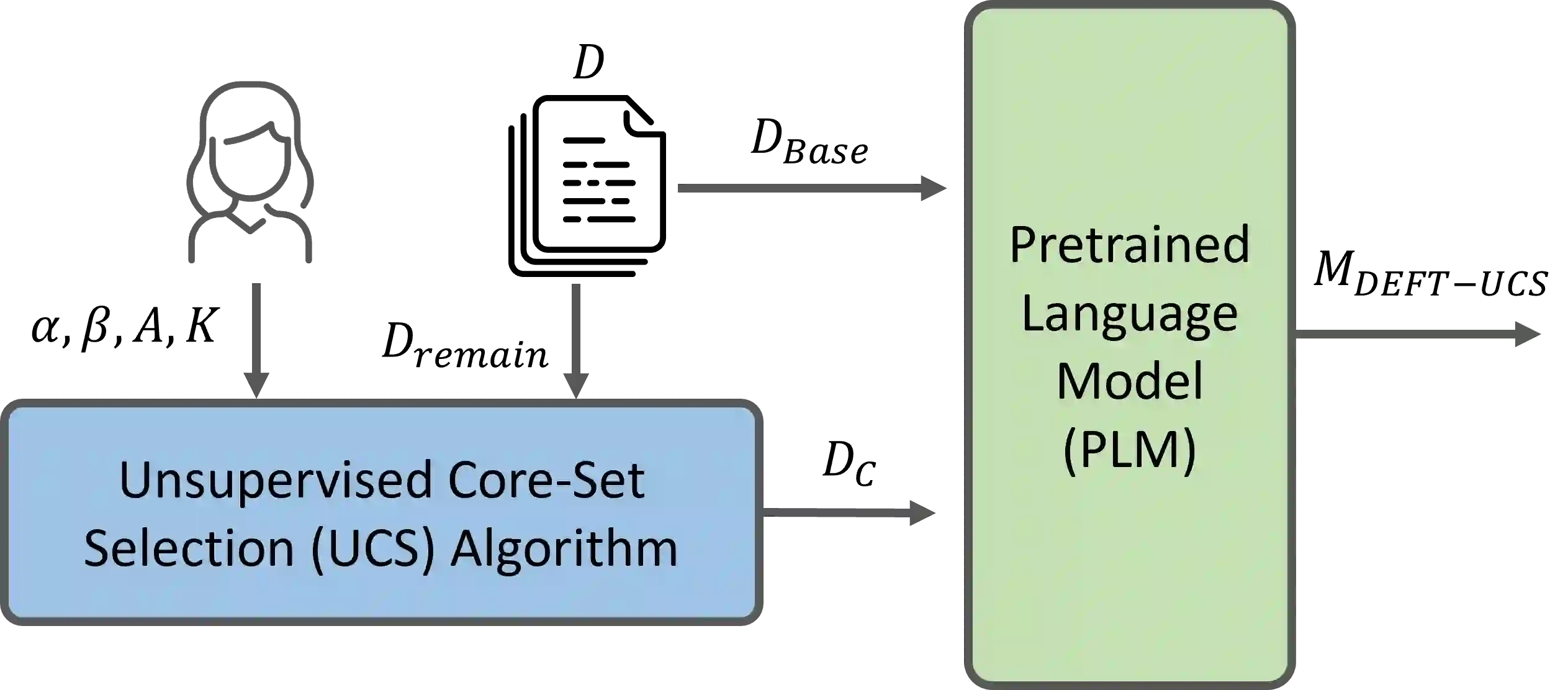
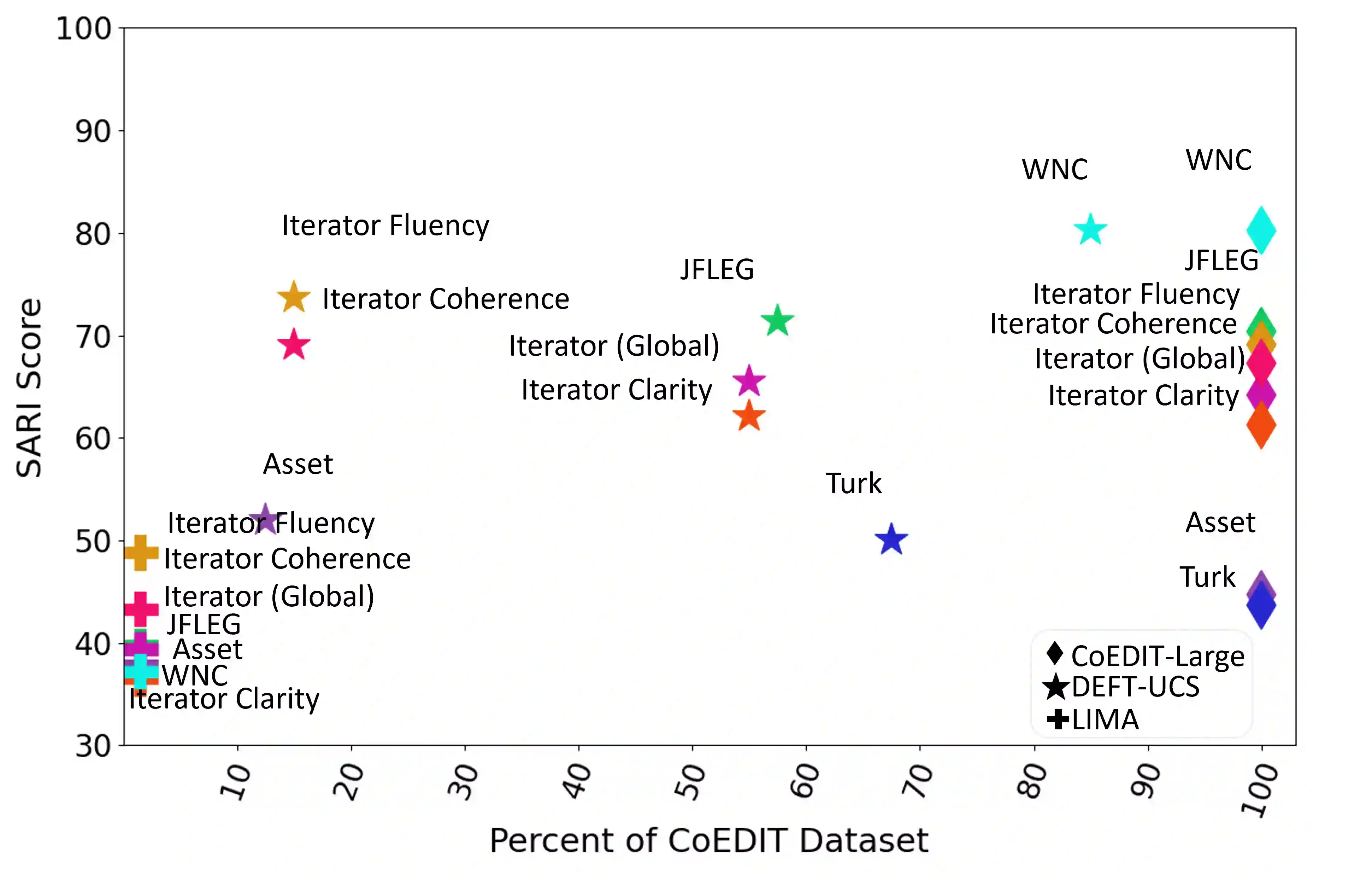
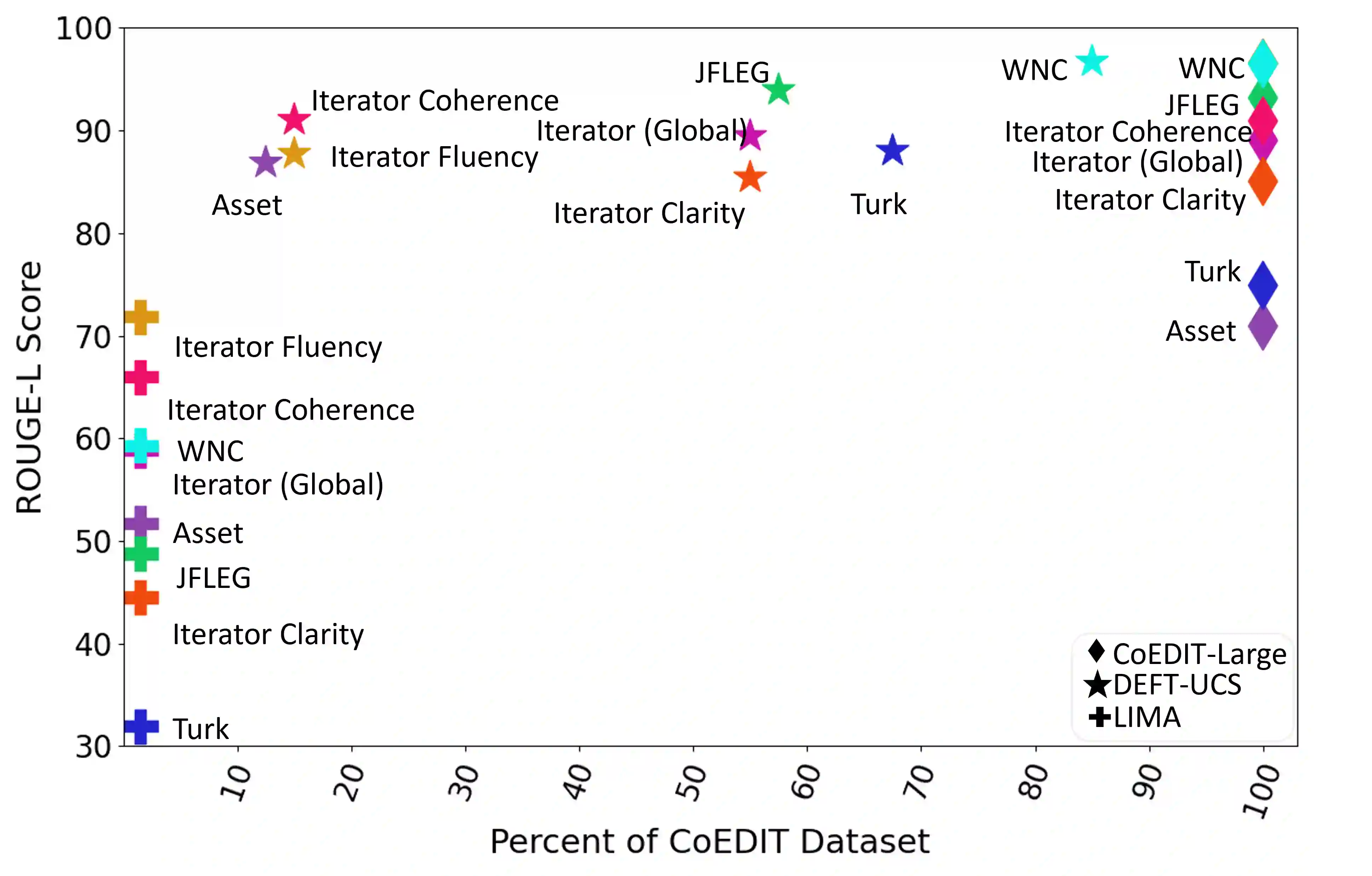
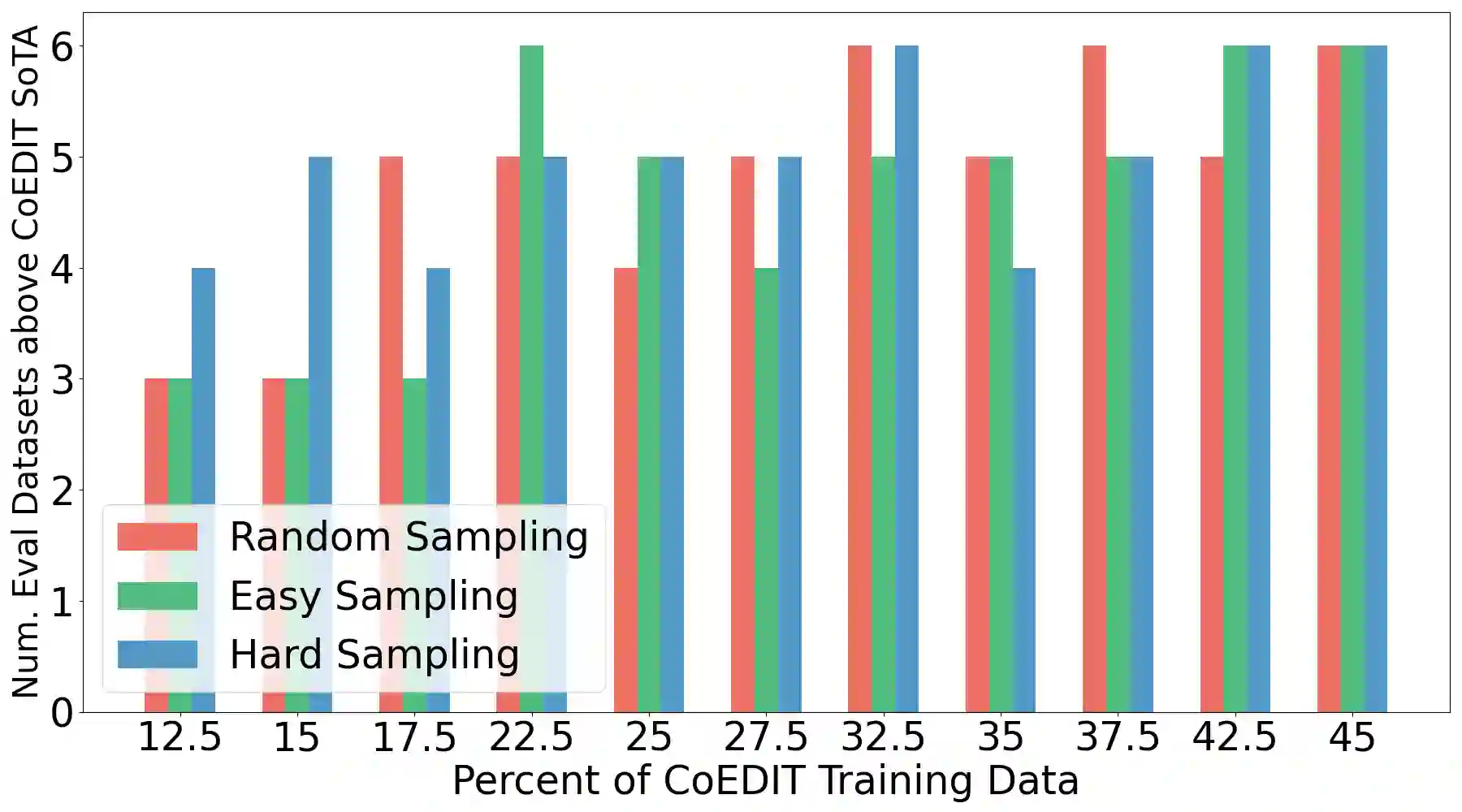
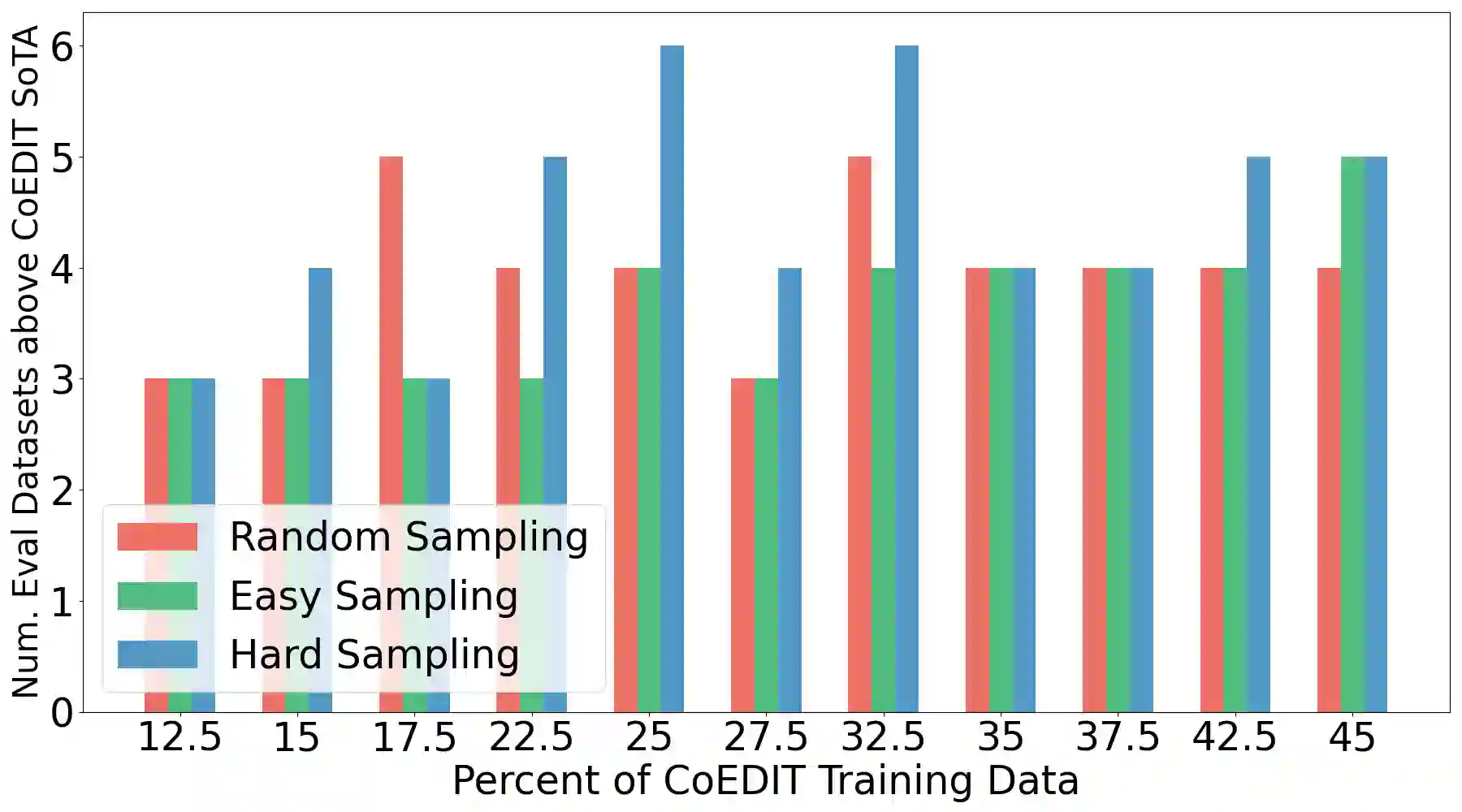
Recent advances have led to the availability