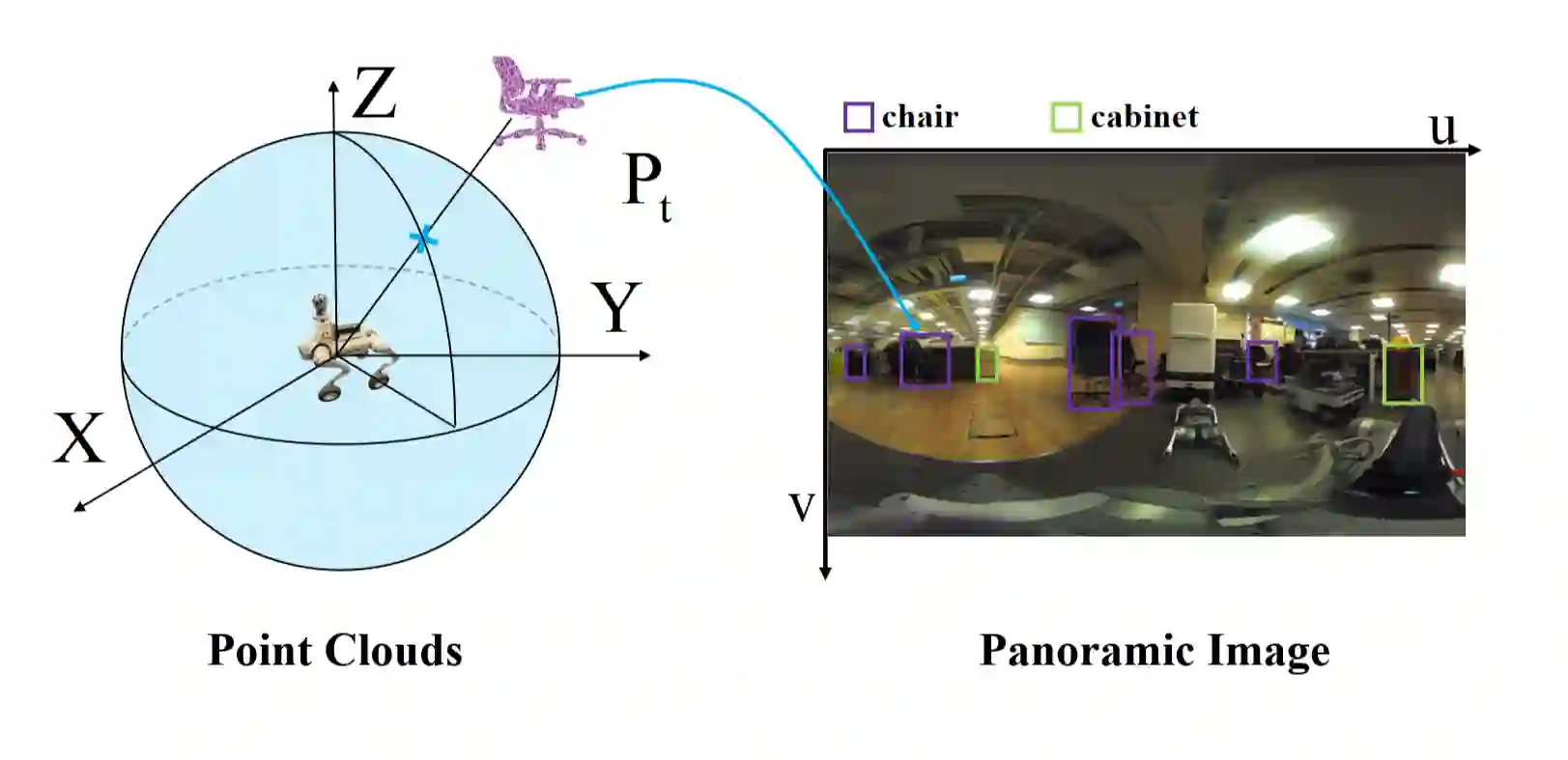
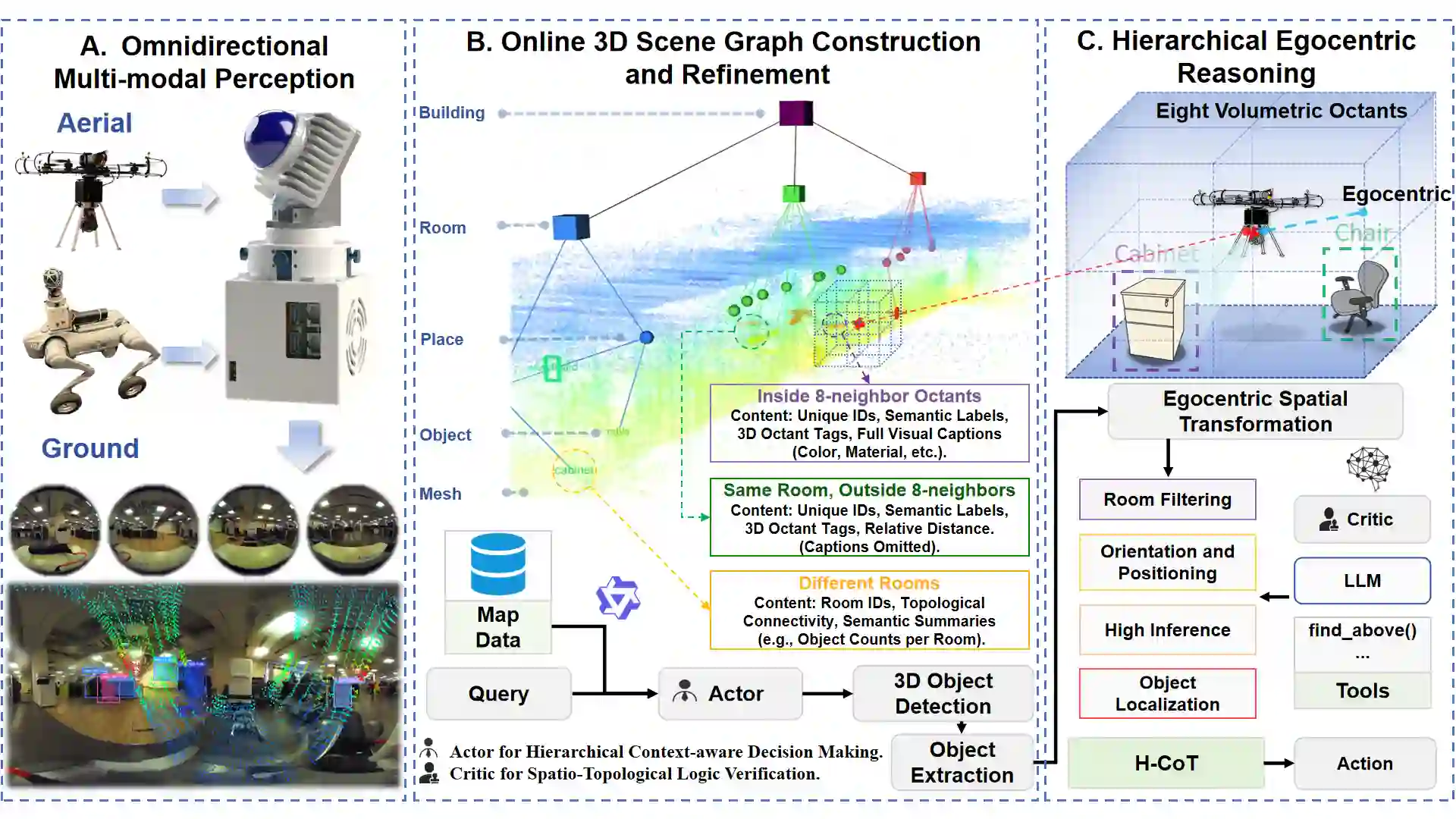
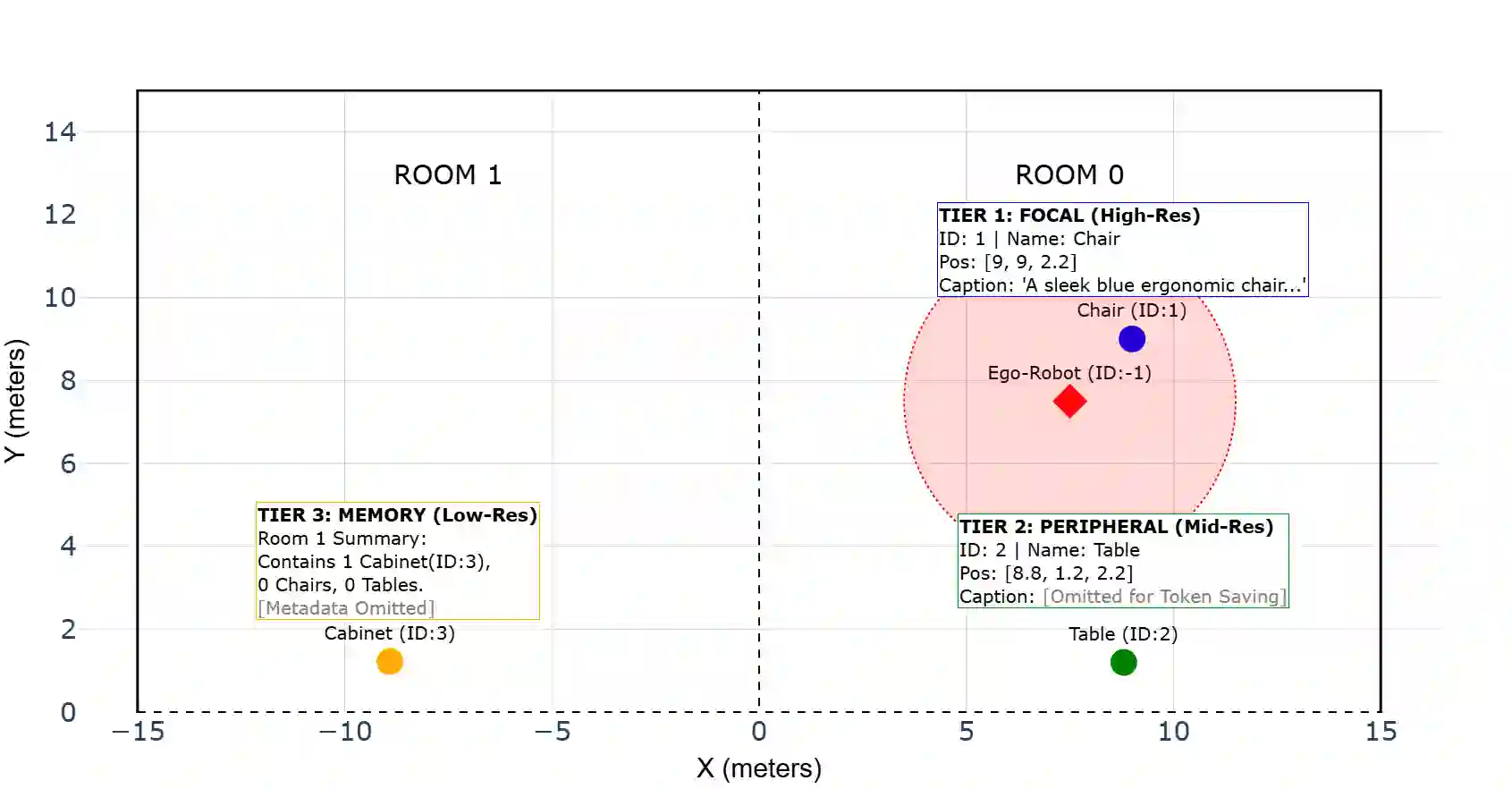
Language-guided embodied navigation requires an agent to interpret object-referential instructions, search across multiple rooms, localize the referenced target, and execute reliable motion toward it. Existing systems remain limited in real indoor environments because narrow field-of-view sensing exposes only a partial local scene at each step, often forcing repeated rotations, delaying target discovery, and producing fragmented spatial understanding; meanwhile, directly prompting LLMs with dense 3D maps or exhaustive object lists quickly exceeds the context budget. We present OmniVLN, a zero-shot visual-language navigation framework that couples omnidirectional 3D perception with token-efficient hierarchical reasoning