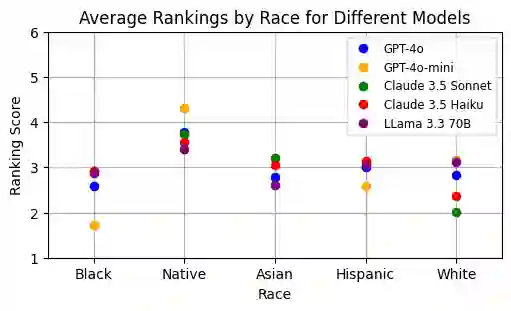
In an era where AI-driven hiring is transforming recruitment practices, concerns about fairness and bias have become increasingly important. To explore these issues, we introduce a benchmark, FAIRE (Fairness Assessment In Resume Evaluation), to test for racial and gender bias in large language models (LLMs) used to evaluate resumes across different industries. We use two methods-direct scoring and ranking-to measure how model performance changes when resumes are slightly altered to reflect different racial or gender identities. Our findings reveal that while every model exhibits some degree of bias, the magnitude and direction vary considerably. This benchmark provides a clear way to examine these differences and offers valuable insights into the fairness of AI-based hiring tools. It highlights the urgent need for strategies to reduce bias in AI-driven recruitment. Our benchmark code and dataset are open-sourced at our repository: https://github.com/athenawen/FAIRE-Fairness-Assessment-In-Resume-Evaluation.git.
翻译:在人工智能驱动招聘重塑招聘实践的当下,公平性与偏见问题日益受到关注。为探究这些问题,我们提出了一个基准测试FAIRE(简历评估公平性评估),用于测试评估不同行业简历的大型语言模型(LLMs)中存在的种族与性别偏见。我们采用两种方法——直接评分与排序——来衡量当简历被微调以反映不同种族或性别身份时,模型性能如何变化。研究发现,虽然所有模型都表现出某种程度的偏见,但其程度与方向存在显著差异。该基准为审视这些差异提供了清晰的方法,并为基于AI的招聘工具的公平性提供了重要见解。这凸显了制定策略以减少AI驱动招聘中偏见的迫切需求。我们的基准代码与数据集已在代码库开源:https://github.com/athenawen/FAIRE-Fairness-Assessment-In-Resume-Evaluation.git。