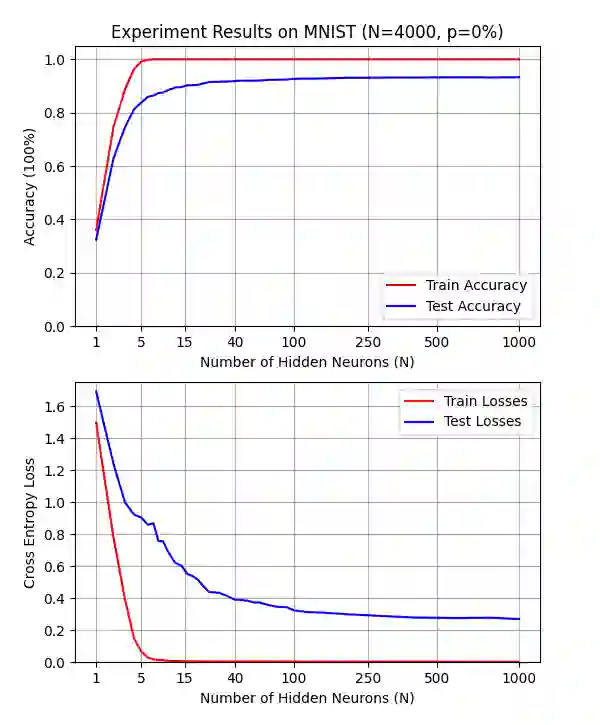
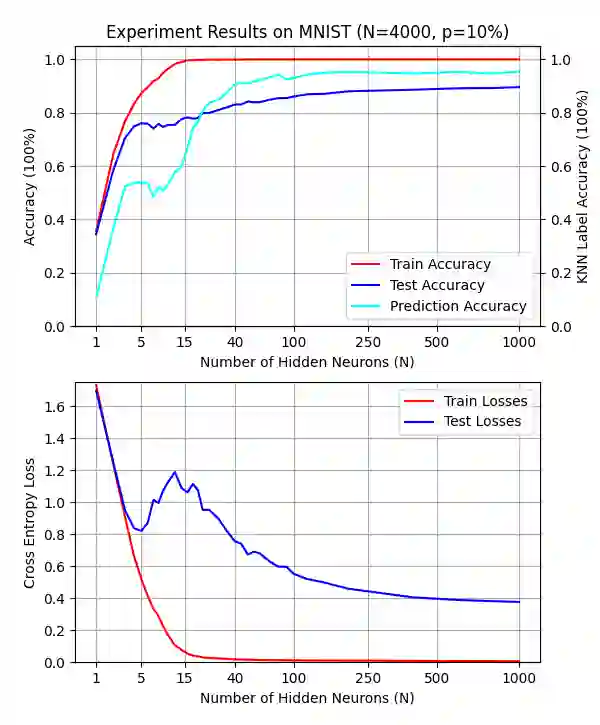
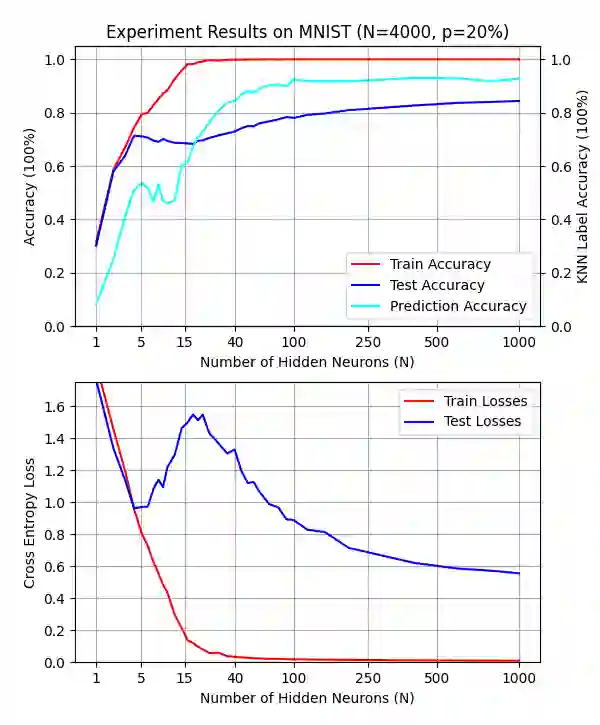
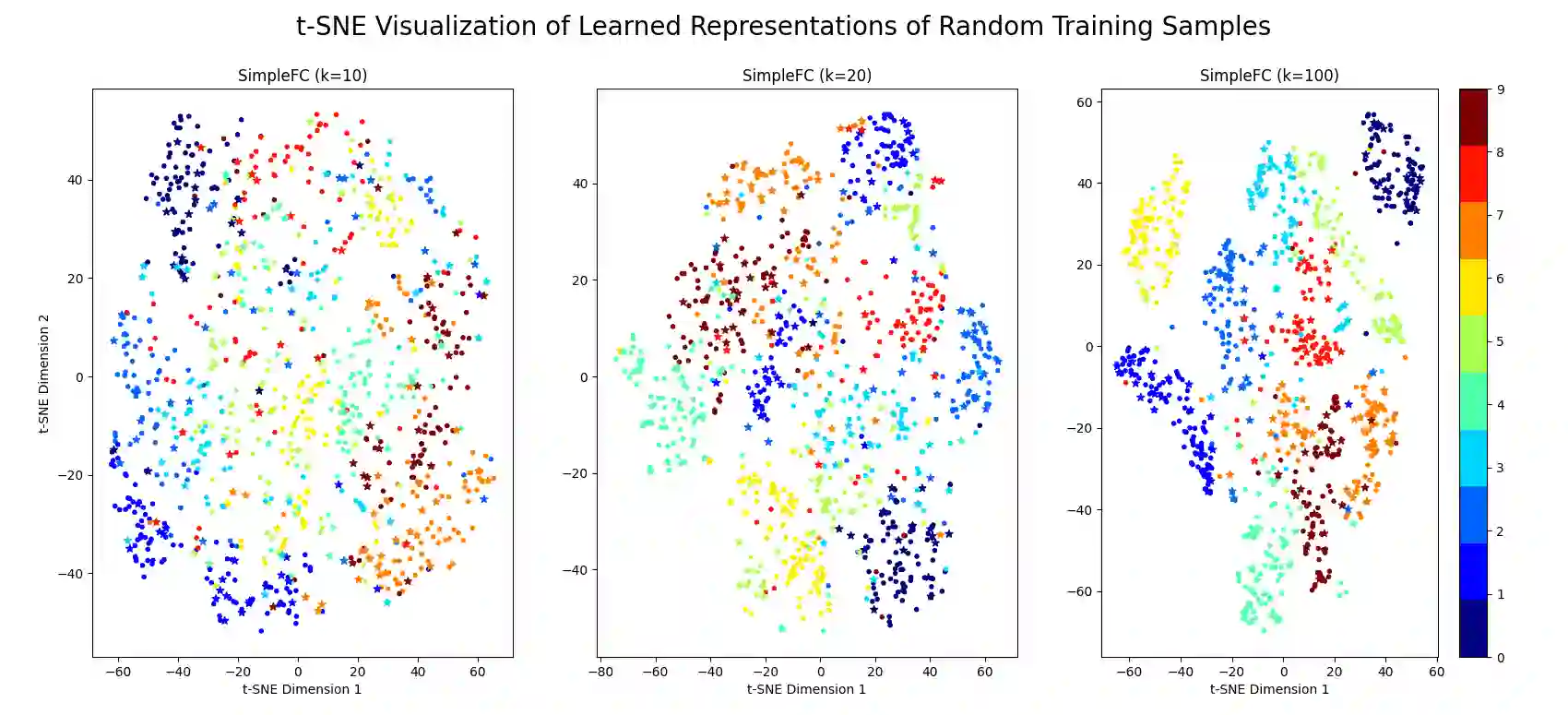
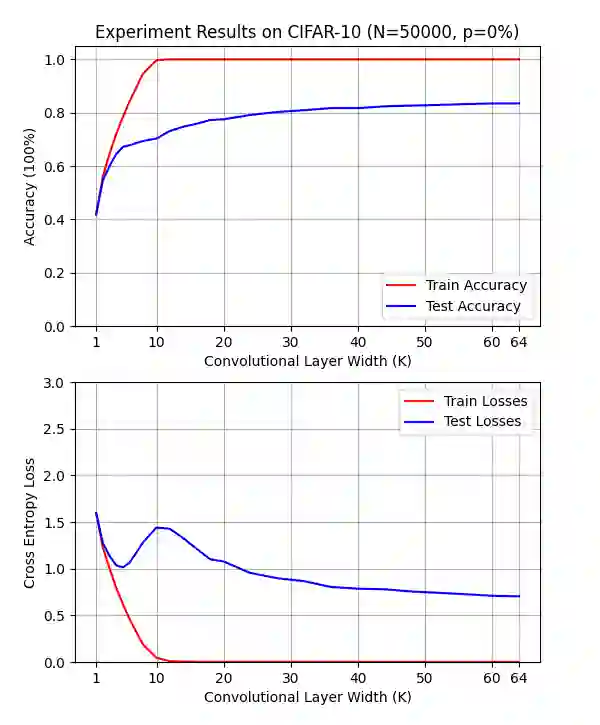
Double descent presents a counter-intuitive aspect within the machine learning domain, and researchers have observed its manifestation in various models and tasks. While some theoretical explanations have been proposed for this phenomenon in specific contexts, an accepted theory to account for its occurrence in deep learning remains yet to be established. In this study, we revisit the phenomenon of double descent and demonstrate that its occurrence is strongly influenced by the presence of noisy data. Through conducting a comprehensive analysis of the feature space of learned representations, we unveil that double descent arises in imperfect models trained with noisy data. We argue that double descent is a consequence of the model first learning the noisy data until interpolation and then adding implicit regularization via over-parameterization acquiring therefore capability to separate the information from the noise. We postulate that double descent should never occur in well-regularized models.
翻译:双重下降呈现了机器学习领域中反直觉的一面,研究人员已在多种模型和任务中观察到其表现。尽管已有一些针对特定场景的理论解释,但能解释深度学习中出现这一现象的公认理论尚未建立。本研究重新审视双重下降现象,证明其出现与噪声数据的存在密切相关。通过对学习表征的特征空间进行综合分析,我们揭示了双重下降源于使用噪声数据训练的不完美模型。我们认为双重下降是模型先学习噪声数据直至插值,再通过过参数化引入隐式正则化,从而获得分离信息与噪声能力的结果。我们推测,在良好正则化的模型中,双重下降现象永远不会发生。