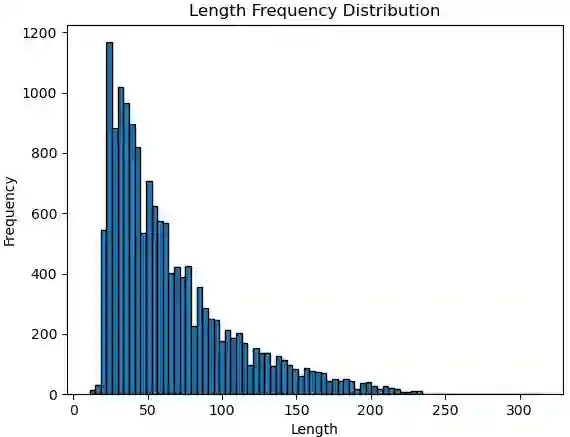
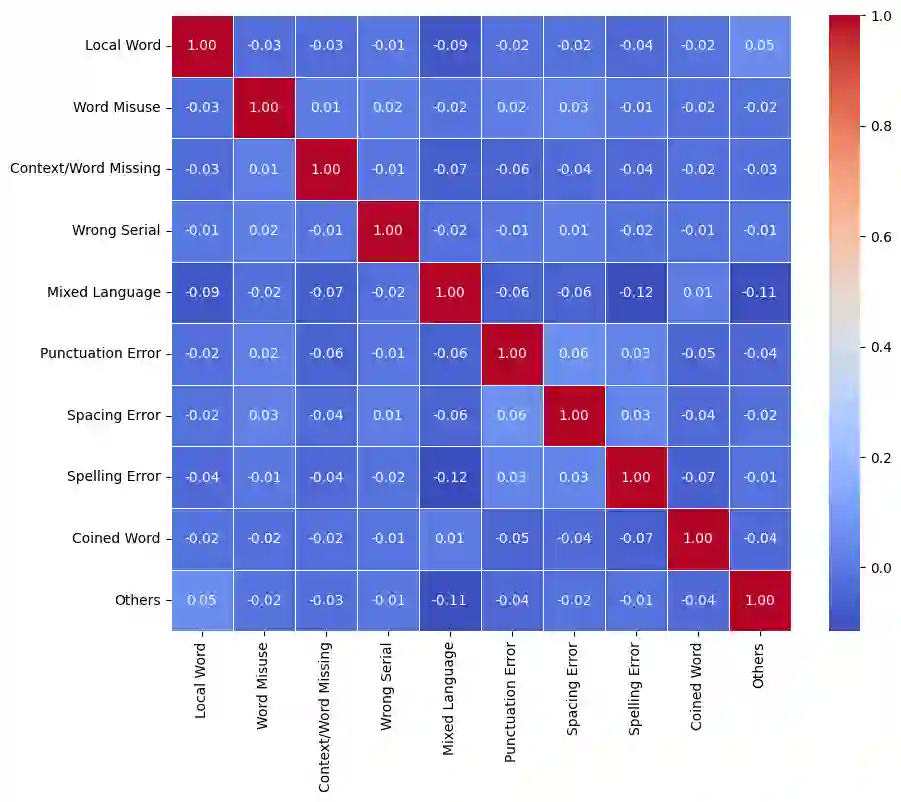
While Bengali is considered a language with limited resources, sentiment analysis has been a subject of extensive research in the literature. Nevertheless, there is a scarcity of exploration into sentiment analysis specifically in the realm of noisy Bengali texts. In this paper, we introduce a dataset (NC-SentNoB) that we annotated manually to identify ten different types of noise found in a pre-existing sentiment analysis dataset comprising of around 15K noisy Bengali texts. At first, given an input noisy text, we identify the noise type, addressing this as a multi-label classification task. Then, we introduce baseline noise reduction methods to alleviate noise prior to conducting sentiment analysis. Finally, we assess the performance of fine-tuned sentiment analysis models with both noisy and noise-reduced texts to make comparisons. The experimental findings indicate that the noise reduction methods utilized are not satisfactory, highlighting the need for more suitable noise reduction methods in future research endeavors. We have made the implementation and dataset presented in this paper publicly available at https://github.com/ktoufiquee/A-Comparative-Analysis-of-Noise-Reduction-Methods-in-Sentiment-Analysis-on-Noisy-Bengali-Texts
翻译:尽管孟加拉语被视为资源匮乏型语言,但情感分析在现有文献中已得到广泛研究。然而,针对嘈杂孟加拉语文本的情感分析探索仍显不足。本文引入了一个人工标注数据集(NC-SentNoB),用以识别包含约1.5万条嘈杂孟加拉语文本的现有情感分析数据集中存在的十种噪声类型。首先,针对给定的输入噪声文本,我们将其作为多标签分类任务进行噪声类型识别;随后,提出基线降噪方法以在情感分析前缓解噪声问题;最后,通过对比微调的情感分析模型在处理含噪文本与降噪文本时的性能表现,评估降噪效果。实验结果表明,现有降噪方法效果未达预期,揭示了未来研究亟需更适配的降噪方案。本文采用的实现方法及数据集已公开于https://github.com/ktoufiquee/A-Comparative-Analysis-of-Noise-Reduction-Methods-in-Sentiment-Analysis-on-Noisy-Bengali-Texts。