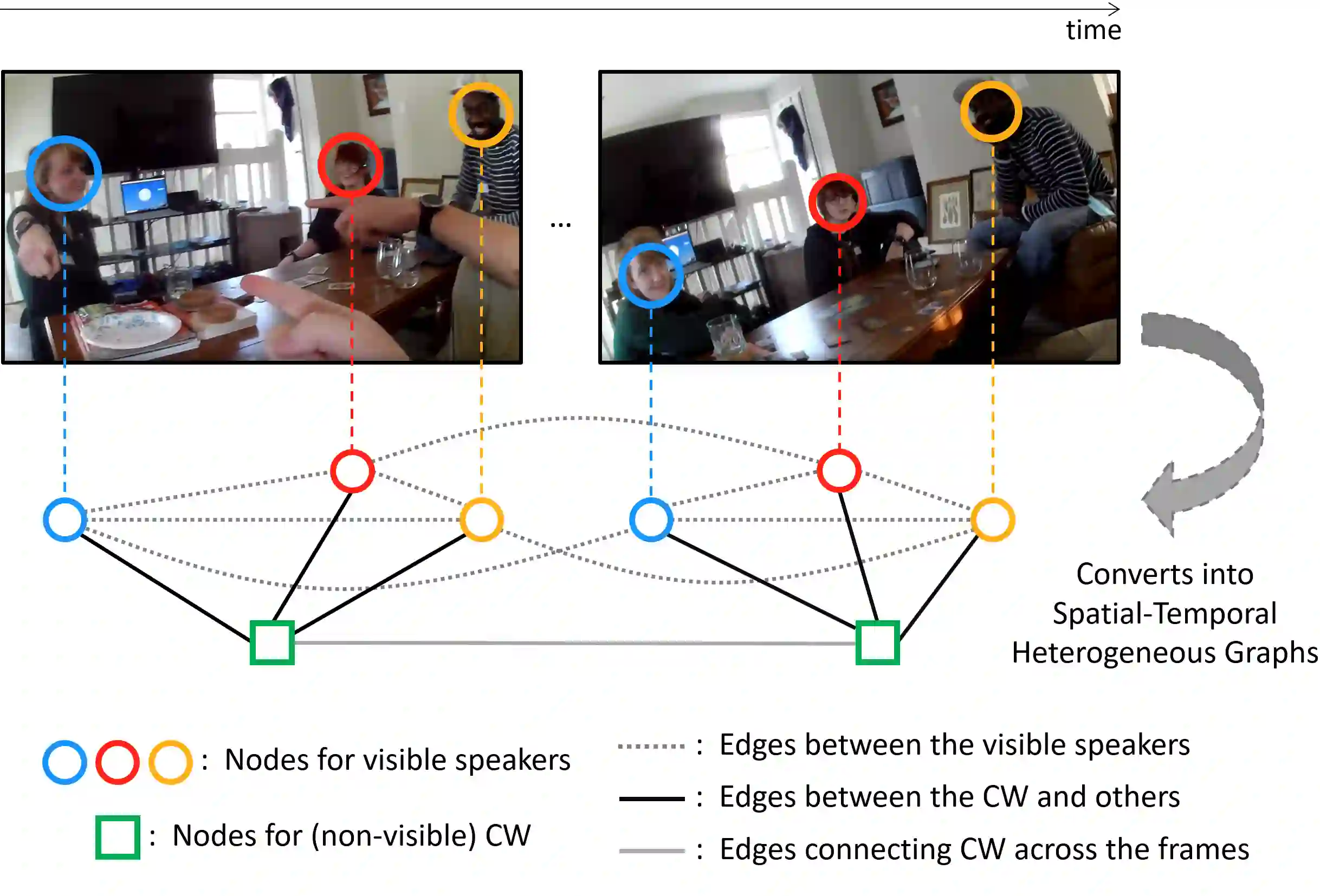
This report introduces our novel method named STHG for the Audio-Visual Diarization task of the Ego4D Challenge 2023. Our key innovation is that we model all the speakers in a video using a single, unified heterogeneous graph learning framework. Unlike previous approaches that require a separate component solely for the camera wearer, STHG can jointly detect the speech activities of all people including the camera wearer. Our final method obtains 61.1% DER on the test set of Ego4D, which significantly outperforms all the baselines as well as last year's winner. Our submission achieved 1st place in the Ego4D Challenge 2023. We additionally demonstrate that applying the off-the-shelf speech recognition system to the diarized speech segments by STHG produces a competitive performance on the Speech Transcription task of this challenge.
翻译:本报告介绍了我们针对Ego4D 2023挑战赛视听说话人分割任务提出的创新方法STHG。我们的核心创新点在于,利用单一统一的异构图学习框架对视频中所有说话人进行建模。不同于以往需要为佩戴摄像机者单独设置模块的方法,STHG能够联合检测包括佩戴摄像机者在内的所有人的语音活动。最终方法在Ego4D测试集上取得了61.1%的DER(说话人错误率),显著优于所有基线模型及去年冠军方案。本方案在Ego4D 2023挑战赛中荣获第一名。我们还证明,将现成的语音识别系统应用于STHG分割后的语音片段,可在该挑战赛的语音转录任务中取得具有竞争力的性能。