyming pattern. To address this challenge specifically, previous work on the task has mainly focused on reverse language modeling, which brings the critical selection of each rhyming word to the forefront of each verse. On the other hand, reversing the word order requires that models be trained from scratch with this task-specific goal and cannot take advantage of transfer learning from a Pretrained Language Model (PLM). We propose a novel fine-tuning approach that prepends the rhyming word at the start of each lyric, which allows the critical rhyming decision to be made before the model commits to the content of the lyric (as during reverse language modeling), but maintains compatibility with the word order of regular PLMs as the lyric itself is still generated in left-to-right order. We conducted extensive experiments to compare this fine-tuning against the current state-of-the-art strategies for rhyming, finding that our approach generates more readable text and better rhyming capabilities. Furthermore, we furnish a high-quality dataset in English and 12 other languages, analyse the approach's feasibility in a multilingual context, provide extensive experimental results shedding light on good and bad practices for lyrics generation, and propose metrics to compare methods in the future.
翻译:诗歌或歌词的创作涉及多种创意因素,但生成过程中一个具有挑战性的方面是遵循或多或少的严格韵律和押韵模式。为了专门应对这一挑战,以往的研究工作主要集中于反向语言建模,这将每个押韵词的关键选择推至每句诗的前沿。另一方面,反转词序要求模型针对这一特定任务目标从头开始训练,无法利用预训练语言模型的迁移学习优势。我们提出一种新颖的微调方法,将押韵词预置于每句歌词的开头,这既允许在模型确定歌词内容之前做出关键的押韵决策(如同反向语言建模),同时保持了与常规预训练语言模型词序的兼容性,因为歌词本身仍按从左到右的顺序生成。我们开展了广泛实验,将这种微调方法与当前最先进的押韵策略进行比较,发现我们的方法能生成更具可读性的文本并具有更好的押韵能力。此外,我们提供了英语及其他12种语言的高质量数据集,分析了该方法在多语言环境下的可行性,提供了揭示歌词生成良好实践与不良实践的广泛实验结果,并提出了未来用于比较方法的评估指标。