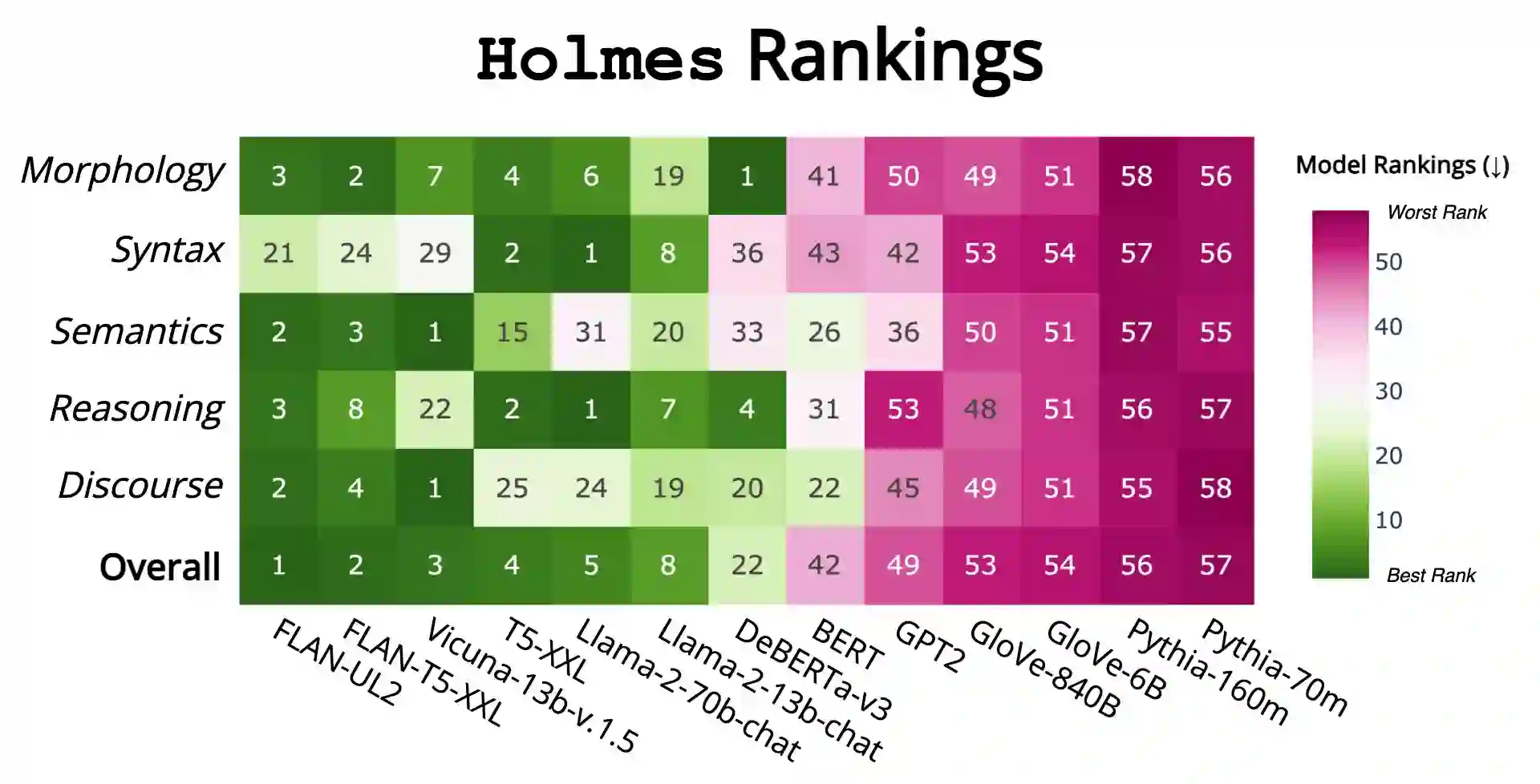
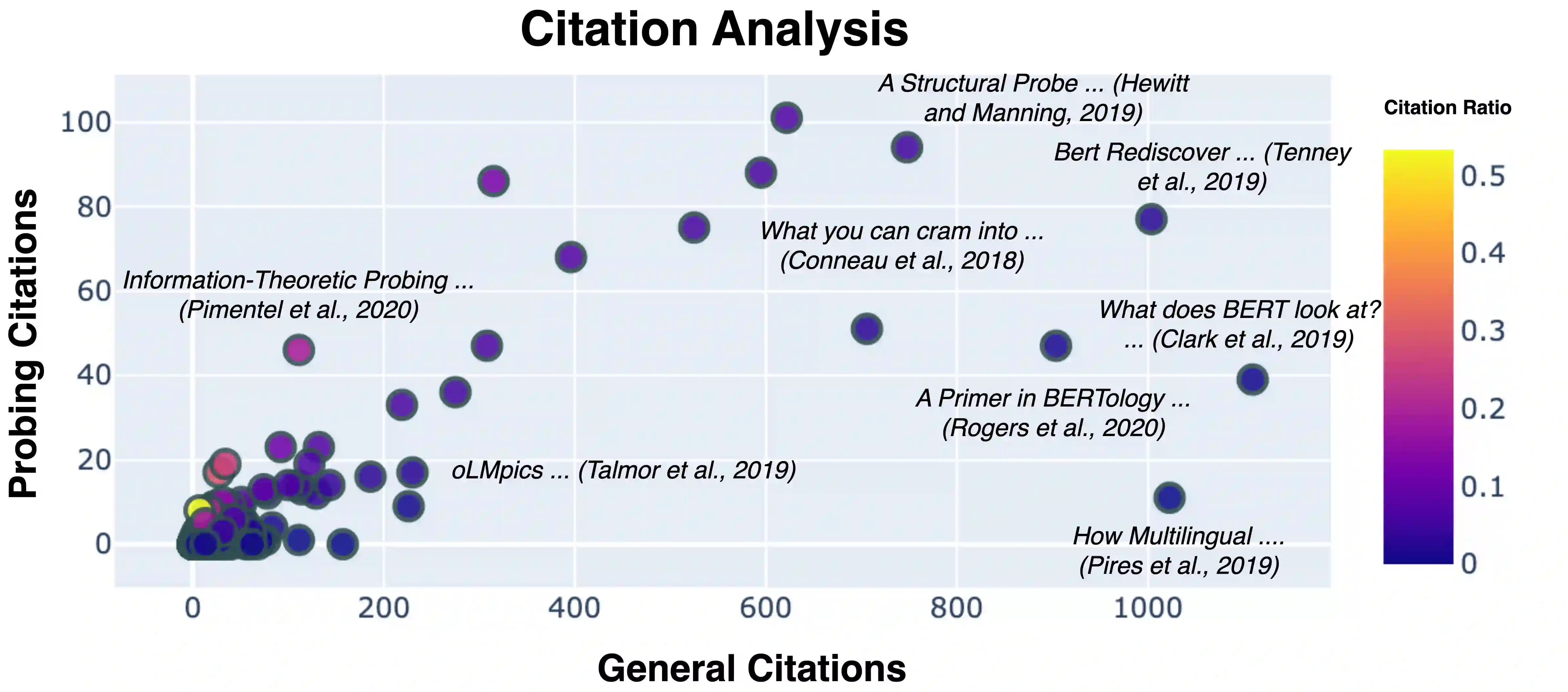
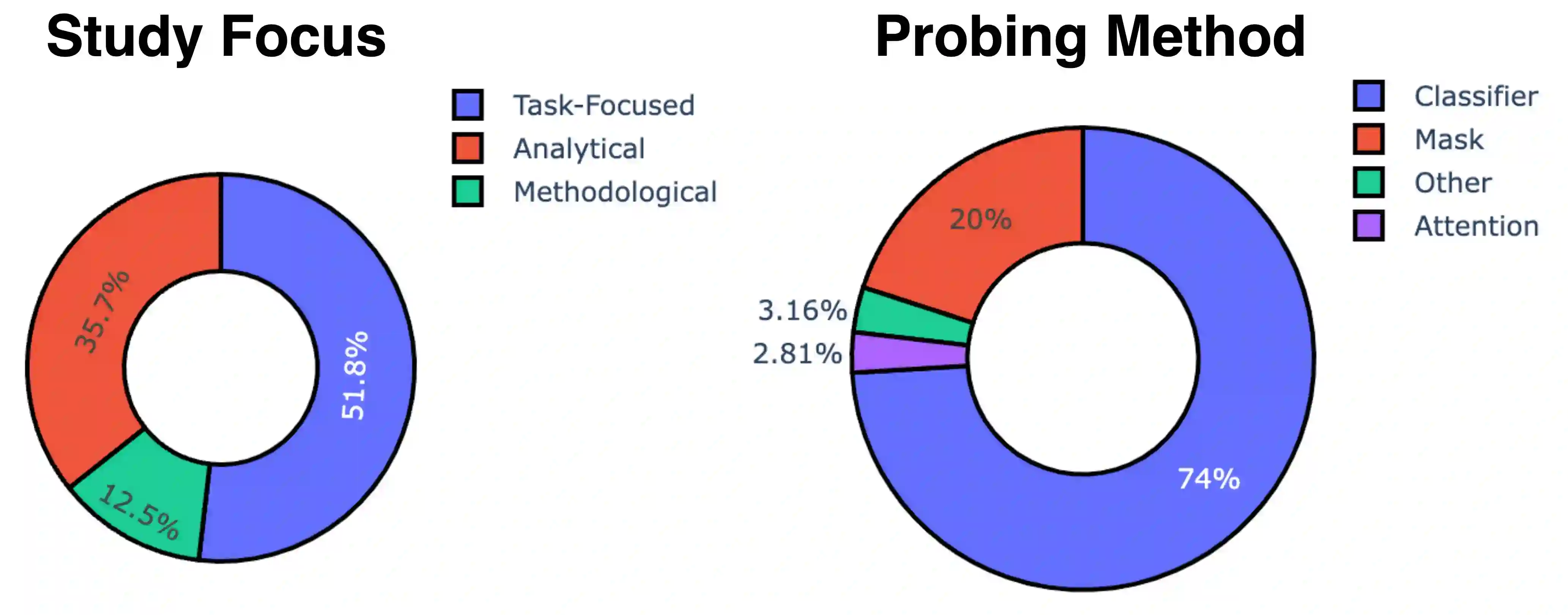
We introduce Holmes, a benchmark to assess the linguistic competence of language models (LMs) - their ability to grasp linguistic phenomena. Unlike prior prompting-based evaluations, Holmes assesses the linguistic competence of LMs via their internal representations using classifier-based probing. In doing so, we disentangle specific phenomena (e.g., part-of-speech of words) from other cognitive abilities, like