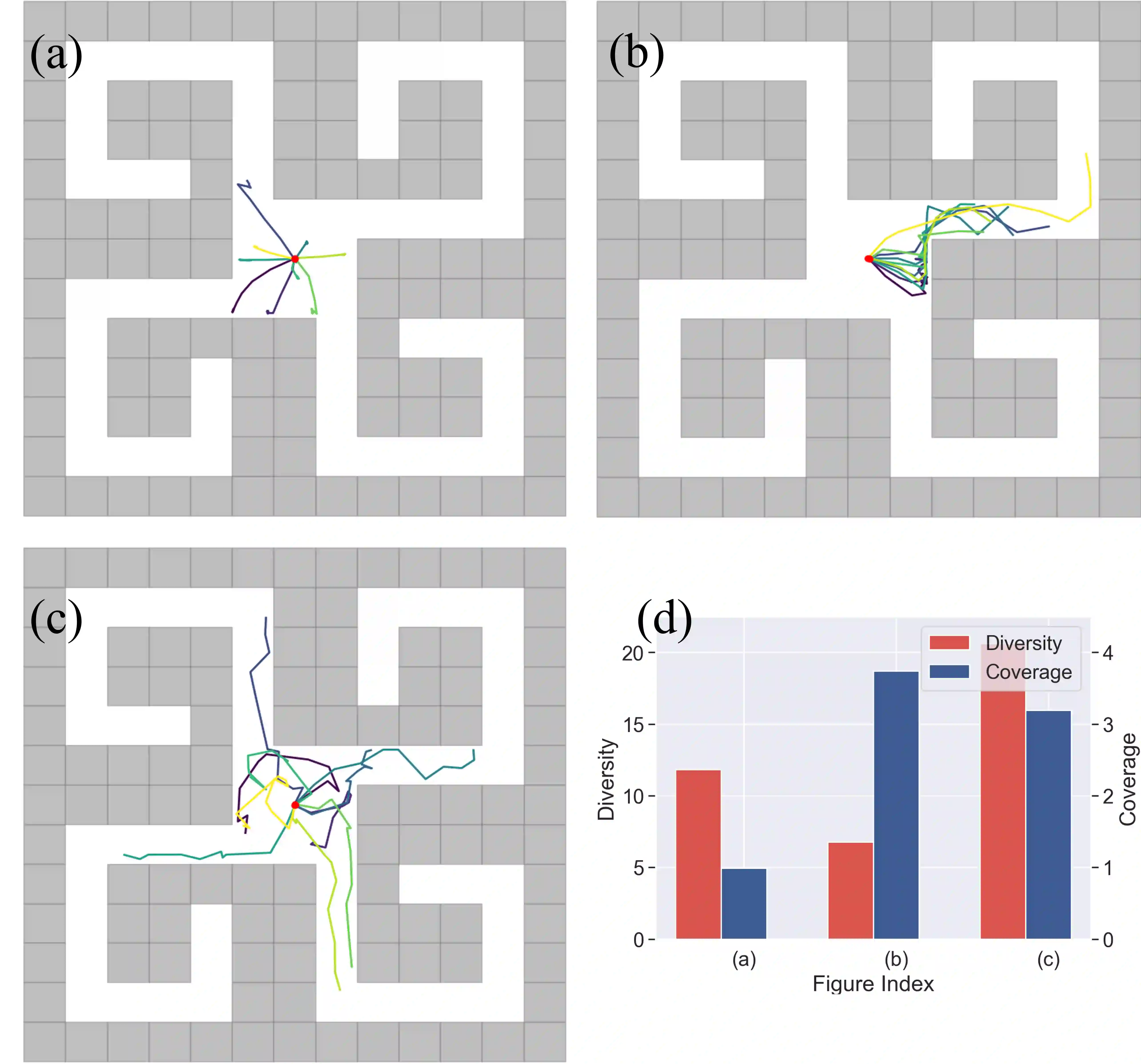
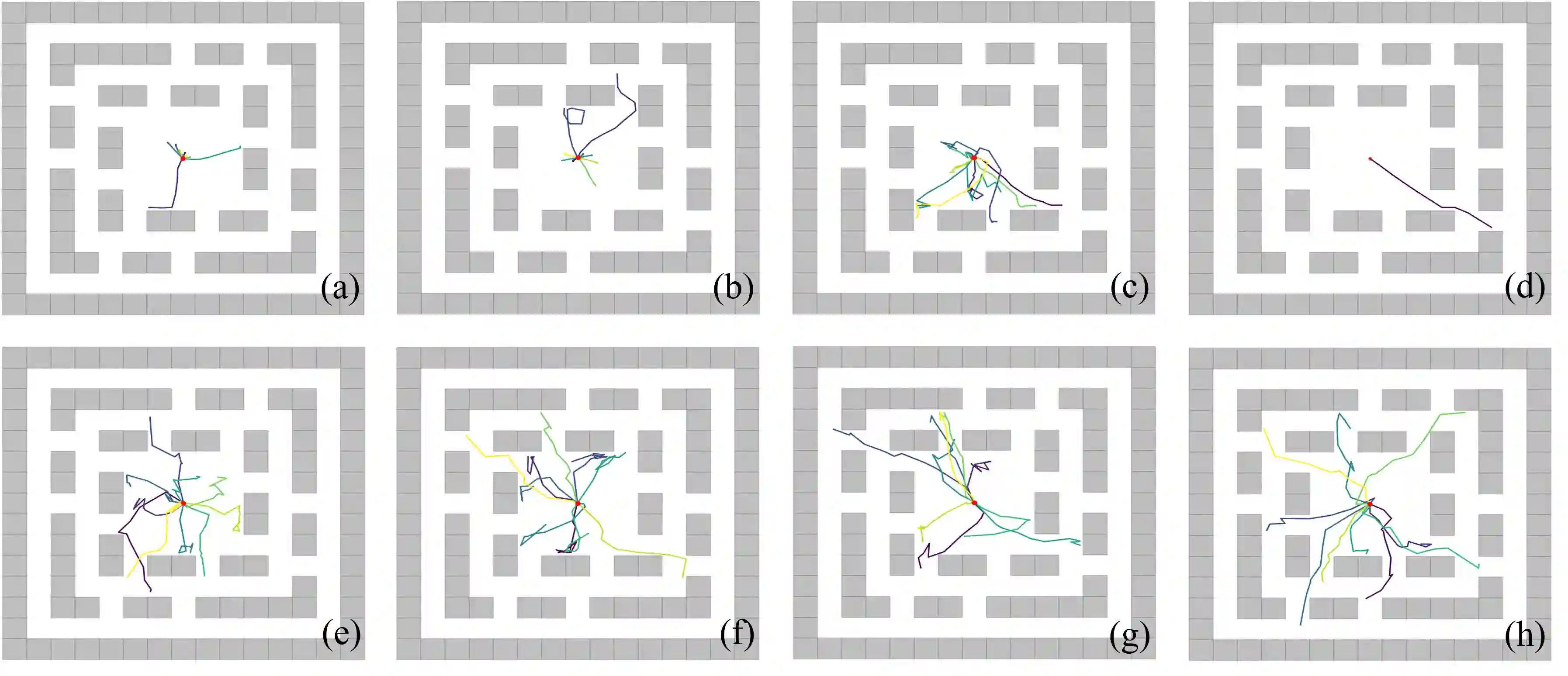
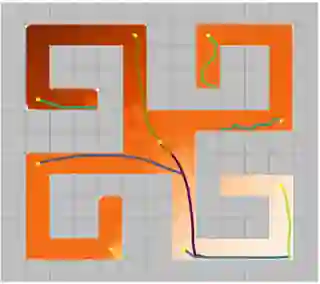
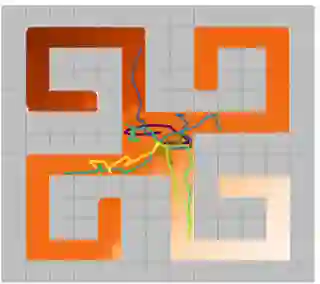Learning rich skills through temporal abstractions without supervision of external rewards is at the frontier of Reinforcement Learning research. Existing works mainly fall into two distinctive categories: variational and Laplacian-based skill (a.k.a., option) discovery. The former maximizes the diversity of the discovered options through a mutual information loss but overlooks coverage of the state space, while the latter focuses on improving the coverage of options by increasing connectivity during exploration, but does not consider diversity. In this paper, we propose a unified framework that quantifies diversity and coverage through a novel use of the Determinantal Point Process (DPP) and enables unsupervised option discovery explicitly optimizing both objectives. Specifically, we