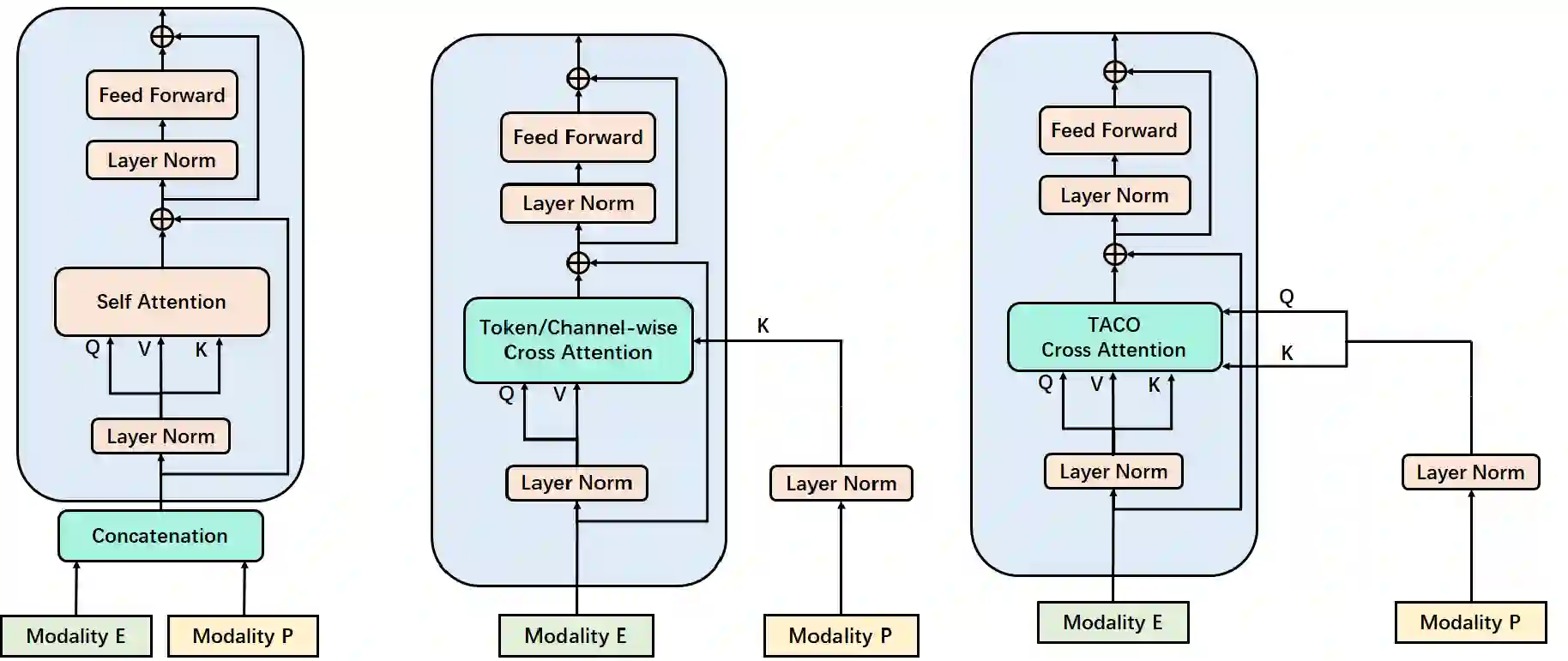
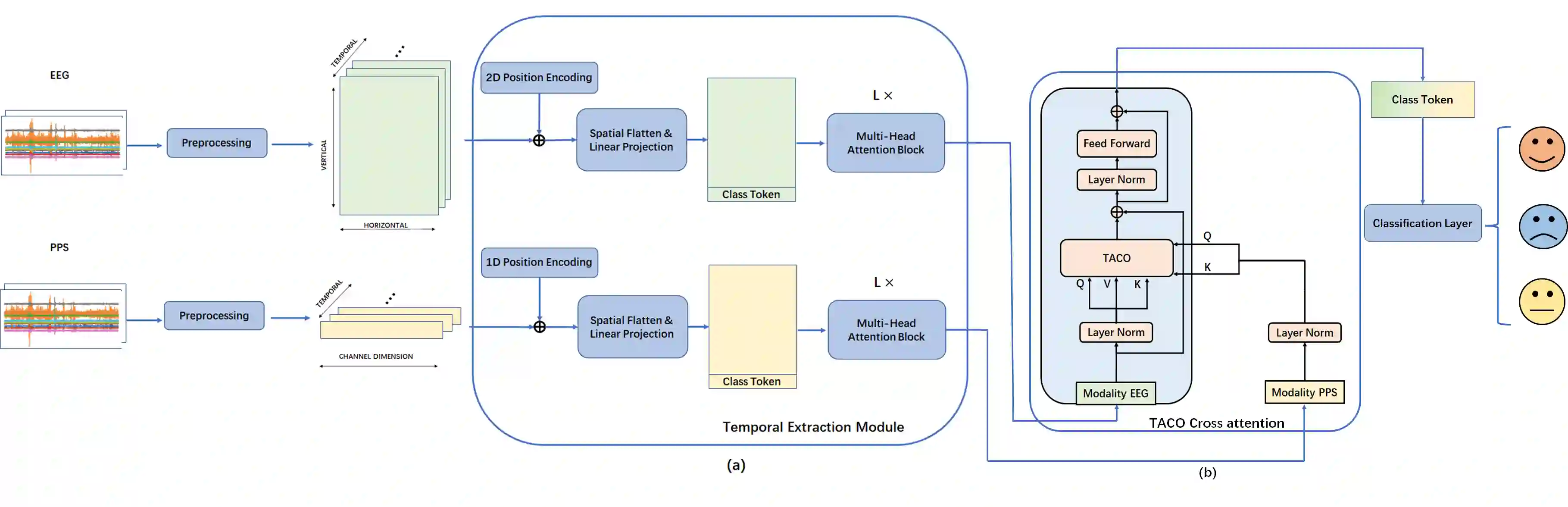
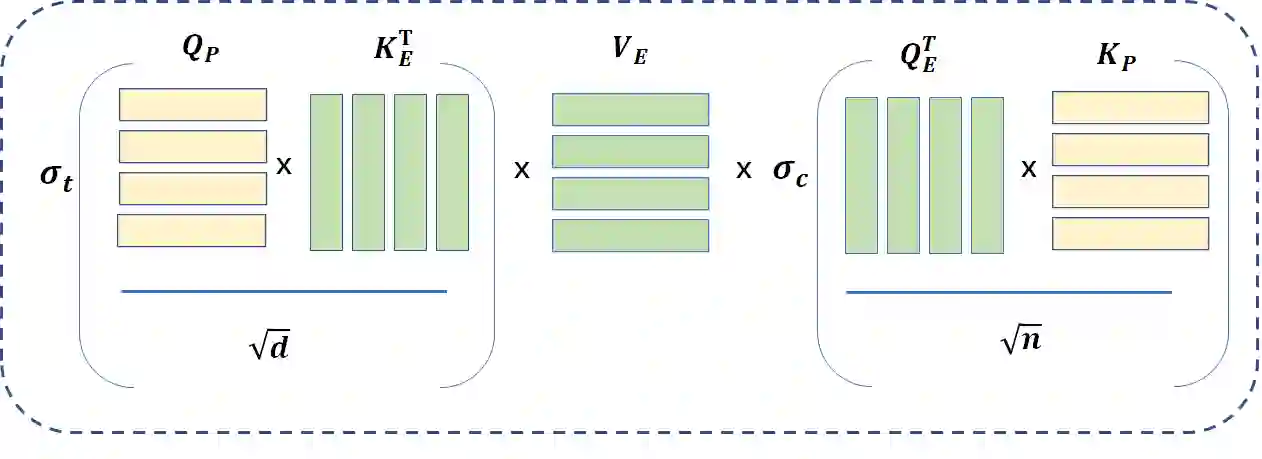
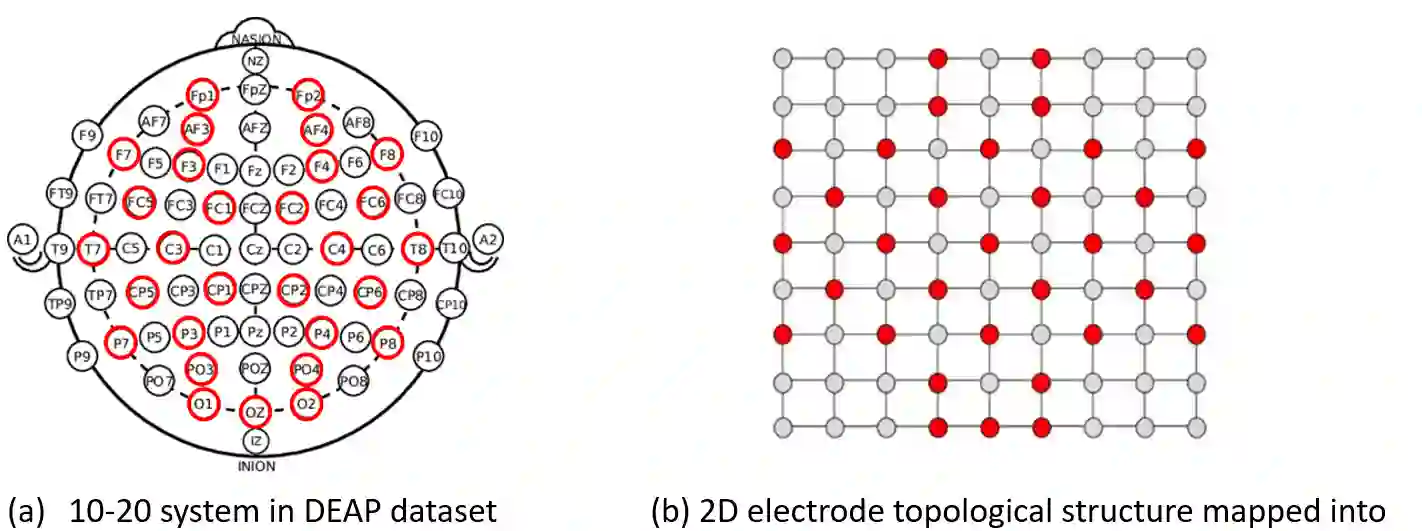
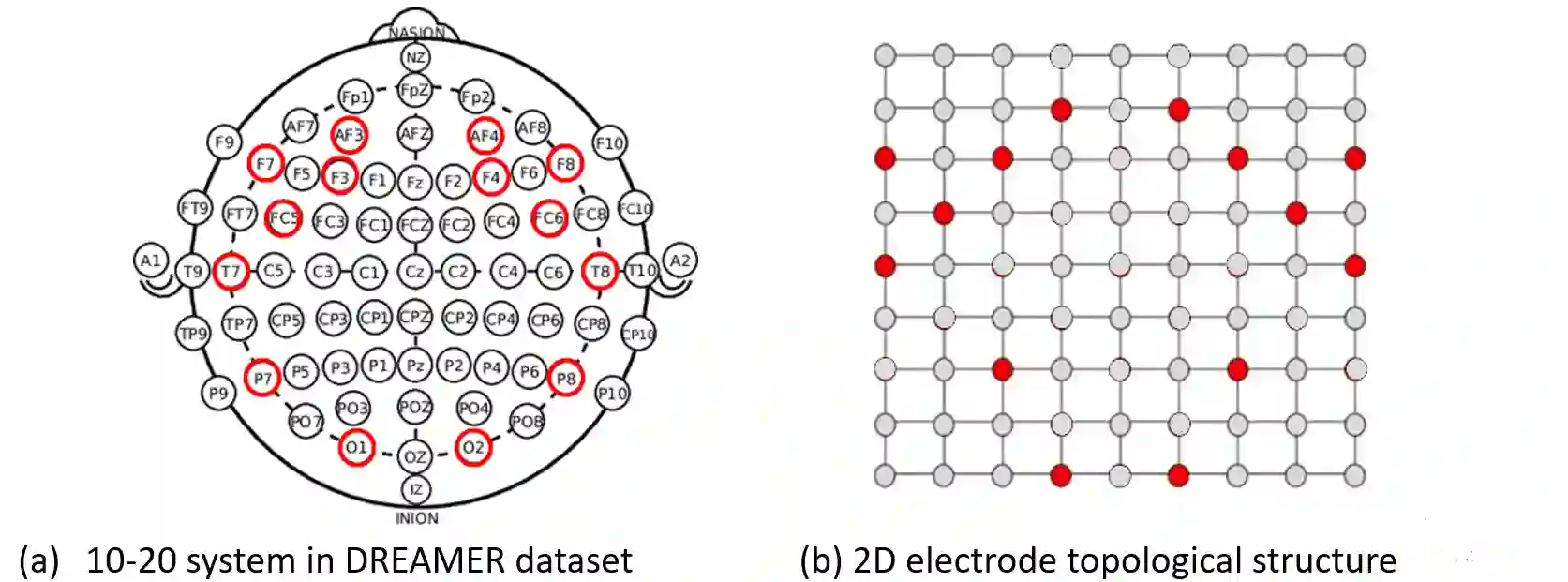
Recently, emotion recognition based on physiological signals has emerged as a field with intensive research. The utilization of multi-modal, multi-channel physiological signals has significantly improved the performance of emotion recognition systems, due to their complementarity. However, effectively integrating emotion-related