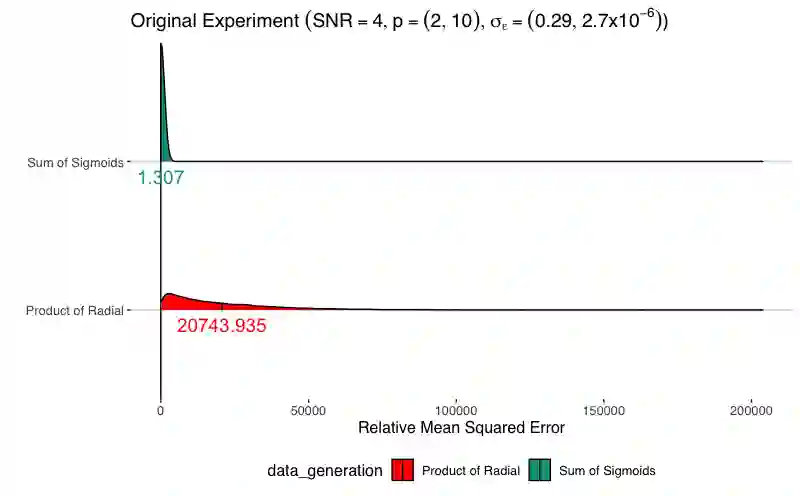
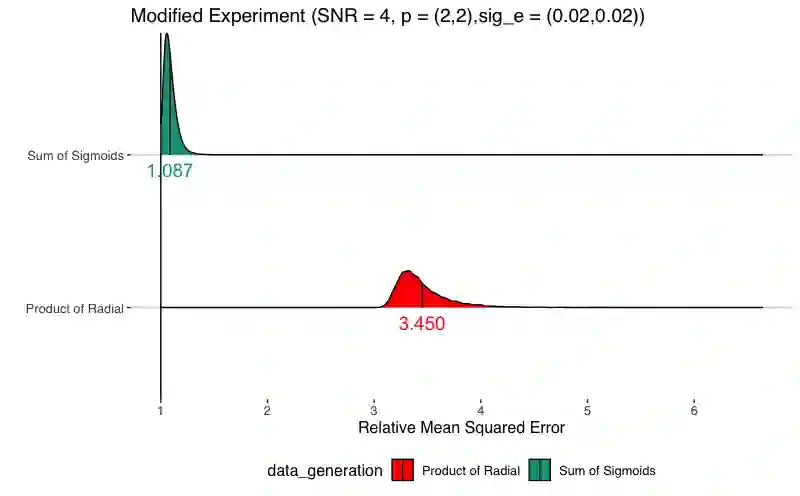
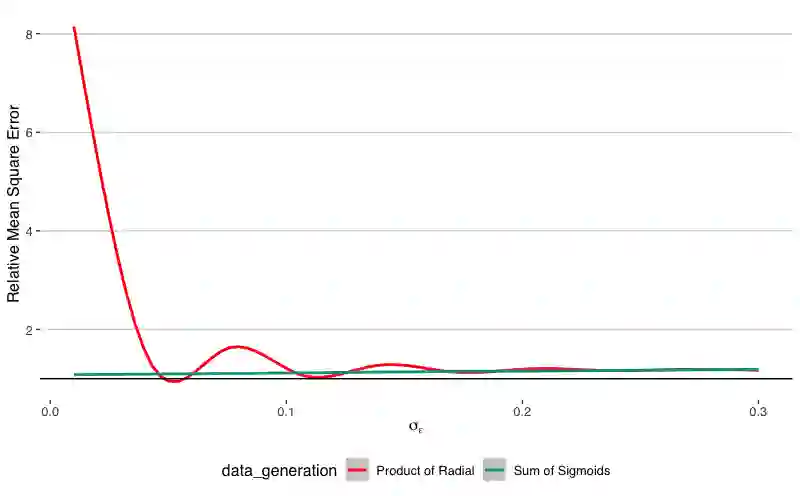
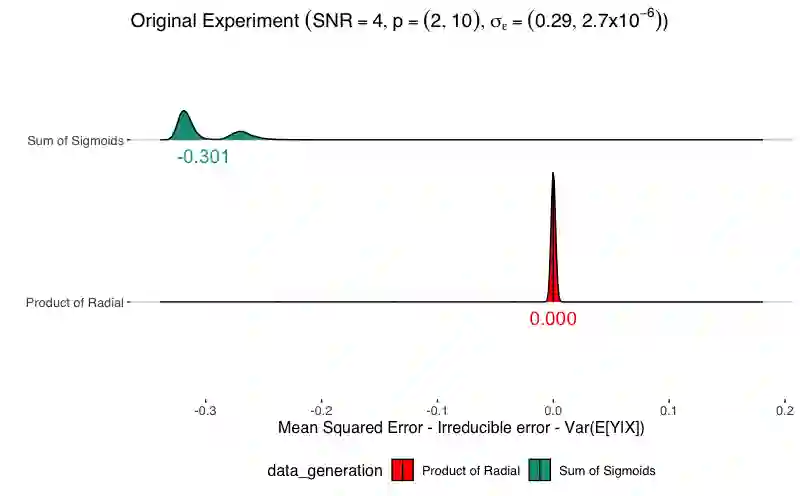
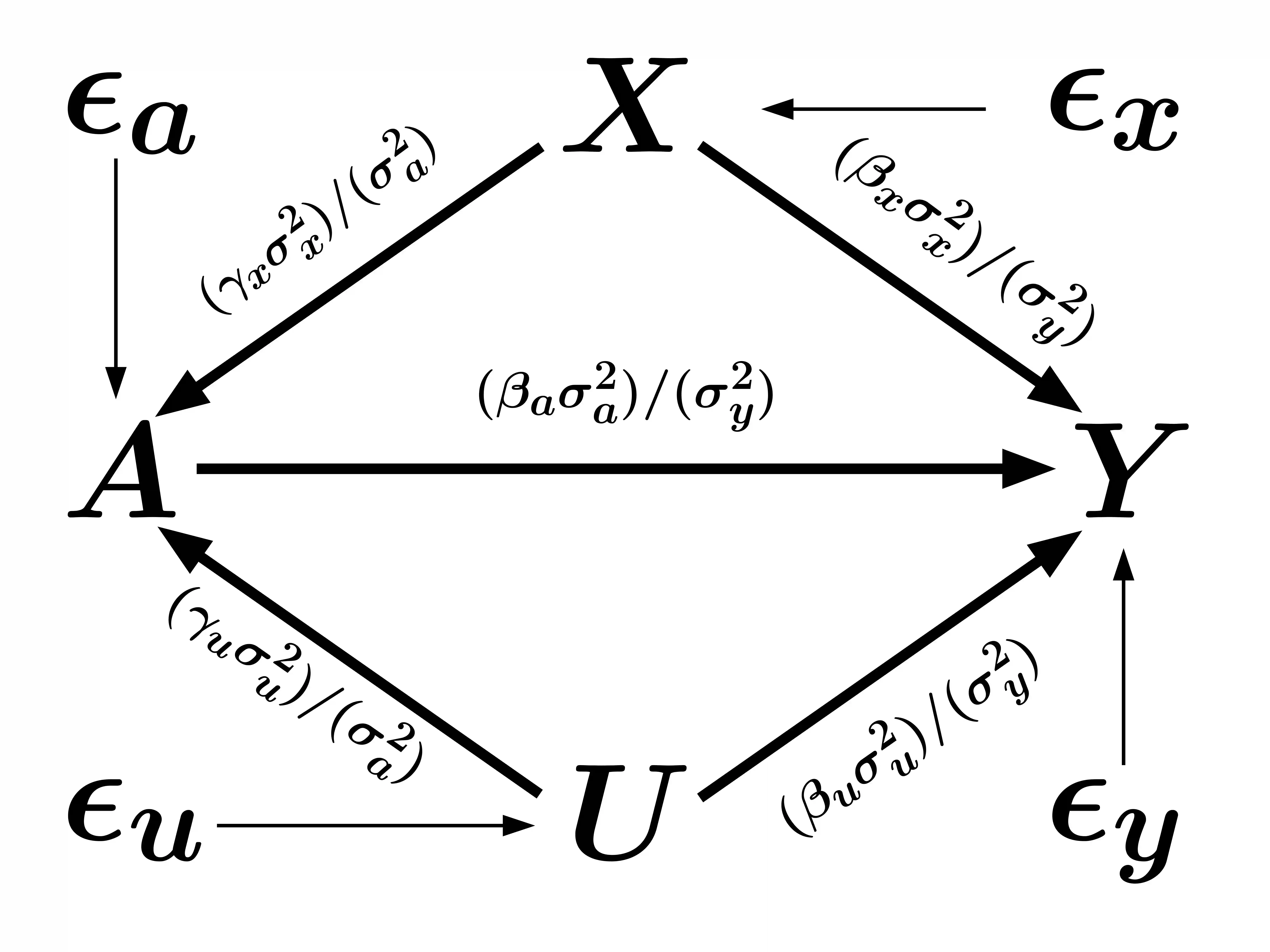
Simulation methods are among the most ubiquitous methodological tools in statistical science. In particular, statisticians often is simulation to explore properties of statistical functionals in models for which developed statistical theory is insufficient or to assess finite sample properties of theoretical results. We show that the design of simulation experiments can be viewed from the perspective of causal intervention on a data generating mechanism. We then demonstrate the use of causal tools and frameworks in this context. Our perspective is agnostic to the particular domain of the simulation experiment which increases the potential impact of our proposed approach. In this paper, we consider two illustrative examples. First, we re-examine a predictive machine learning example from a popular