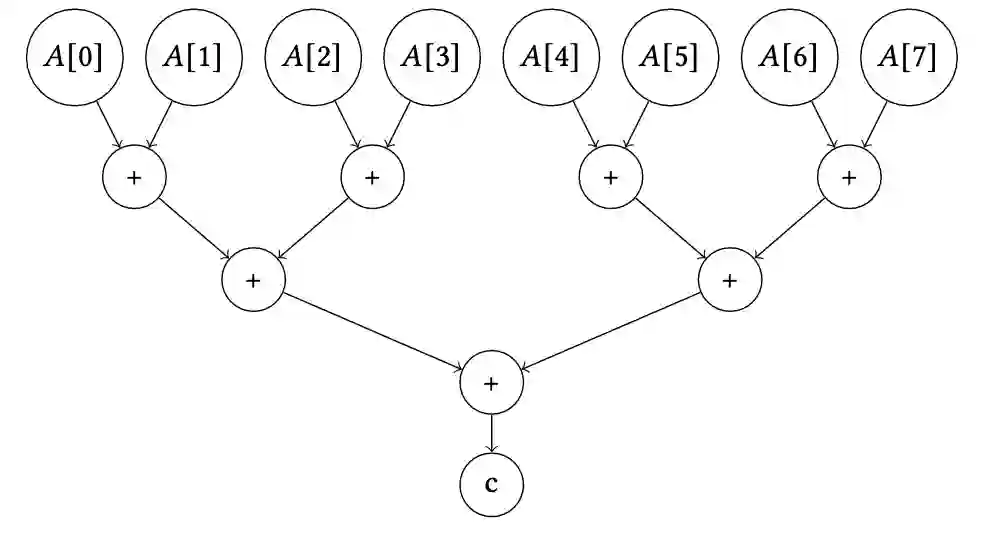
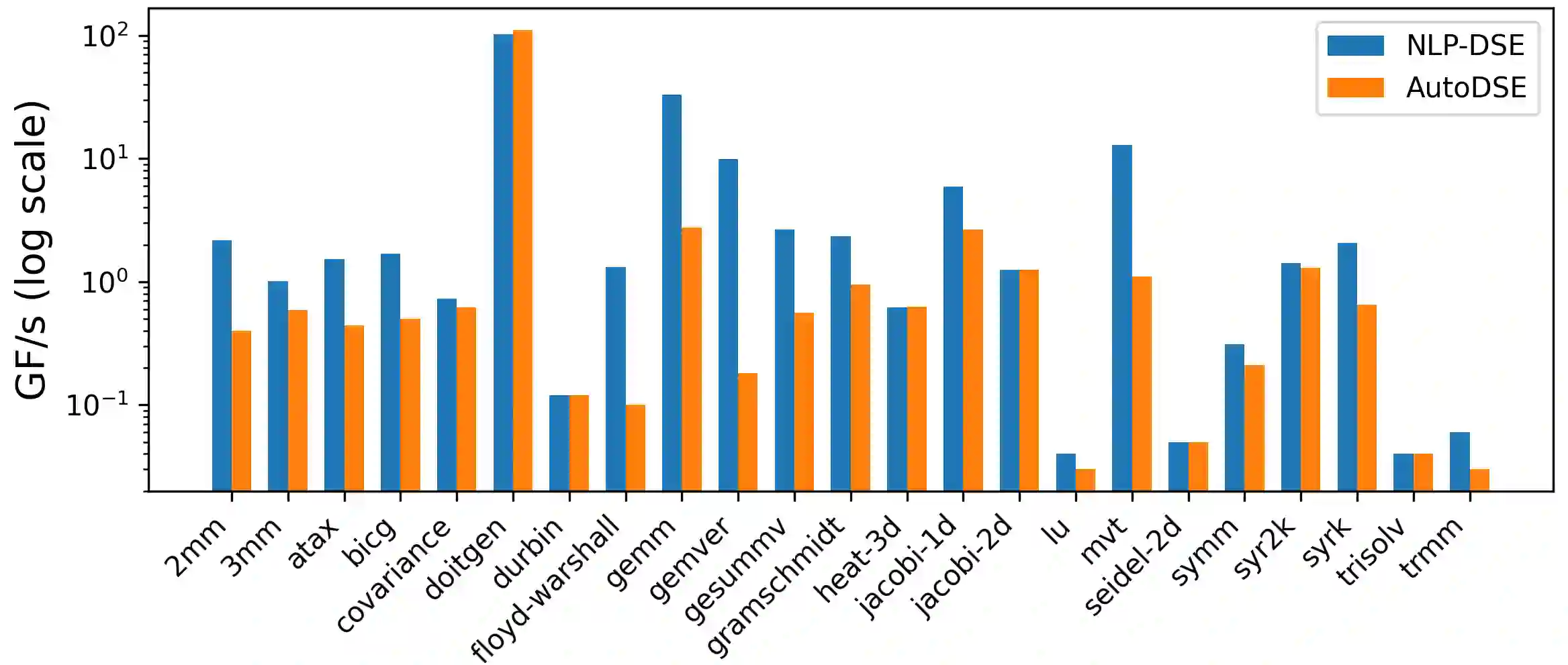
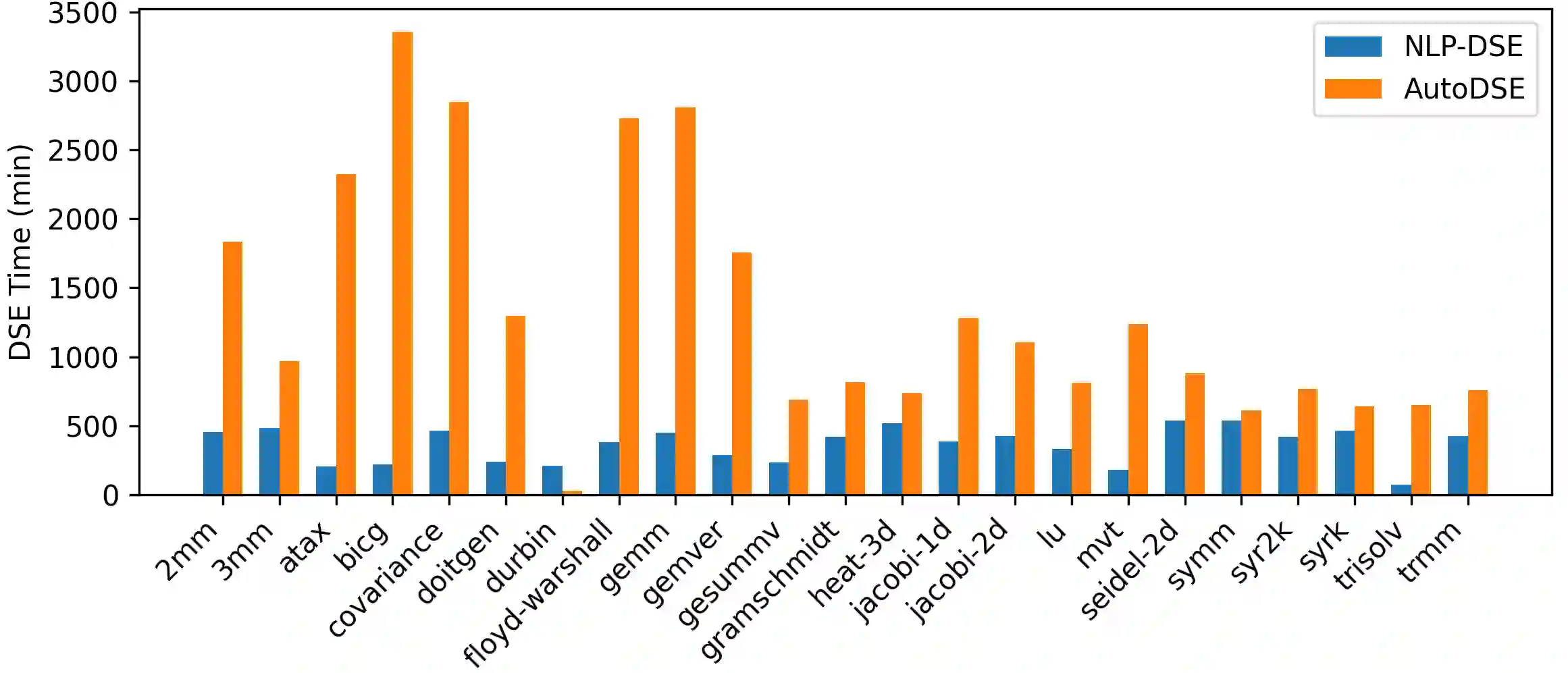
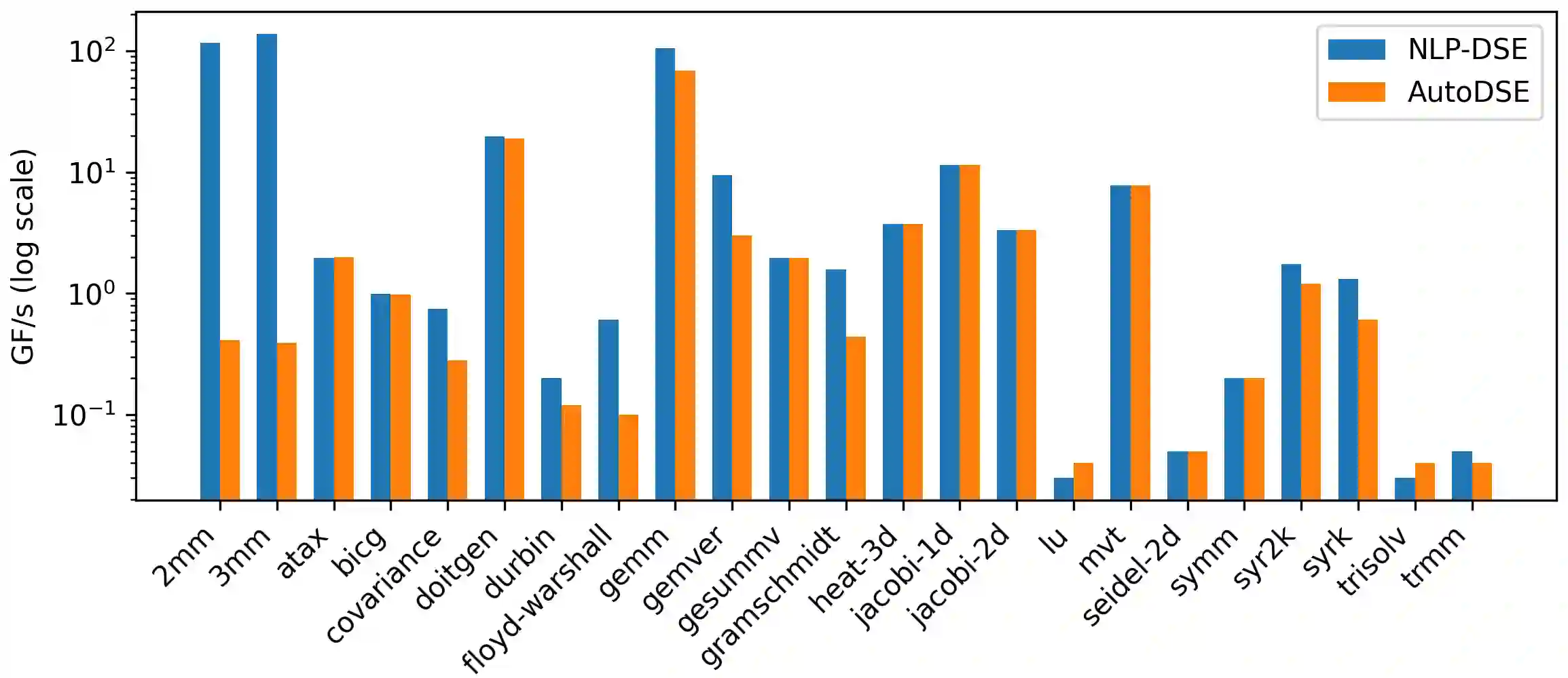
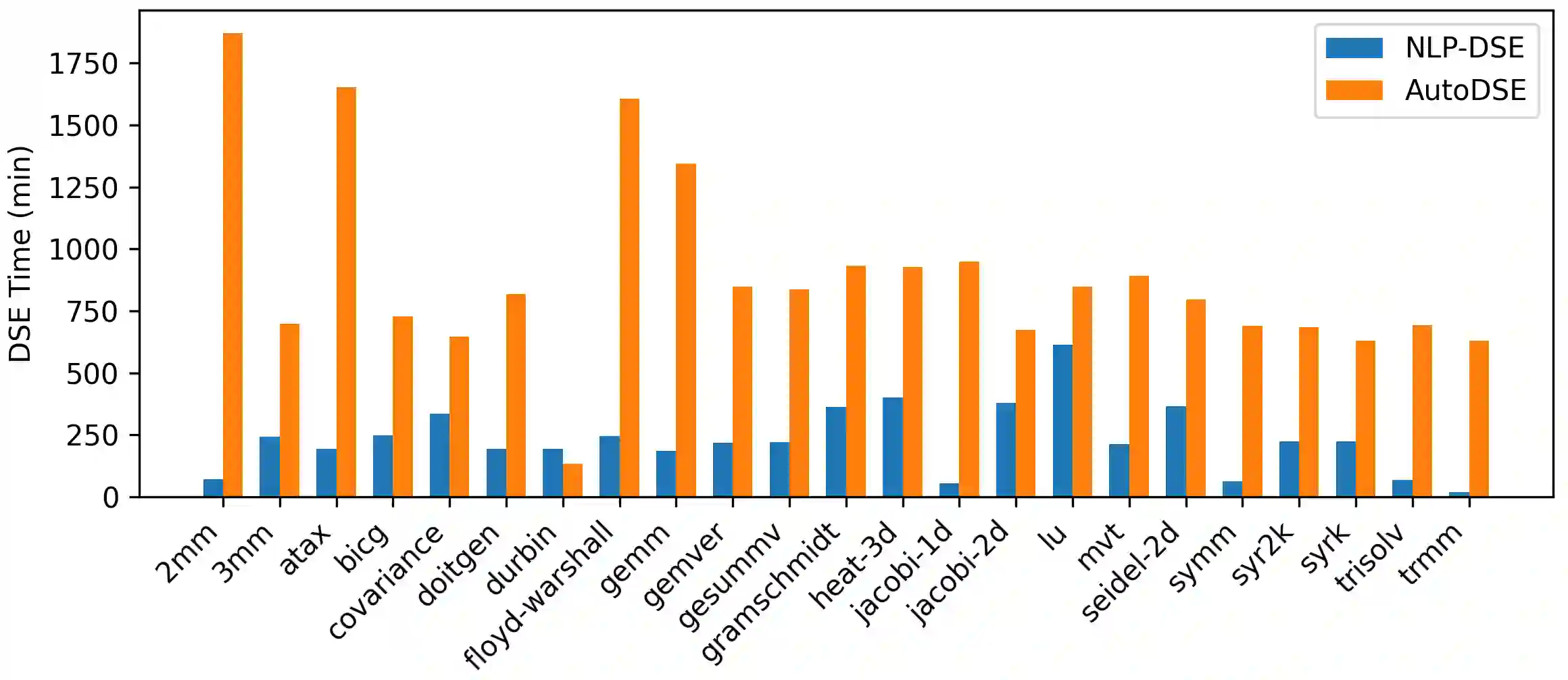
High-Level Synthesis enables the rapid prototyping of hardware accelerators, by combining a high-level description of the functional behavior of a kernel with a set of micro-architecture optimizations as inputs. Such optimizations can be described by inserting pragmas for e.g. pipelining and replication of units, or even higher level transformations for HLS such as automatic data caching using the AMD/Xilinx Merlin