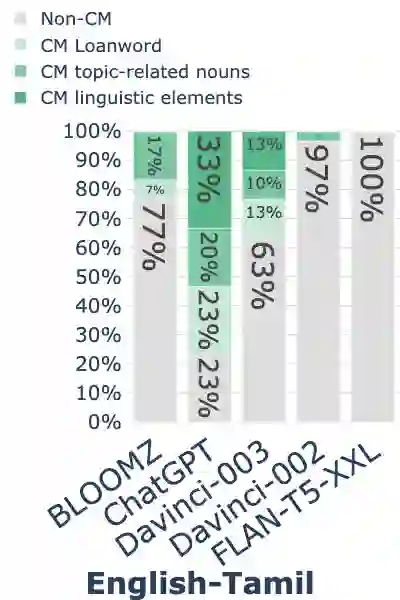
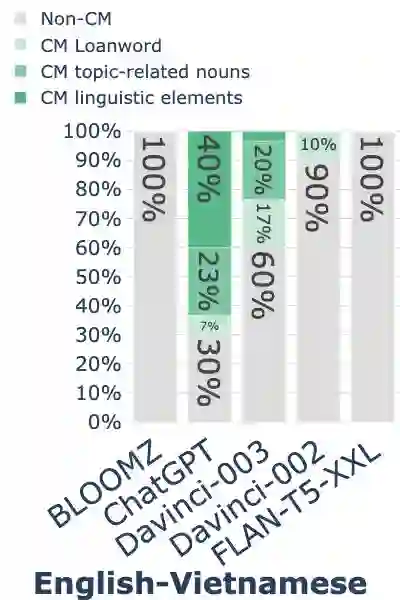
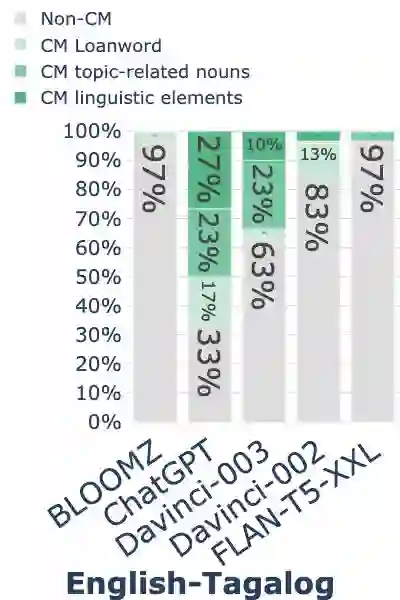
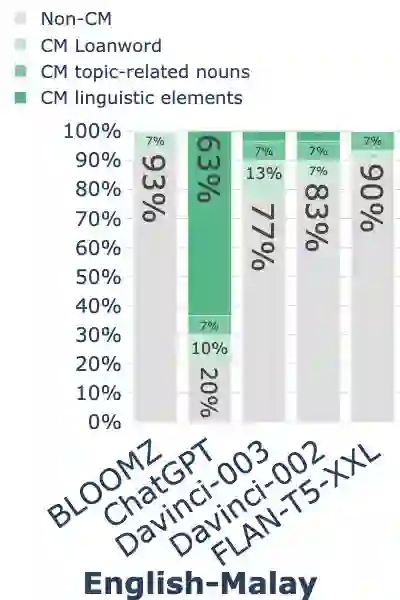
While code-mixing is a common linguistic practice in many parts of the world, collecting high-quality and low-cost code-mixed data remains a challenge for natural language processing (NLP) research. The recent proliferation of Large Language Models (LLMs) compels one to ask: how capable are these systems in generating code-mixed data? In this paper, we explore prompting multilingual LLMs in a zero-shot manner to generate code-mixed data for seven languages in South East Asia (SEA), namely Indonesian, Malay, Chinese, Tagalog, Vietnamese, Tamil, and Singlish. We find that publicly available multilingual instruction-tuned models such as BLOOMZ and Flan-T5-XXL are incapable of producing texts with phrases or clauses from different languages. ChatGPT exhibits inconsistent capabilities in generating code-mixed texts, wherein its performance varies depending on the prompt template and language pairing. For instance, ChatGPT generates fluent and natural Singlish texts (an English-based creole spoken in Singapore), but for English-Tamil language pair, the system mostly produces grammatically incorrect or semantically meaningless utterances. Furthermore, it may erroneously introduce languages not specified in the prompt. Based on our investigation, existing multilingual LLMs exhibit a wide range of proficiency in code-mixed data generation for SEA languages. As such, we advise against using LLMs in this context without extensive human checks.
翻译:虽然混合语码是世界许多地区的常见语言实践,但获取高质量、低成本的混合语码数据对于自然语言处理(NLP)研究仍然是一个挑战。近年来大语言模型(LLMs)的激增促使我们提出疑问:这些系统在生成混合语码数据方面的能力如何?本文探索了以零样本方式引导多语言LLMs生成七种东南亚(SEA)语言(即印尼语、马来语、中文、他加禄语、越南语、泰米尔语和新加式英语)的混合语码数据。我们发现,公开可用的多语言指令调优模型(如BLOOMZ和Flan-T5-XXL)无法生成包含不同语言短语或从句的文本。ChatGPT在生成混合语码文本方面表现出不一致的能力,其性能取决于提示模板和语言配对。例如,ChatGPT能生成流畅自然的Singlish文本(新加坡使用的基于英语的克里奥尔语),但对于英语-泰米尔语语言对,系统主要生成语法错误或语义无意义的语句。此外,它可能错误地引入提示中未指定的语言。基于我们的研究,现有的多语言LLMs在SEA语言的混合语码数据生成方面表现出广泛的熟练程度差异。因此,我们建议在此背景下使用LLMs时需进行广泛的人工核验。