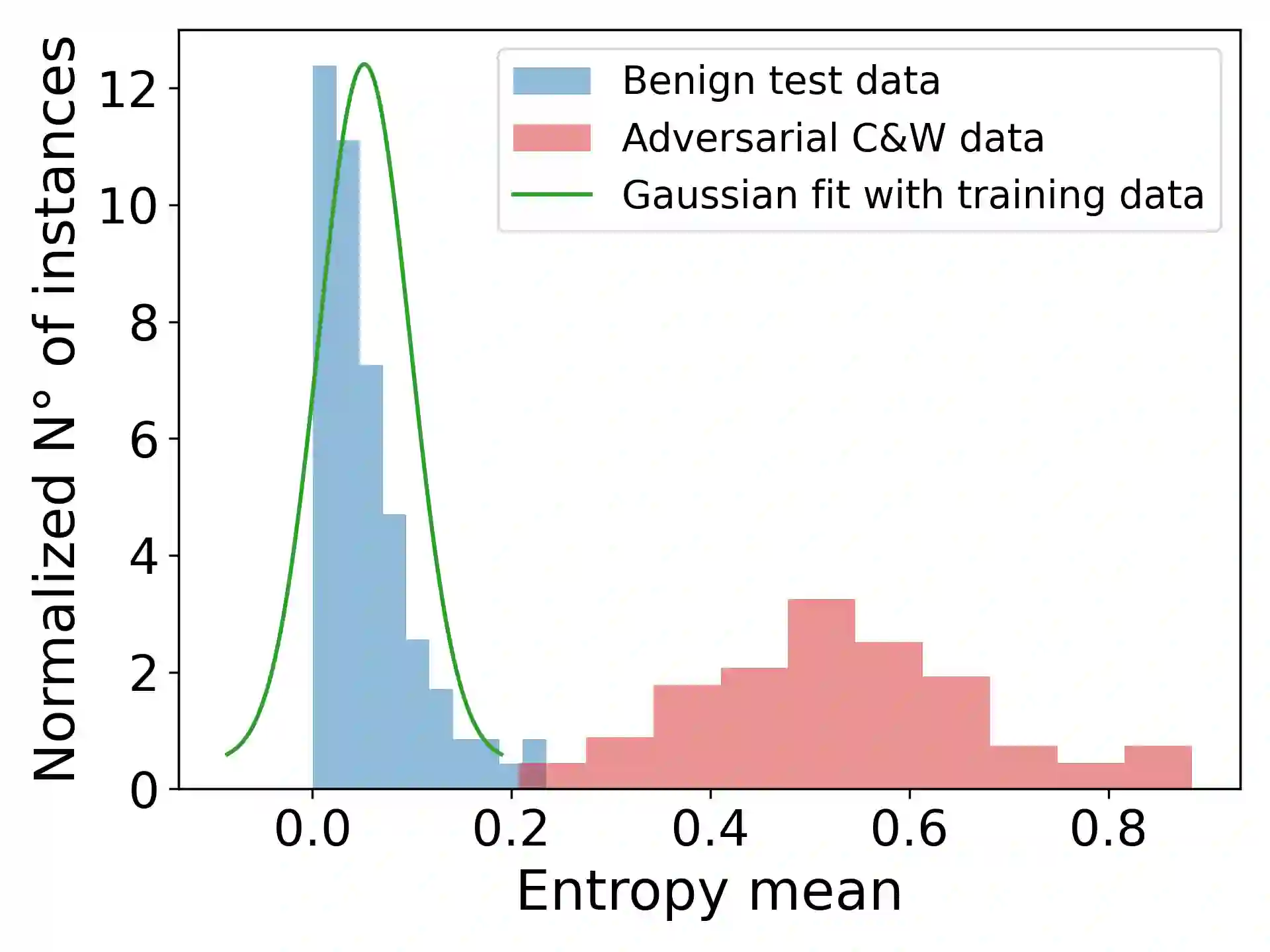
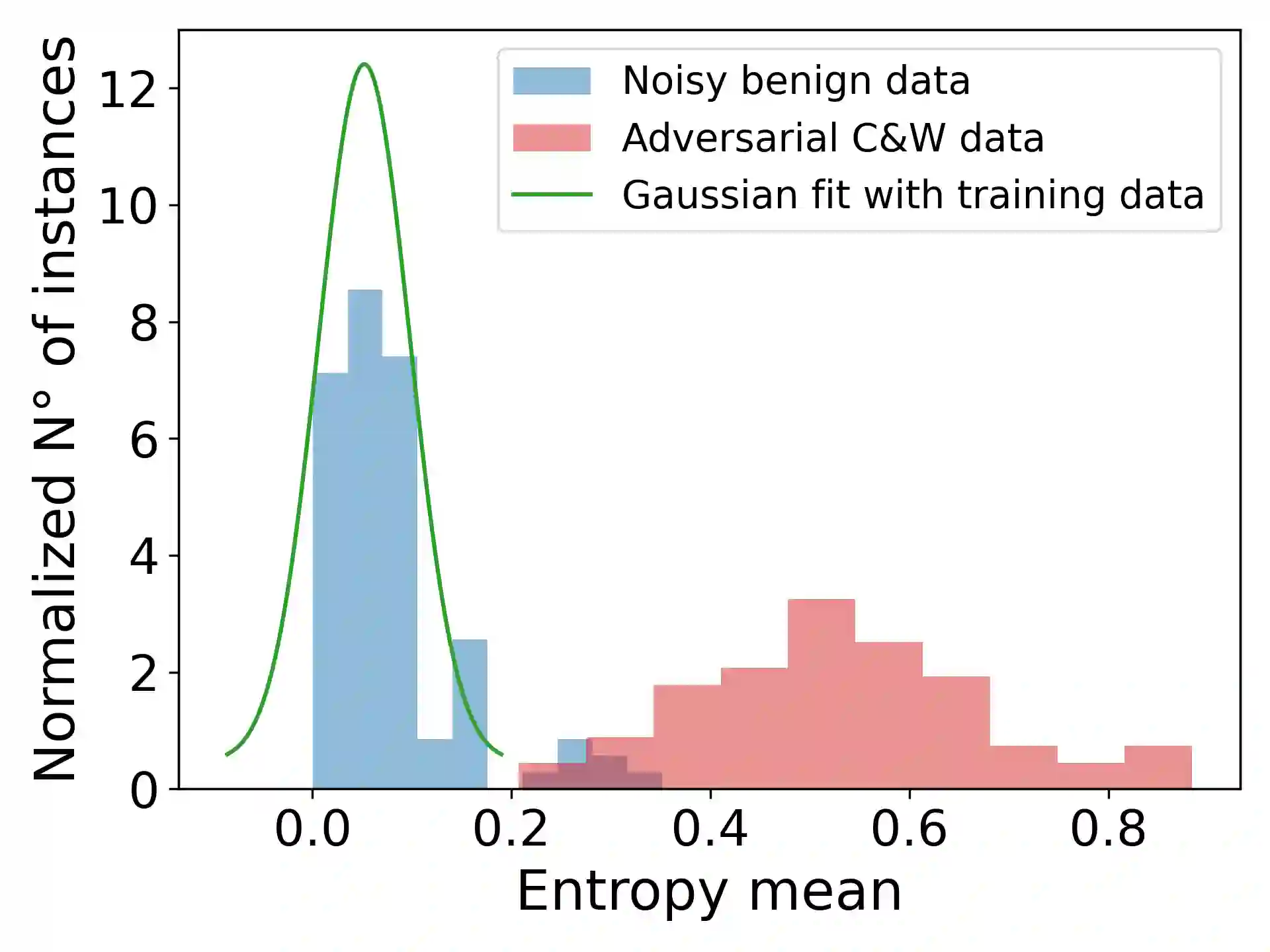
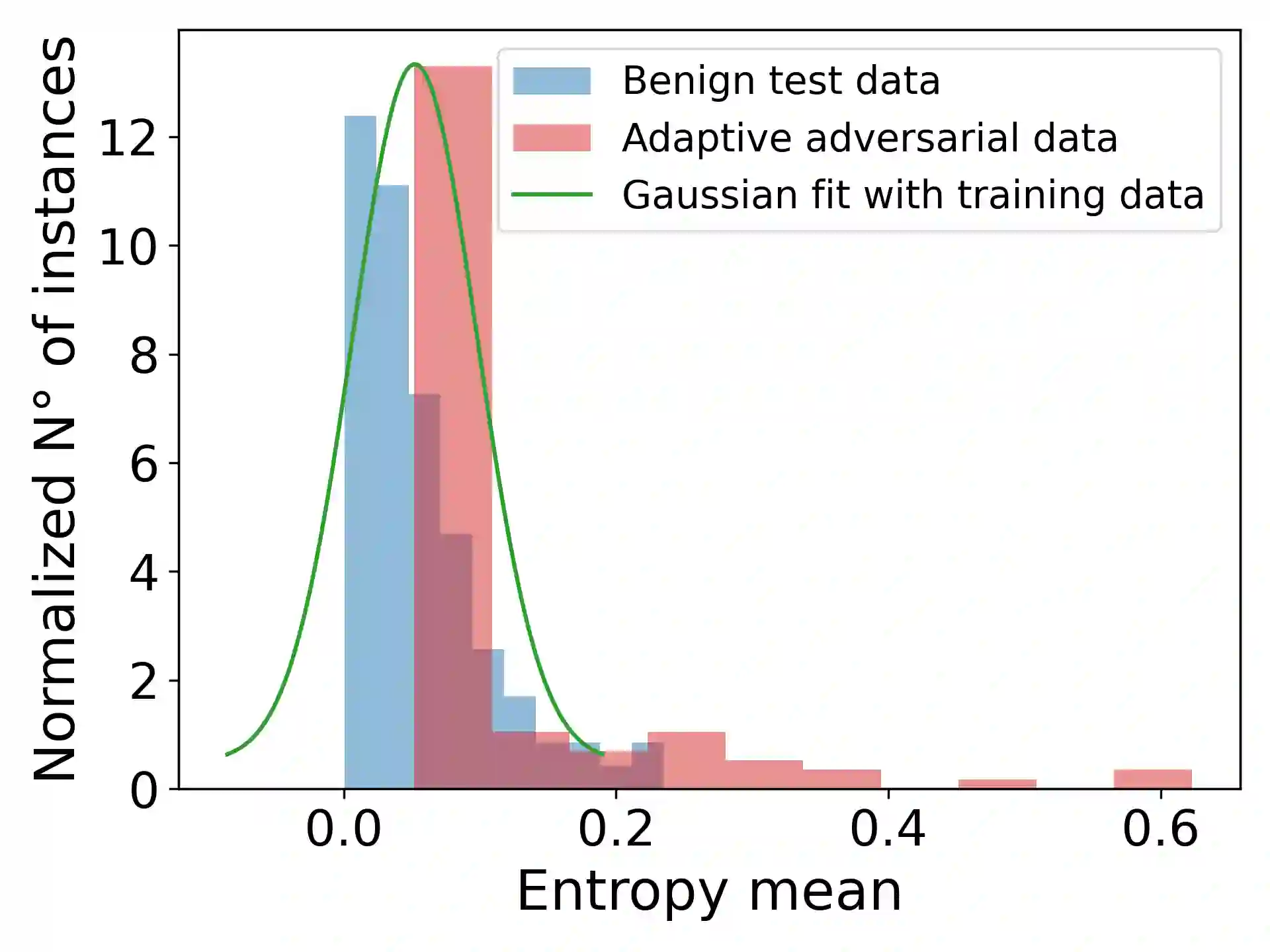
Adversarial attacks can mislead automatic speech recognition (ASR) systems into predicting an arbitrary target text, thus posing a clear security threat. To prevent such attacks, we propose DistriBlock, an efficient detection strategy applicable to any ASR system that predicts a probability distribution over output tokens in each time step. We measure a set of characteristics of this distribution: the median, maximum, and minimum over the output probabilities, the entropy of the distribution, as well as the Kullback-Leibler