semantic information from different modalities and capturing inter-modal dependencies remains a challenging issue. Many existing multimodal fusion methods ignore either token-to-token or channel-to-channel correlations of multichannel signals from different modalities, which limits the classification capability of the models to some extent. In this paper, we propose a comprehensive perspective of multimodal fusion that integrates channel-level and token-level cross-modal interactions. Specifically, we introduce a unified cross attention module called Token-chAnnel COmpound (TACO) Cross Attention to perform multimodal fusion, which simultaneously models channel-level and token-level dependencies between modalities. Additionally, we propose a 2D position encoding method to preserve information about the spatial distribution of EEG signal channels, then we use two transformer encoders ahead of the fusion module to capture long-term temporal dependencies from the EEG signal and the peripheral physiological signal, respectively. Subject-independent experiments on emotional dataset DEAP and Dreamer demonstrate that the proposed model achieves state-of-the-art performance.
翻译:近年来,基于生理信号的情感识别已成为一个研究热点。由于多模态、多通道生理信号的互补性,其应用显著提升了情感识别系统的性能。然而,如何有效整合来自不同模态的情感相关语义信息并捕获模态间依赖关系仍是一个具有挑战性的问题。现有许多多模态融合方法忽略了来自不同模态的多通道信号中令牌间或通道间的相关性,这在一定程度上限制了模型的分类能力。本文提出了一种融合通道级与令牌级跨模态交互的多模态融合综合视角。具体而言,我们引入了一种名为令牌-通道复合交叉注意力(TACO)的统一交叉注意力模块用于多模态融合,该模块可同时建模模态间通道级与令牌级依赖关系。此外,我们提出了一种二维位置编码方法以保留脑电图信号通道空间分布信息,并在融合模块前分别使用两个变换器编码器捕获脑电图信号与外周生理信号的长期时间依赖关系。在DEAP与Dreamer情感数据集上的独立受试者实验表明,所提模型达到了最先进性能。