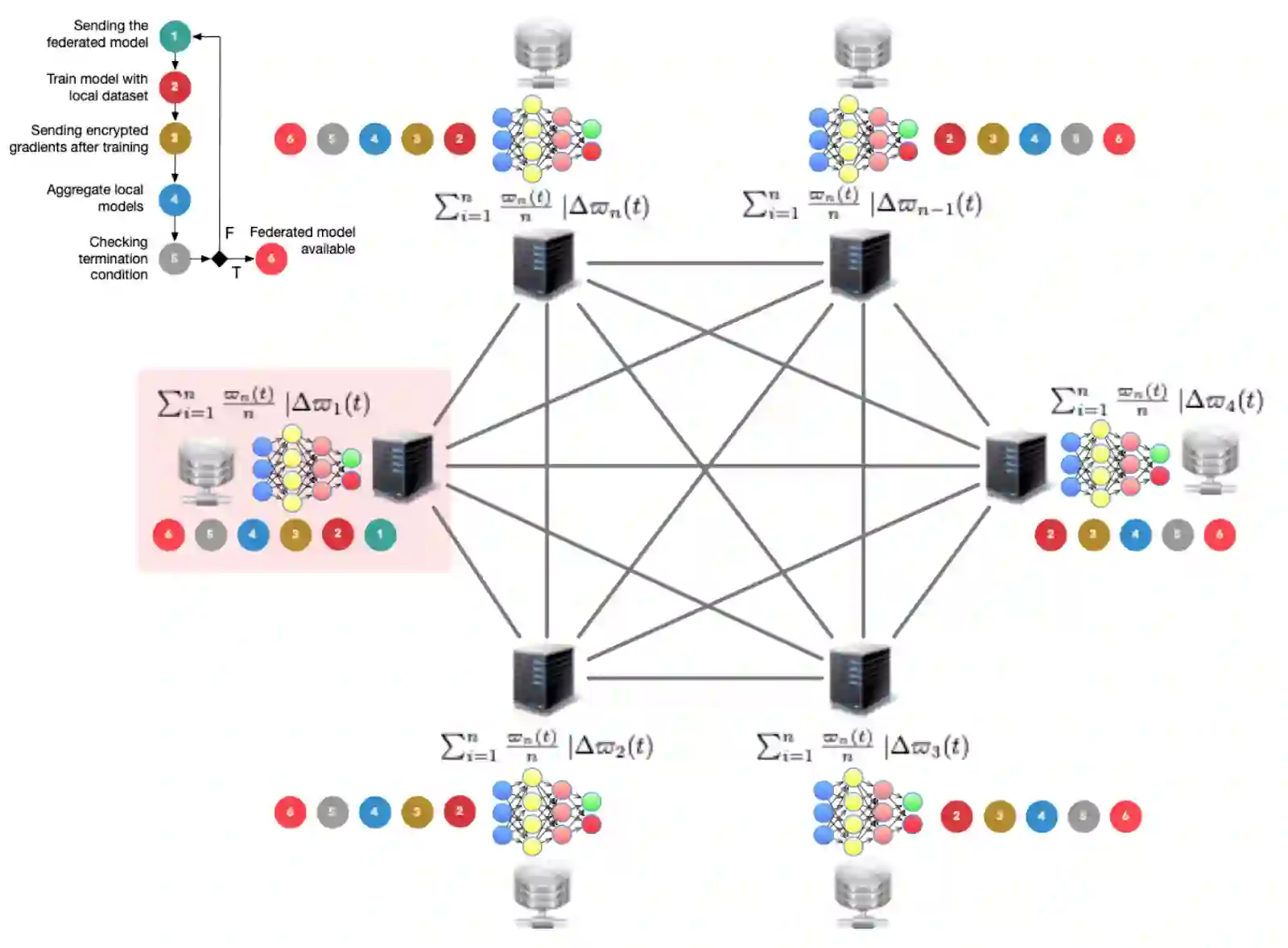
The increasing requirements for data protection and privacy has attracted a huge research interest on distributed artificial intelligence and specifically on federated learning, an emerging machine learning approach that allows the construction of a model between several participants who hold their own private data. In the initial proposal of federated learning the architecture was centralised and the aggregation was done with federated averaging, meaning that a central server will orchestrate the federation using the most straightforward averaging strategy. This research is focused on testing different federated strategies in a peer-to-peer environment. The authors propose various aggregation strategies for federated learning, including weighted averaging aggregation, using different factors and strategies based on participant contribution. The strategies are tested with varying data sizes to identify the most robust ones. This research tests the strategies with several biomedical datasets and the results of the experiments show that the accuracy-based weighted average outperforms the classical federated averaging method.
翻译:随着数据保护与隐私要求日益严格,分布式人工智能尤其是联邦学习这一新兴机器学习方法引发了广泛研究兴趣。该技术允许持有私有数据的多个参与者共同构建模型。在联邦学习的初始方案中,采用集中式架构并通过联邦平均算法进行聚合,即中央服务器使用最直接的平权平均策略协调联邦过程。本研究重点测试对等网络环境下的不同联邦策略。作者提出了多种联邦学习聚合策略,包括基于参与者贡献的差异化加权平均聚合方法。通过设置不同数据量规模进行测试,以识别最具鲁棒性的策略。实验基于多个生物医学数据集开展,结果表明基于准确率的加权平均方法优于传统联邦平均算法。