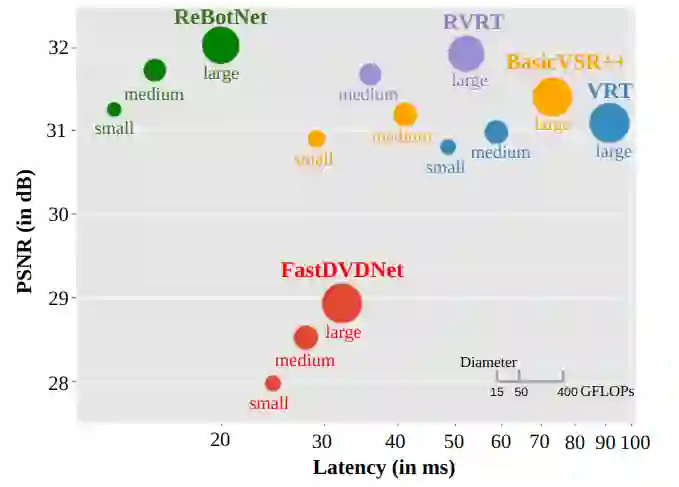
Most video restoration networks are slow, have high computational load, and can't be used for real-time video enhancement. In this work, we design an efficient and fast framework to perform real-time video enhancement for practical use-cases like live video calls and video streams. Our proposed method, called Recurrent Bottleneck Mixer Network (ReBotNet), employs a dual-branch framework. The first branch learns spatio-temporal features by tokenizing the input frames along the spatial and temporal dimensions using a ConvNext-based encoder and processing these abstract tokens using a bottleneck mixer. To further improve temporal consistency, the second branch employs a mixer directly on tokens extracted from individual frames. A common decoder then merges the features form the two branches to predict the enhanced frame. In addition, we propose a recurrent training approach where the last frame's prediction is leveraged to efficiently enhance the current frame while improving temporal consistency. To evaluate our method, we curate two new datasets that emulate real-world video call and streaming scenarios, and show extensive results on multiple datasets where ReBotNet outperforms existing approaches with lower computations, reduced memory requirements, and faster inference time.
翻译:大多数视频恢复网络速度慢、计算负载高,无法用于实时视频增强。在这项工作中,我们设计了一个高效且快速的框架,用于实际场景(如实时视频通话和视频流)中的实时视频增强。我们提出的方法称为循环瓶颈混合器网络(ReBotNet),采用双分支架构。第一个分支通过使用基于ConvNext的编码器将输入帧沿空间和时间维度进行令牌化,并利用瓶颈混合器处理这些抽象令牌,从而学习时空特征。为进一步提升时间一致性,第二个分支直接在从单个帧中提取的令牌上应用混合器。随后,一个公共解码器合并两个分支的特征,以预测增强后的帧。此外,我们提出了一种循环训练方法,利用前一帧的预测结果高效地增强当前帧,同时改善时间一致性。为评估我们的方法,我们整理了两个模拟真实视频通话和流媒体场景的新数据集,并在多个数据集上展示了广泛的结果:ReBotNet在计算量更低、内存需求更少、推理速度更快的情况下,优于现有方法。