define the DPP kernel matrix with the Laplacian spectrum of the state transition graph and use the expected mode number in the trajectories as the objective to capture and enhance both diversity and coverage of the learned options. The proposed option discovery algorithm is extensively evaluated using challenging tasks built with Mujoco and Atari, demonstrating that our proposed algorithm substantially outperforms SOTA baselines from both diversity- and coverage-driven categories. The codes are available at https://github.com/LucasCJYSDL/ODPP.
翻译:通过时间抽象学习丰富的技能而不依赖外部奖励的监督,是强化学习研究的前沿方向。现有工作主要分为两大类别:变分法和基于拉普拉斯的技能(即选项)发现。前者通过互信息损失最大化所发现选项的多样性,但忽视了状态空间的覆盖性;后者则通过在探索过程中增加连通性来提升选项的覆盖性,但未考虑多样性。本文提出一个统一框架,通过创新性地运用行列式点过程(DPP)量化多样性与覆盖性,并实现在无监督选项发现中显式优化这两个目标。具体而言,我们利用状态转移图的拉普拉斯谱定义DPP核矩阵,将轨迹中的期望模态数作为目标函数,以捕获并增强所学选项的多样性与覆盖性。通过使用Mujoco和Atari构建的具有挑战性的任务对所提出的选项发现算法进行广泛评估,结果表明,我们的算法在多样性与覆盖性驱动的两类方法中均显著优于现有最优基线。代码开源于https://github.com/LucasCJYSDL/ODPP。