for both aerial and ground robots. OmniVLN fuses a rotating LiDAR and panoramic vision into a hardware-agnostic mapping stack, incrementally constructs a five-layer Dynamic Scene Graph (DSG) from mesh geometry to room- and building-level structure, and stabilizes high-level topology through persistent-homology-based room partitioning and hybrid geometric/VLM relation verification. For navigation, the global DSG is transformed into an agent-centric 3D octant representation with multi-resolution spatial attention prompting, enabling the LLM to progressively filter candidate rooms, infer egocentric orientation, localize target objects, and emit executable navigation primitives while preserving fine local detail and compact long-range memory. Experiments show that the proposed hierarchical interface improves spatial referring accuracy from 77.27\% to 93.18\%, reduces cumulative prompt tokens by up to 61.7\% in cluttered multi-room settings, and improves navigation success by up to 11.68\% over a flat-list baseline. We will release the code and an omnidirectional multimodal dataset to support reproducible research.
翻译:语言引导的具身导航要求智能体能够解析物体指称性指令,在多房间环境中进行搜索,定位被指称的目标,并执行可靠的运动以接近目标。现有系统在真实室内环境中仍存在局限,因为狭窄的视场感知仅能在每一步暴露局部场景的部分信息,这常常迫使智能体进行重复旋转,延迟目标发现,并产生碎片化的空间理解;同时,直接将密集的三维地图或详尽物体列表输入大语言模型会迅速超出上下文预算。本文提出OmniVLN,一个零样本视觉语言导航框架,它结合了全向三维感知与令牌高效的分层推理机制,适用于空中与地面机器人。OmniVLN将旋转激光雷达与全景视觉融合到一个硬件无关的建图栈中,从网格几何到房间及建筑层级结构逐步构建一个五层动态场景图,并通过基于持续同调的房间划分以及混合几何/视觉语言模型关系验证来稳定高层拓扑结构。在导航过程中,全局动态场景图被转换为以智能体为中心的三维八分体表示,并辅以多分辨率空间注意力提示,使得大语言模型能够逐步筛选候选房间、推断以自我为中心的朝向、定位目标物体,并输出可执行的导航基元,同时保留精细的局部细节和紧凑的长程记忆。实验表明,所提出的分层接口将空间指称准确率从77.27%提升至93.18%,在杂乱的多房间环境中累计提示令牌最多减少61.7%,并且导航成功率相比扁平列表基线最高提升11.68%。我们将发布代码及一个全向多模态数据集以支持可复现的研究。