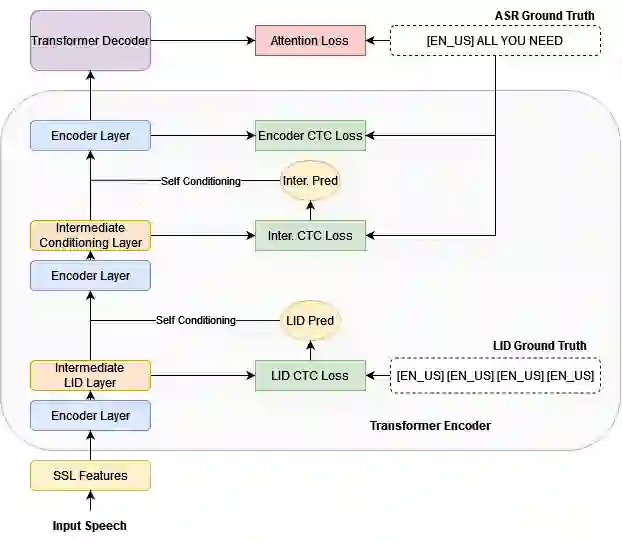
Multilingual Automatic Speech Recognition (ASR) models have extended the usability of speech technologies to a wide variety of languages. With how many languages these models have to handle, however, a key to understanding their imbalanced performance across different languages is to examine if the model actually knows which language it should transcribe. In this paper, we introduce our work on improving performance on FLEURS, a 102-language open ASR benchmark, by conditioning the entire model on language identity (LID). We investigate techniques inspired from recent Connectionist Temporal Classification (CTC) studies to help the model handle the large number of languages, conditioning on the LID predictions of auxiliary tasks. Our experimental results demonstrate the effectiveness of our technique over standard CTC/Attention-based hybrid mod- els. Furthermore, our state-of-the-art systems using self-supervised models with the Conformer architecture improve over the results of prior work on FLEURS by a relative 28.4% CER. Trained models are reproducible recipes are available at https://github.com/ espnet/espnet/tree/master/egs2/fleurs/asr1.
翻译:多语言自动语音识别(ASR)模型已将语音技术的可用性扩展至多种语言。然而,鉴于这些模型需处理的语言数量众多,理解其在不同语言上性能不平衡的关键在于考察模型是否真正知晓其应转录的语言。本文介绍了我们提升FLEURS(一个102种语言的开放ASR基准)性能的工作,方法是通过语言身份(LID)对整个模型进行条件化。我们借鉴了近期连接主义时序分类(CTC)研究中的技术,利用辅助任务的LID预测来帮助模型处理大量语言。实验结果表明,我们的技术在标准CTC/注意力混合模型基础上具有有效性。此外,我们采用基于Conformer架构的自监督模型构建的最优系统,在FLEURS上的性能相较于先前工作相对提升了28.4%的字符错误率(CER)。训练模型可复现,相关代码与配置参见 https://github.com/espnet/espnet/tree/master/egs2/fleurs/asr1。