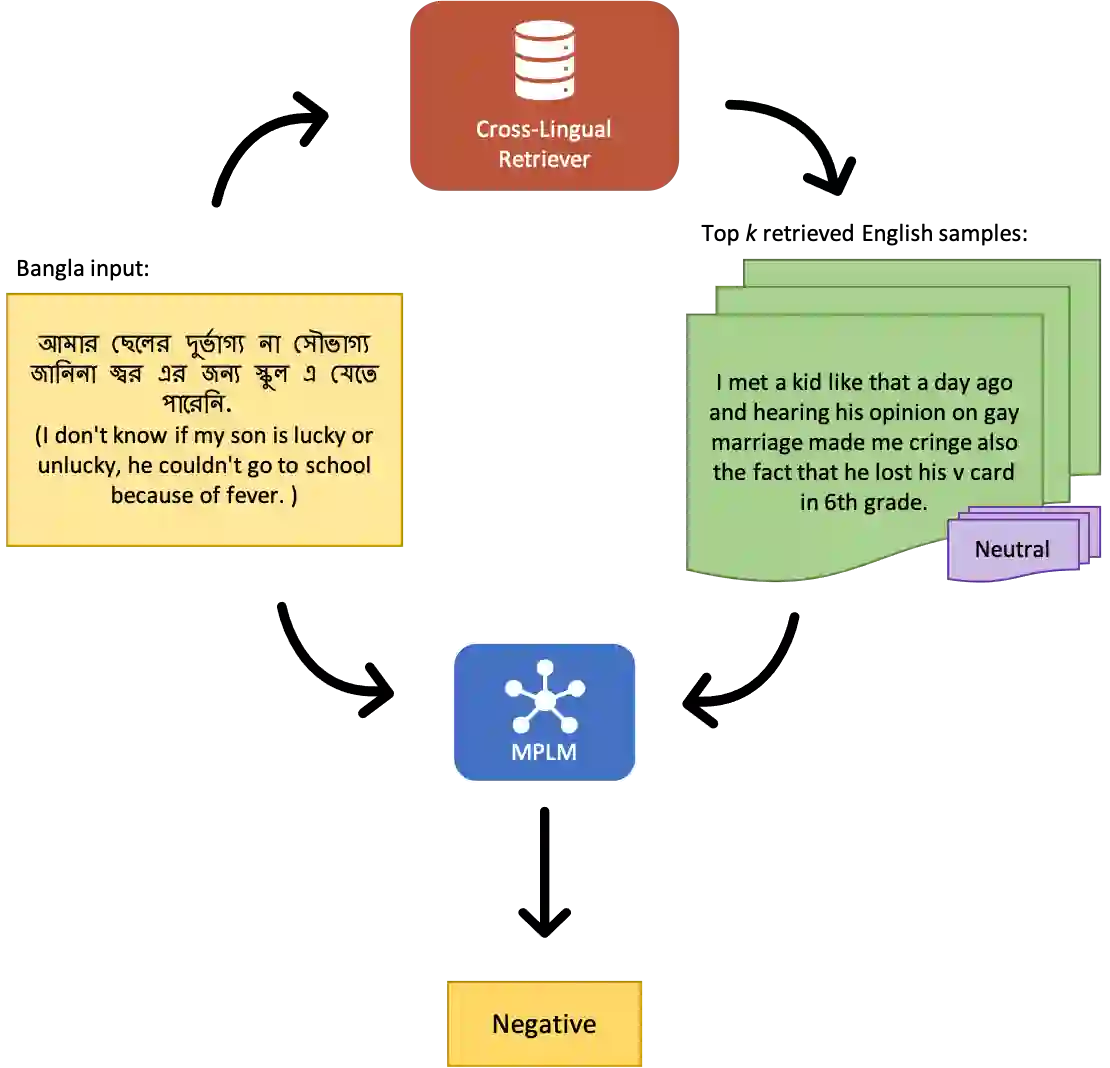
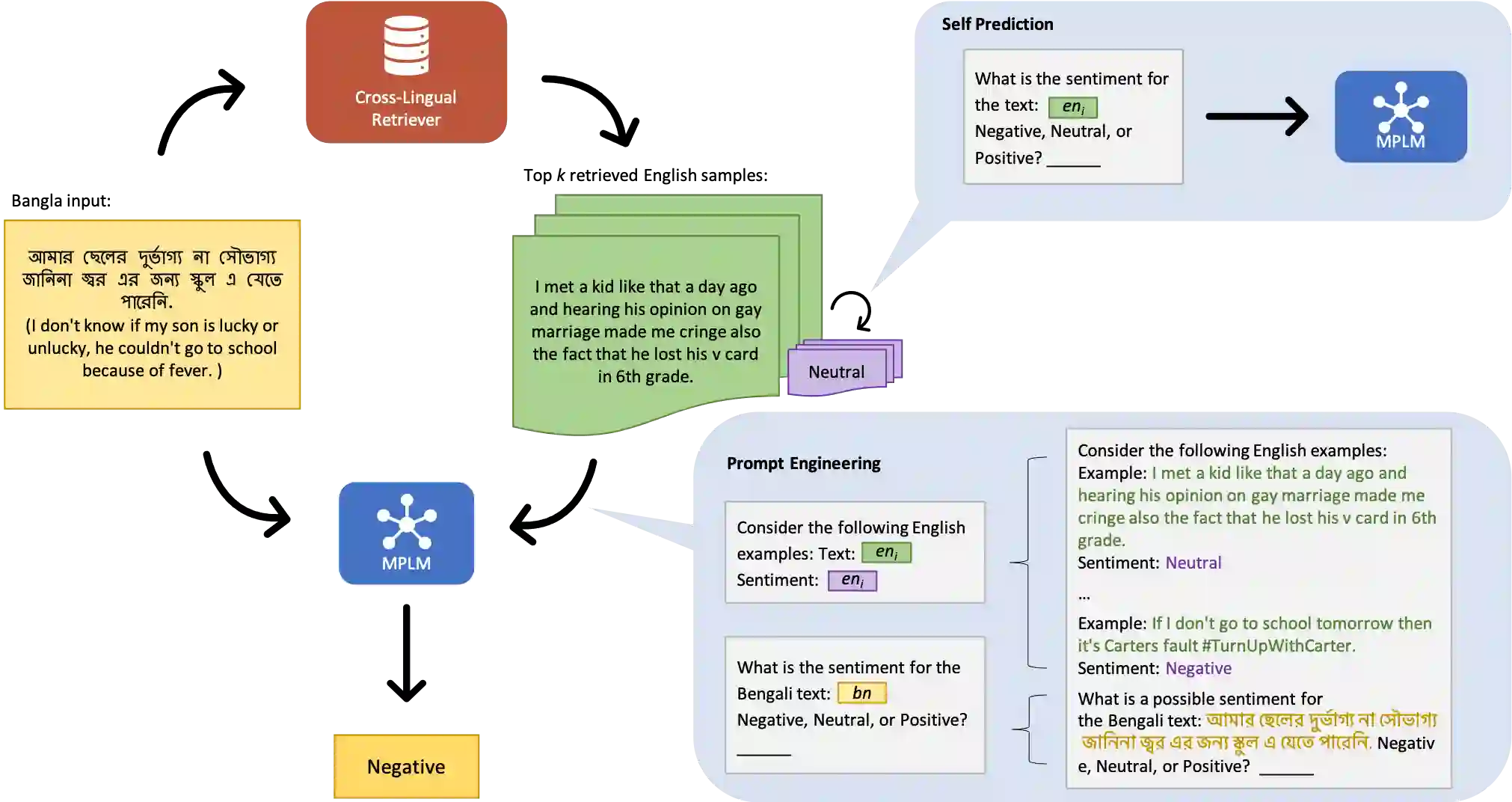
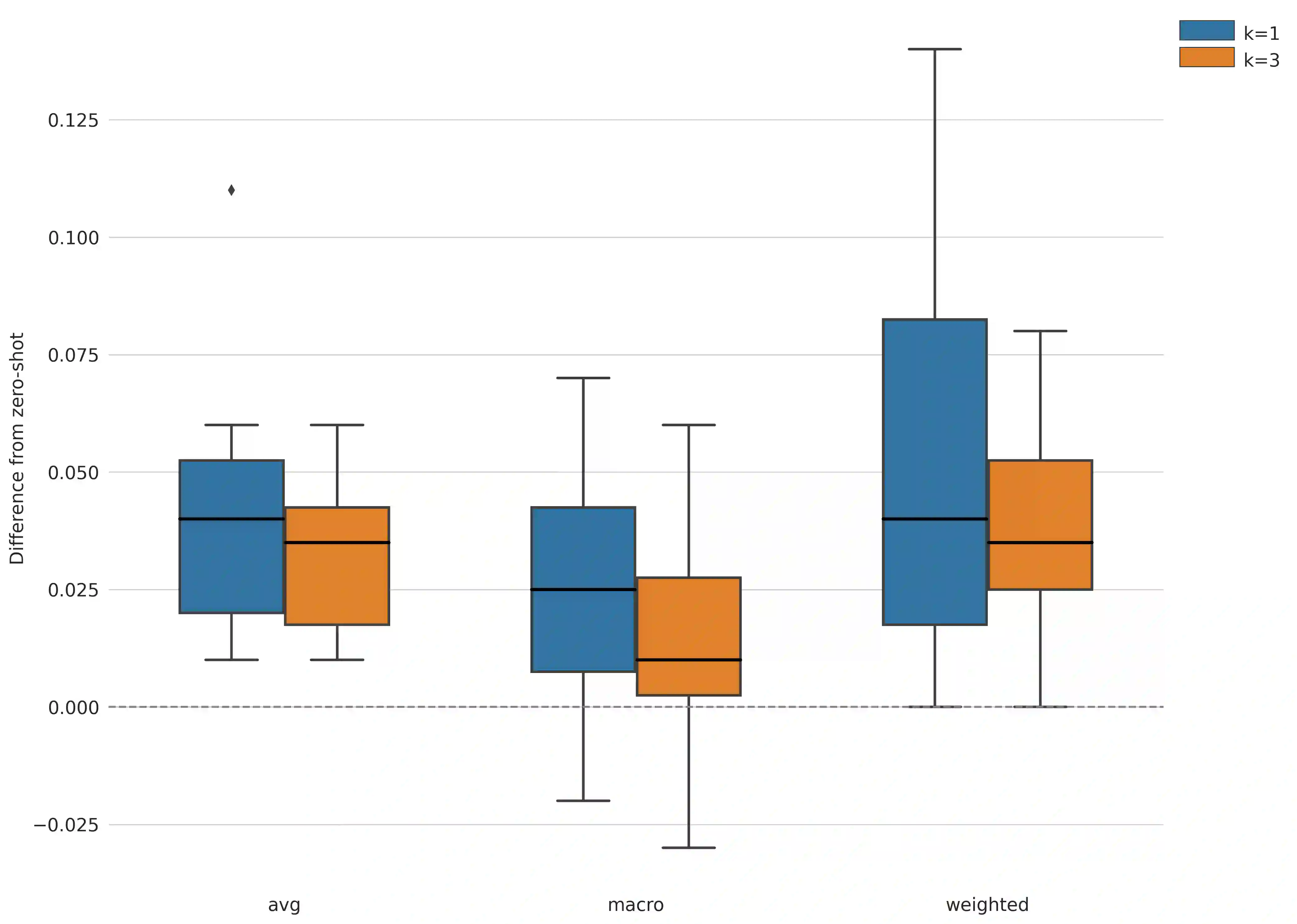
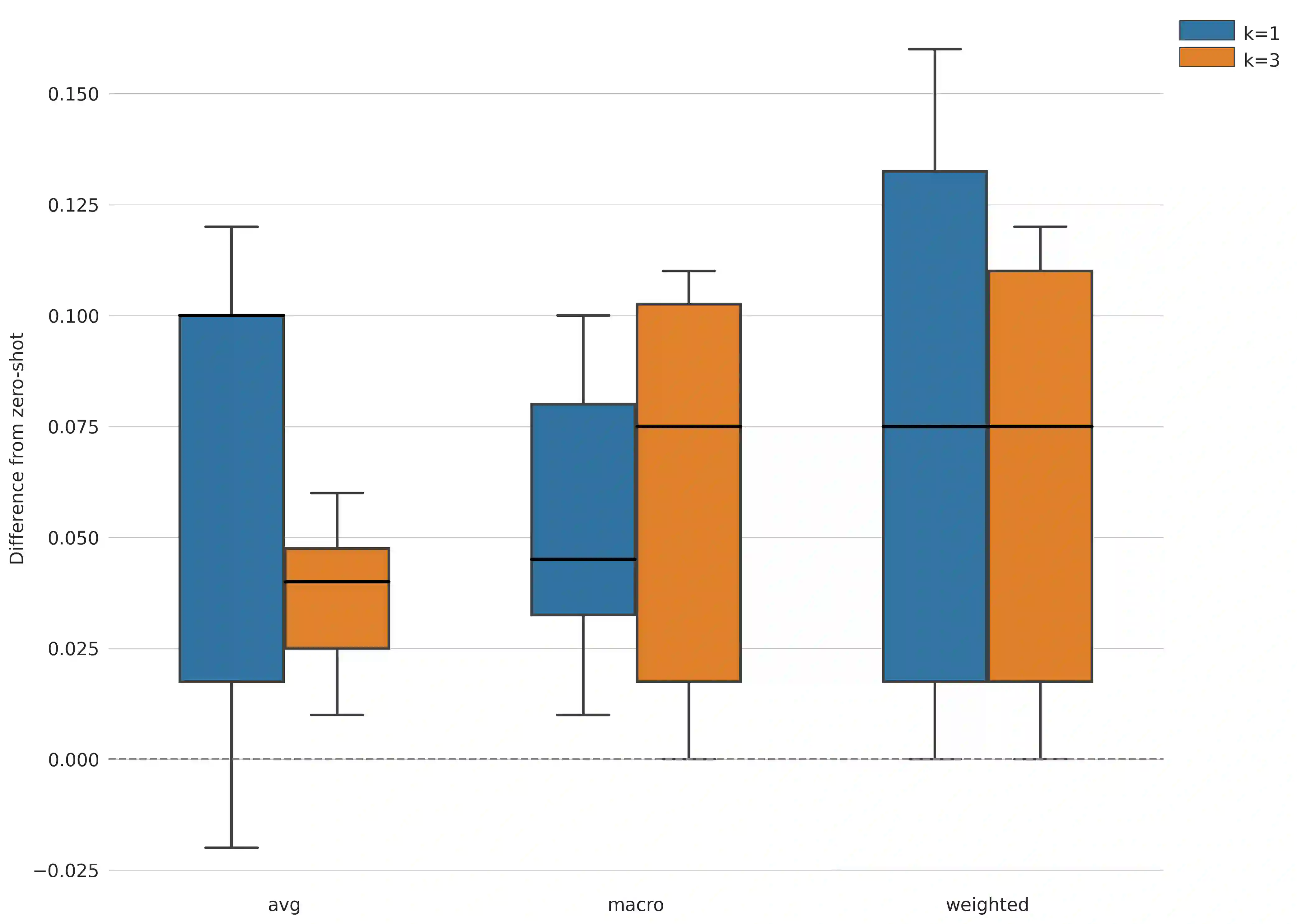
The promise of Large Language Models (LLMs) in Natural Language Processing has often been overshadowed by their limited performance in low-resource languages such as Bangla. To address this, our paper presents a pioneering approach that utilizes cross-lingual retrieval augmented in-context learning. By strategically sourcing semantically similar prompts from high-resource language, we enable multilingual pretrained language models (MPLMs), especially the generative model BLOOMZ, to successfully boost performance on Bangla tasks. Our extensive evaluation highlights that the cross-lingual retrieval augmented prompts bring steady improvements to MPLMs over the zero-shot performance.
翻译:大语言模型(LLMs)在自然语言处理领域的潜力,常因其在孟加拉语等低资源语言中的有限表现而黯然失色。为此,本文提出了一种开创性方法,利用跨语言检索增强的上下文学习。通过从高资源语言中策略性地获取语义相似的提示,我们使多语言预训练语言模型(MPLMs)——尤其是生成式模型BLOOMZ——在孟加拉语任务中成功提升了性能。我们的广泛评估表明,跨语言检索增强的提示为MPLMs带来了相较于零样本性能的稳步提升。