following textual instructions, and meet recent calls to assess LMs' linguistic competence in isolation. Composing Holmes, we review over 250 probing studies and feature more than 200 datasets to assess syntax, morphology, semantics, reasoning, and discourse phenomena. Analyzing over 50 LMs reveals that, aligned with known trends, their linguistic competence correlates with model size. However, surprisingly, model architecture and instruction tuning also significantly influence performance, particularly in morphology and syntax. Finally, we propose FlashHolmes, a streamlined version of Holmes designed to lower the high computation load while maintaining high-ranking precision.
翻译:我们提出了Holmes,一个用于评估语言模型(LMs)语言能力——即其掌握语言现象的能力的基准测试。与以往基于提示的评估不同,Holmes通过基于分类器的探针法,利用语言模型的内部表征来评估其语言能力。通过这种方式,我们将特定语言现象(如词语的词性)与其他认知能力(如遵循文本指令的能力)区分开来,并响应了近期关于单独评估语言模型语言能力的呼吁。在构建Holmes时,我们回顾了超过250项探针研究,并收录了200多个数据集,以评估句法、形态学、语义、推理和语篇现象。对超过50个语言模型的分析表明,与已知趋势一致,其语言能力与模型规模相关。然而,令人惊讶的是,模型架构和指令微调也对性能有显著影响,尤其是在形态学和句法方面。最后,我们提出了FlashHolmes,这是Holmes的精简版本,旨在降低高计算负载的同时,保持较高的排名精度。