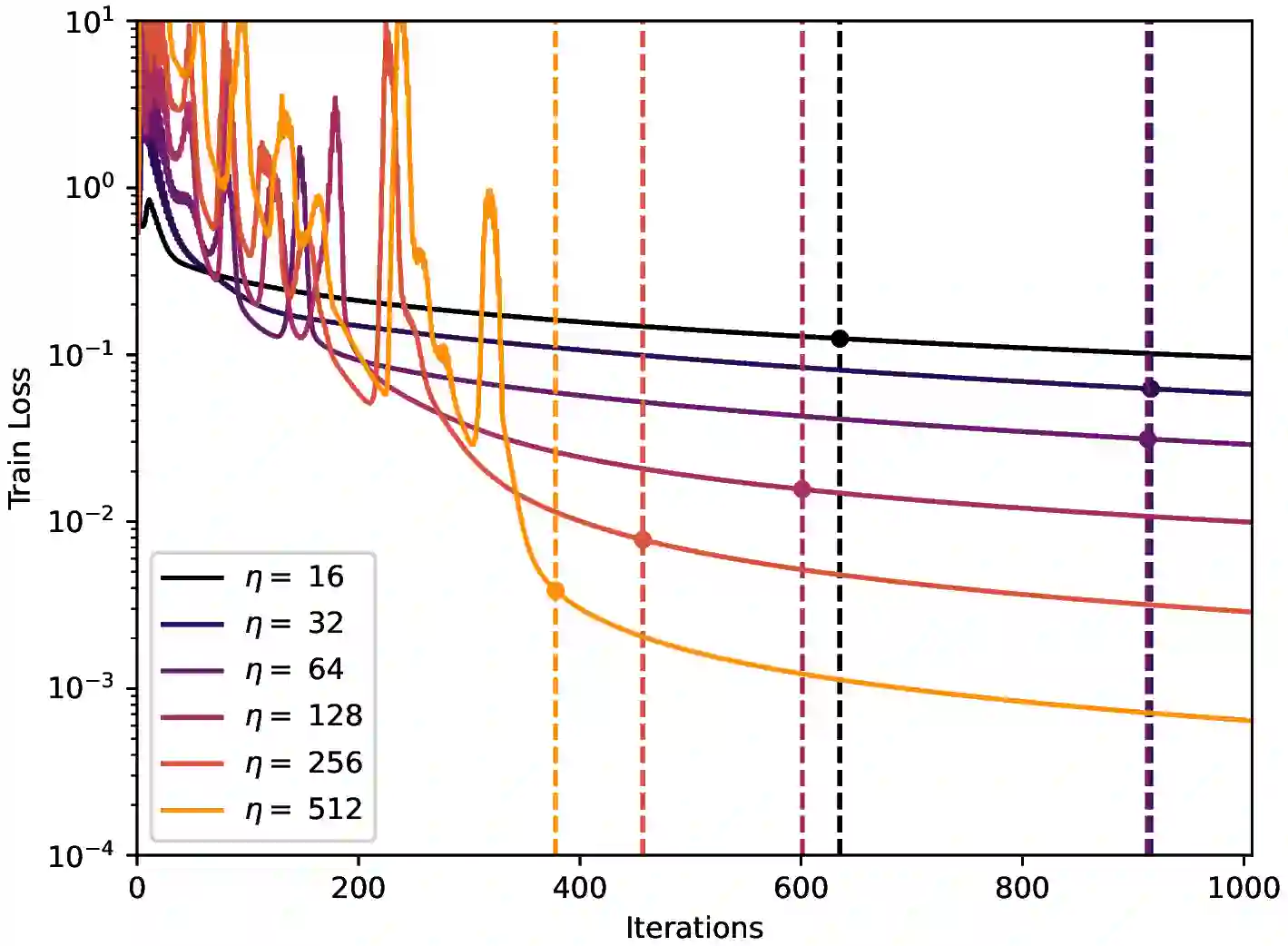
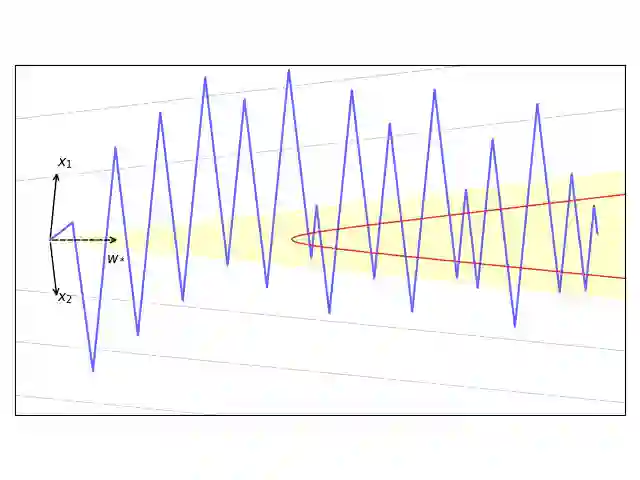
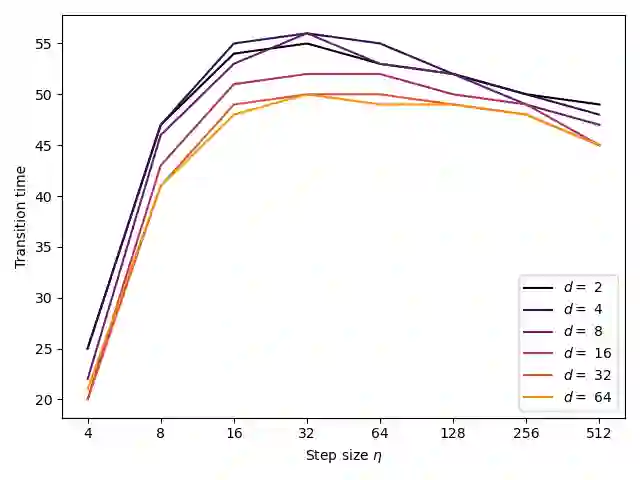
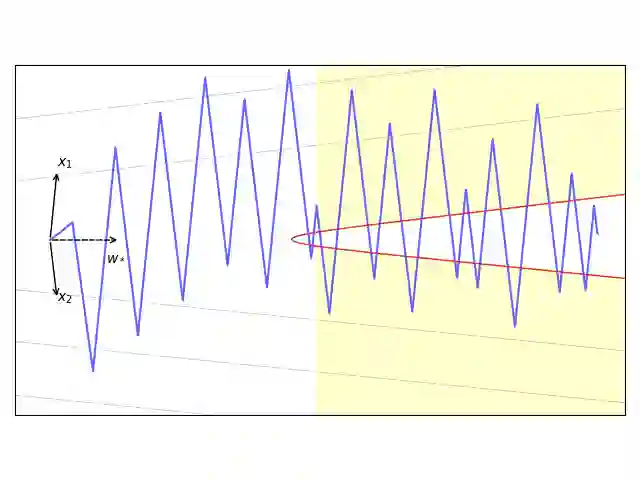
We consider the optimization problem of minimizing the logistic loss with gradient descent to train a linear model for binary classification with separable data. With a budget of $T$ iterations, it was recently shown that an accelerated $1/T^2$ rate is possible by choosing a large stepsize $η= Θ(γ^2 T)$ (where $γ$ is the dataset's margin) despite the resulting non-monotonicity of the loss. In this paper, we provide a tighter analysis of gradient descent for this problem when the data is two-dimensional: we show that GD with a sufficiently large learning rate $η$ finds a point with loss smaller than $\mathcal{O}(1/(ηγ^2 T))$, as long as $T \geq Ω(n/γ+ 1/γ^2)$, where $n$ is the dataset size. Our improved rate comes from a tighter bound on the time $τ$ that it takes for GD to transition from unstable (non-monotonic loss) to stable (monotonic loss), via a fine-grained analysis of the oscillatory dynamics of GD in the subspace orthogonal to the max-margin classifier. We also provide a lower bound of $τ$ matching our upper bound up to logarithmic factors, showing that our analysis is tight.
翻译:考虑使用梯度下降最小化逻辑损失,以训练用于可分离数据二分类的线性模型的优化问题。在总迭代次数 $T$ 的预算下,近期研究表明,通过选择大步长 $η= Θ(γ^2 T)$(其中 $γ$ 为数据集的间隔),尽管损失呈现非单调性,仍可实现加速的 $1/T^2$ 收敛速率。本文针对二维数据情形,给出了该问题下梯度下降的更紧致分析:我们证明,当学习率 $η$ 足够大且满足 $T \geq Ω(n/γ+ 1/γ^2)$($n$ 为数据集规模)时,梯度下降可找到损失小于 $\mathcal{O}(1/(ηγ^2 T))$ 的点。这一改进的收敛速率源于对梯度下降从非稳态(损失非单调)过渡到稳态(损失单调)所需时间 $τ$ 的更紧上界估计,其核心是对最大间隔分类器正交子空间中梯度下降振荡动力学的精细化分析。同时,我们给出了 $τ$ 的下界,该下界与上界相差至多对数因子,从而证明了分析的紧致性。