and the Jensen-Shannon divergence with respect to the distributions of the subsequent time step. Then, by leveraging the characteristics observed for both benign and adversarial data, we apply binary classifiers, including simple threshold-based classification, ensembles of such classifiers, and neural networks. Through extensive analysis across different state-of-the-art ASR systems and language data sets, we demonstrate the supreme performance of this approach, with a mean area under the receiver operating characteristic curve for distinguishing target adversarial examples against clean and noisy data of 99% and 97%, respectively. To assess the robustness of our method, we show that adaptive adversarial examples that can circumvent DistriBlock are much noisier, which makes them easier to detect through filtering and creates another avenue for preserving the system's robustness.
翻译:对抗性攻击可误导自动语音识别系统预测任意目标文本,从而构成明确的安全威胁。为防止此类攻击,我们提出DistriBlock——一种适用于任何在时间步上预测输出标记概率分布的ASR系统的高效检测策略。我们测量该分布的一组特征:输出概率的中位数、最大值与最小值、分布的熵,以及与后续时间步分布的Kullback-Leibler散度和Jensen-Shannon散度。通过利用在正常数据与对抗性数据中观察到的这些特征,我们应用二元分类器(包括基于简单阈值的分类器、此类分类器的集成模型以及神经网络)。通过对不同前沿ASR系统和语言数据集的广泛分析,我们证明了该方法具有卓越性能:在区分目标对抗样本与干净数据及含噪数据时,其接收者操作特征曲线下面积均值分别达到99%和97%。为评估本方法的鲁棒性,我们证明能够规避DistriBlock的自适应对抗样本会产生显著更强的噪声,这使其更容易通过滤波被检测,从而为维护系统鲁棒性开辟了新途径。