compiler. Selecting the best combination of pragmas, even within a restricted set, remains particularly challenging and the typical state-of-practice uses design-space exploration to navigate this space. But due to the highly irregular performance distribution of pragma configurations, typical DSE approaches are either extremely time consuming, or operating on a severely restricted search space. In this work we propose a framework to automatically insert HLS pragmas in regular loop-based programs, supporting pipelining, unit replication (coarse- and fine-grain), and data caching. We develop an analytical performance and resource model as a function of the input program properties and pragmas inserted, using non-linear constraints and objectives. We prove this model provides a lower bound on the actual performance after HLS. We then encode this model as a Non-Linear Program, by making the pragma configuration unknowns of the system, which is computed optimally by solving this NLP. This approach can also be used during DSE, to quickly prune points with a (possibly partial) pragma configuration, driven by lower bounds on achievable latency. We extensively evaluate our end-to-end, fully implemented system, showing it can effectively manipulate spaces of billions of designs in seconds to minutes for the kernels evaluated.
翻译:高层次综合通过将内核功能行为的高级描述与一组微架构优化作为输入相结合,实现了硬件加速器的快速原型设计。此类优化可通过插入编译指示来描述,例如流水线化和单元复制,或更高层次的HLS转换,如使用AMD/Xilinx Merlin编译器进行自动数据缓存。即使在一个受限集合内,选择最佳的编译指示组合仍然极具挑战性,典型的实践状态采用设计空间探索来遍历此空间。但由于编译指示配置的性能分布高度不规则,传统的DSE方法要么极其耗时,要么在严重受限的搜索空间内运行。本文提出一个框架,用于在基于规则循环的程序中自动插入HLS编译指示,支持流水线化、单元复制(粗粒度和细粒度)以及数据缓存。我们开发了一个解析性能和资源模型,该模型作为输入程序属性和所插入编译指示的函数,采用非线性约束和目标。我们证明该模型为HLS后实际性能提供了下界。随后,我们将该模型编码为非线性规划问题,将编译指示配置设为系统未知量,并通过求解此NLP获得最优解。该方法亦可在DSE过程中使用,通过可实现延迟的下界驱动,快速剪枝具有(可能部分)编译指示配置的设计点。我们对端到端完整实现的系统进行了广泛评估,结果表明对于所评估的内核,该系统能在数秒至数分钟内有效处理数十亿量级的设计空间。