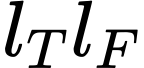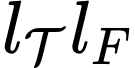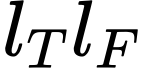Existing Transformers for monocular 3D human shape and pose estimation typically have a quadratic computation and memory complexity with respect to the feature length, which hinders the exploitation of fine-grained information in high-resolution features that is beneficial for accurate reconstruction. In this work, we propose an SMPL-based Transformer framework (SMPLer) to address this issue. SMPLer incorporates two key ingredients: a decoupled attention operation and an SMPL-based target representation, which allow effective utilization of high-resolution features in the Transformer. In addition, based on these two designs, we also introduce several novel modules including a multi-scale attention and a joint-aware attention to further boost the reconstruction performance. Extensive experiments demonstrate the effectiveness of SMPLer against existing 3D human shape and pose estimation methods both quantitatively and qualitatively. Notably, the proposed algorithm achieves an MPJPE of 45.2 mm on the Human3.6M dataset, improving upon Mesh Graphormer by more than 10% with fewer than one-third of the parameters. Code and pretrained models are available at https://github.com/xuxy09/SMPLer.
翻译:针对单目三维人体形状与姿态估计的现有Transformer方法通常在特征长度上具有二次复杂度的计算与内存开销,这阻碍了高分辨率特征中有利于精确重建的细粒度信息的利用。为解决此问题,本文提出基于SMPL的Transformer框架(SMPLer)。SMPLer包含两个关键设计:解耦注意力操作与基于SMPL的目标表示,使Transformer能够有效利用高分辨率特征。此外,基于这两项设计,我们进一步引入多尺度注意力和联合感知注意力等新型模块以提升重建性能。大量实验从定量与定性角度证明了SMPLer相较于现有三维人体形状与姿态估计方法的有效性。值得注意的是,所提算法在Human3.6M数据集上达到45.2毫米的MPJPE,相较于Mesh Graphormer性能提升超过10%且参数量不足其三分之一。代码与预训练模型已开源至https://github.com/xuxy09/SMPLer。