textbook designed to assess the relationship between mean function complexity and the mean-squared error. Second, we discuss a traditional causal inference method problem, simulating the effect of unmeasured confounding on estimation, specifically to illustrate bias amplification. In both cases, applying causal principles and using graphical models with parameters and distributions as nodes in the spirit of influence diagrams can 1) make precise which estimand the simulation targets , 2) suggest modifications to better attain the simulation goals, and 3) provide scaffolding to discuss performance criteria for a particular simulation design.
翻译:模拟方法是统计科学中最普遍的方法论工具之一。特别是,统计学家常通过模拟来探索理论发展不足的模型中统计泛函的性质,或评估理论结果的有限样本性质。我们表明,模拟实验的设计可从因果干预数据生成机制的角度来理解。接着,我们演示了在此背景下使用因果工具与框架的方法。我们的视角与模拟实验的具体领域无关,这提升了所提出方法的潜在影响。本文考虑了两个说明性示例。首先,我们重新审视了某著名教材中旨在评估均值函数复杂度与均方误差关系的预测机器学习案例。其次,我们讨论了传统因果推断方法问题,即模拟未测量混杂对估计的影响,具体用于说明偏差放大。在这两种情况下,应用因果原理并使用以参数和分布为节点(遵循影响图思想)的图模型,能够:1)明确模拟所针对的估计量,2)建议改进以更好实现模拟目标,3)为讨论特定模拟设计的性能标准提供框架。