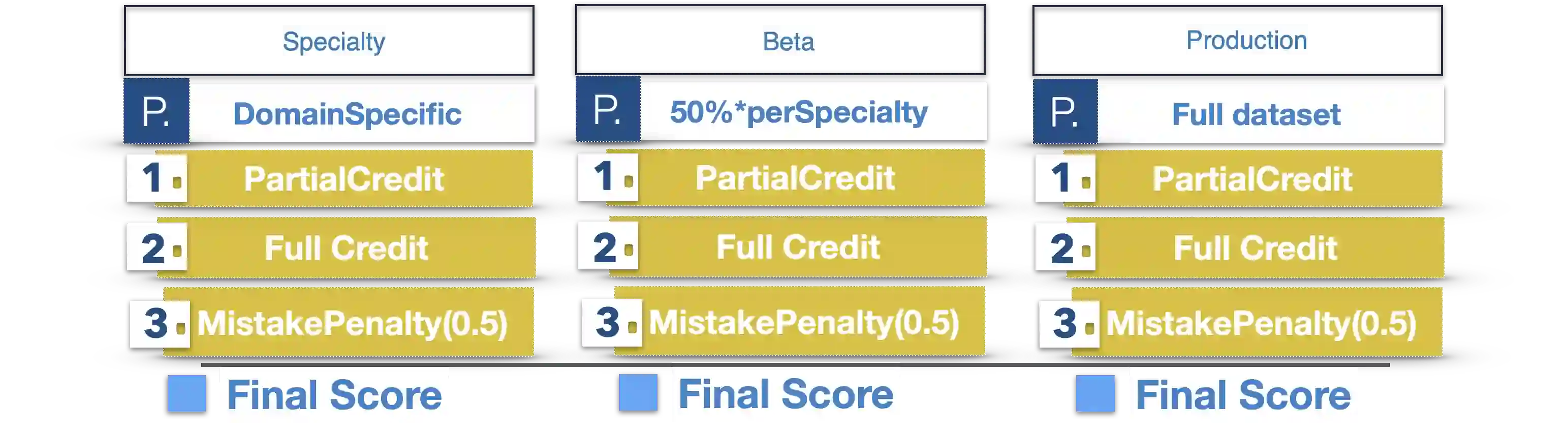
Large Language Models (LLMs) constitute a breakthrough state-of-the-art Artificial Intelligence (AI) technology which is rapidly evolving and promises to aid in medical diagnosis either by assisting doctors or by simulating a doctor's workflow in more advanced and complex implementations. In this technical paper, we outline Cognitive Network Evaluation Toolkit for Medical Domains (COGNET-MD), which constitutes a novel benchmark for LLM evaluation in the medical domain. Specifically, we propose a scoring-framework with increased difficulty to assess the ability of LLMs in interpreting medical text. The proposed framework is accompanied with a database of Multiple Choice Quizzes (MCQs). To ensure alignment with current medical trends and enhance safety, usefulness, and applicability, these MCQs have been constructed in collaboration with several associated medical experts in various medical domains and are characterized by varying degrees of difficulty. The current (first) version of the database includes the medical domains of Psychiatry, Dentistry, Pulmonology, Dermatology and Endocrinology, but it will be continuously extended and expanded to include additional medical domains.
翻译:大型语言模型(LLMs)代表了人工智能(AI)领域的一项突破性前沿技术,该技术正在快速发展,有望通过辅助医生或在更为复杂的高级应用中模拟医生工作流程,助力医学诊断。本技术论文概述了面向医学领域的认知网络评估工具包(COGNET-MD),这是医学领域LLM评估的一个新型基准框架。具体而言,我们提出了一种具有递增难度的评分框架,用于评估LLM在解释医学文本方面的能力。该框架辅以一个多项选择试题(MCQs)数据库。为确保与当前医学趋势保持一致,并增强安全性、实用性和适用性,这些MCQ试题由多个相关医学领域的专家共同构建,具有不同难度等级。当前(第一版)数据库涵盖精神病学、口腔医学、呼吸病学、皮肤病学和内分泌学等医学领域,并将持续扩展以纳入更多医学领域。