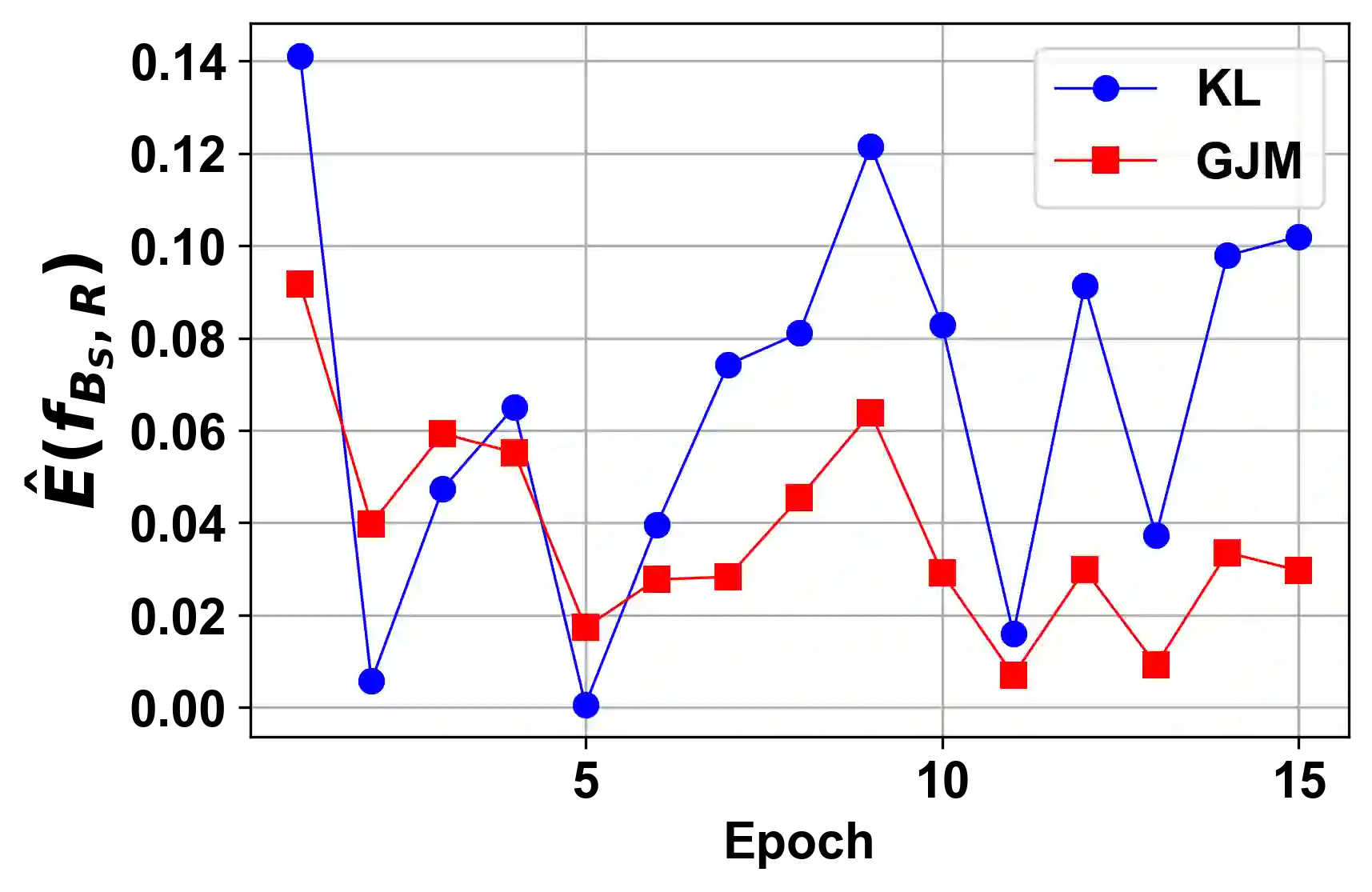
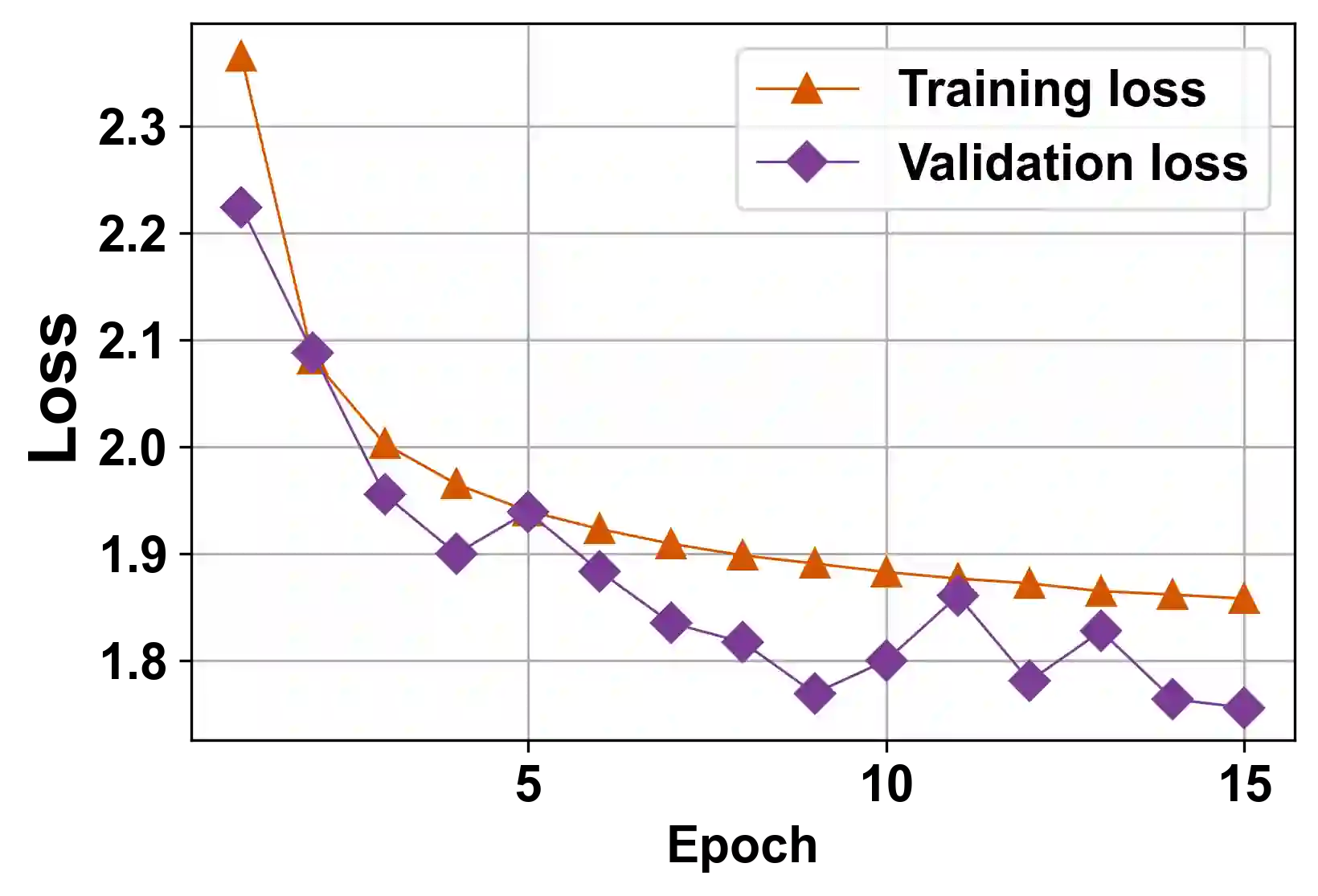
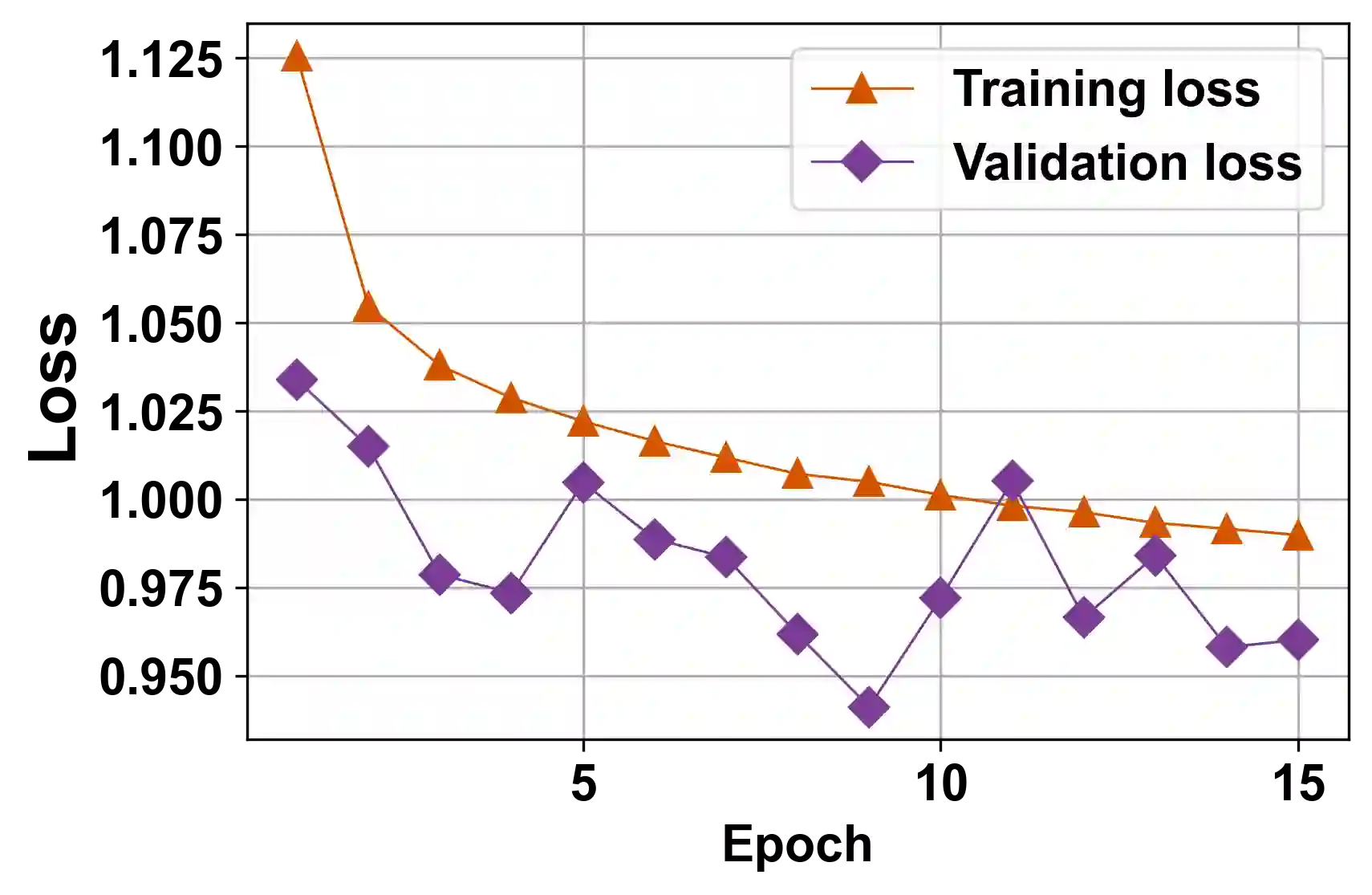
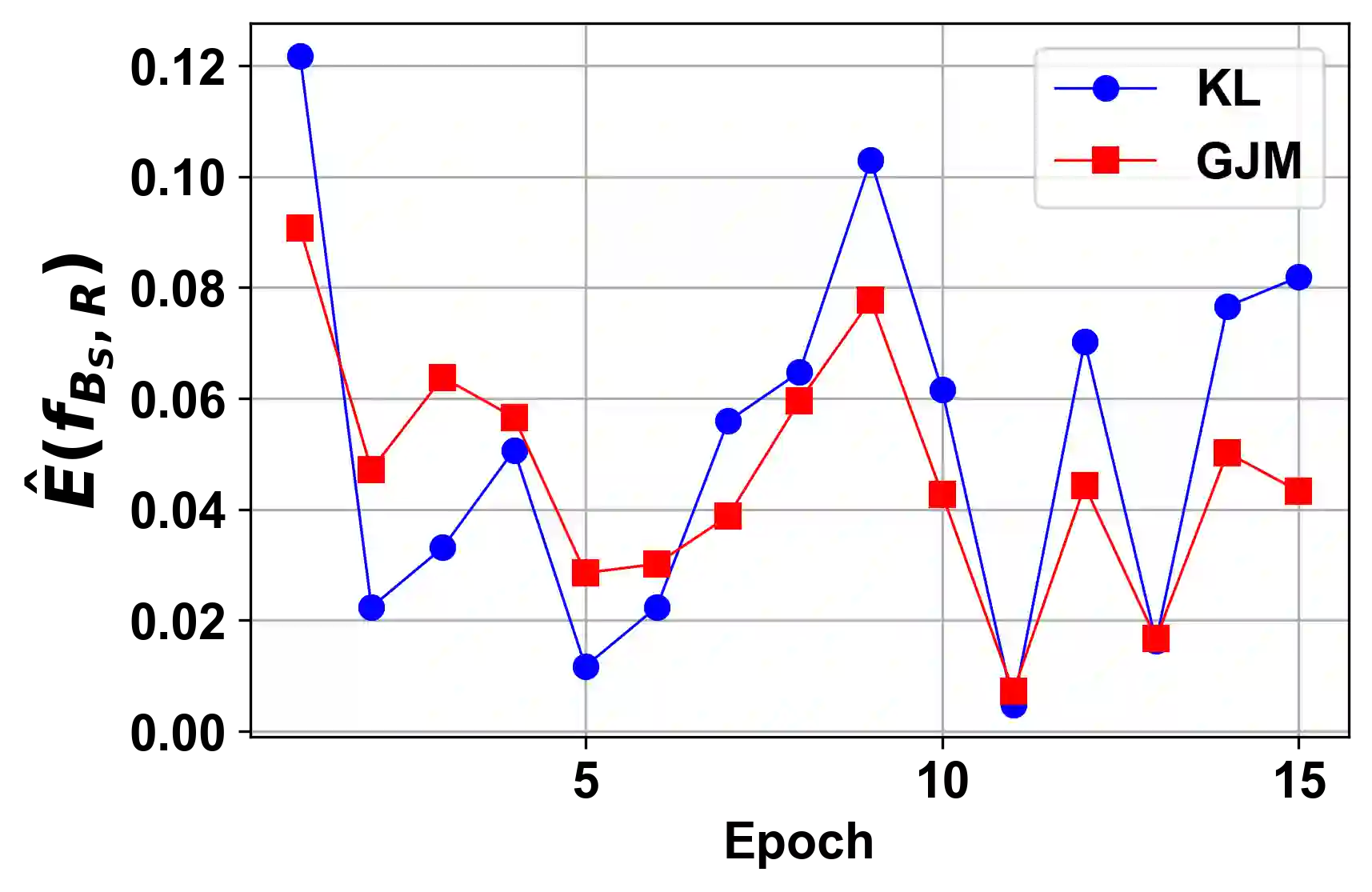
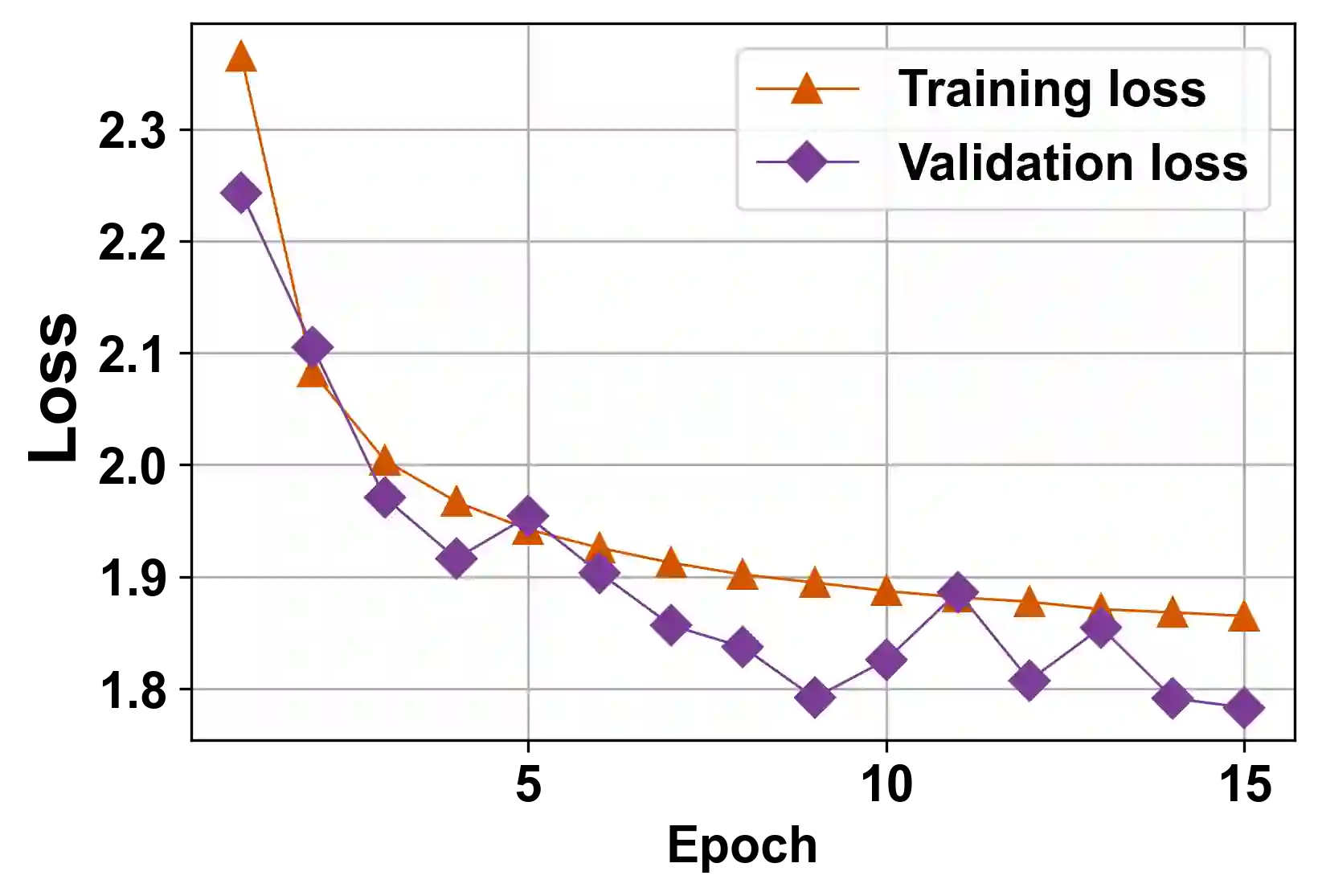
The generalization performance of deep neural networks with regard to the optimization algorithm is one of the major concerns in machine learning. This performance can be affected by various factors. In this paper, we theoretically prove that the Lipschitz constant of a loss function is an important factor to diminish the generalization error of the output model obtained by Adam or AdamW. The results can be used as a guideline for choosing the loss function when the optimization algorithm is Adam or AdamW. In addition, to evaluate the theoretical bound in a practical setting, we choose the human age estimation problem in computer vision. For assessing the generalization better, the training and test datasets are drawn from different distributions. Our experimental evaluation shows that the loss function with a lower Lipschitz constant and maximum value improves the generalization of the model trained by Adam or AdamW.
翻译:深度神经网络的泛化性能与优化算法的关系是机器学习领域的重要课题之一,这种性能受到多种因素的影响。本文从理论上证明,损失函数的Lipschitz常数是降低Adam或AdamW优化器所得输出模型泛化误差的关键因素。研究结果可为采用Adam或AdamW优化算法时选择损失函数提供指导。此外,为评估理论界在实践中的适用性,我们选取了计算机视觉中的人体年龄估计问题。为更有效评估泛化能力,训练集与测试集采用不同分布。实验结果表明,具有较低Lipschitz常数和最大值的损失函数能够改善Adam或AdamW训练模型的泛化性能。