of many pre-trained language models (PLMs); however, a question that remains is how much data is truly needed to fine-tune PLMs for downstream tasks? In this work, we introduce DEFT-UCS, a data-efficient fine-tuning framework that leverages unsupervised core-set selection to identify a smaller, representative dataset that reduces the amount of data needed to fine-tune PLMs for downstream tasks. We examine the efficacy of DEFT-UCS in the context of text-editing LMs, and compare to the state-of-the art text-editing model, CoEDIT. Our results demonstrate that DEFT-UCS models are just as accurate as CoEDIT, across eight different datasets consisting of six different editing tasks, while finetuned on 70% less data.
翻译:近期研究进展使得众多预训练语言模型得以广泛应用,但一个关键问题仍然悬而未决:针对下游任务微调预训练语言模型,究竟需要多少数据?本文提出DEFT-UCS框架,一种利用无监督核心集选择从原始数据中筛选出更具代表性的子集,从而显著减少预训练语言模型下游任务微调所需数据量的数据高效微调方法。我们以文本编辑语言模型为应用场景验证DEFT-UCS的有效性,并与当前最先进的文本编辑模型CoEDIT进行对比。实验结果表明,在涵盖六类编辑任务的八个不同数据集上,DEFT-UCS模型在微调数据量减少70%的情况下,其准确率与CoEDIT模型完全相当。